
본 글에서는 DETR(ECCV 2020)의 bipartite matching 기반 학습 과정에서 발생하는 수렴 속도 문제를 개선하기 위해 제안된 DN-DETR(CVPR 2022)을 살펴본다.
1. Introduction
2020년 제안된 DETR은 기존 객체 탐지 파이프라인에서 필수적으로 사용되던 anchor 설계, proposal 생성, NMS 등의 복잡성을 제거하고, 객체 탐지를 end-to-end 방식으로 최적화한 모델이다.
[ ⚠️ DETR의 한계 ] - 느린 학습 수렴 속도
그러나 이 구조적 단순성에도 불구하고, DETR은 기존 CNN 기반 탐지기들에 비해 학습 수렴 속도가 현저히 느리다는 한계를 가진다.
예를 들어, COCO detection dataset에서 기존 Faster R-CNN이 약 12 epoch 내에 도달하는 성능 수준에 도달하기 위해, DETR은 최대 500 epoch의 학습이 필요하다.
논문은 이러한 느린 수렴의 원인 중 하나로 bipartite graph matching(Hungarian matching)을 지적한다.
(Conditional DETR, Deformable DETR, Anchor DETR, DAB-DETR 등 다양한 DETR 개선 연구들이 제안되었지만, 이들 대부분은 bipartite matching 자체의 불안정성에는 주목하지 않았다.)
구체적으로, 학습 초반에는 예측된 바운딩 박스가 매우 불안정하기 때문에 bipartite matching은 사실상 무작위로 수행될 수 밖에 없다. 그 결과, 동일한 객체에 대해 매 epoch마다 서로 다른 object query가 매칭되며, 모델은 일관된 학습 신호를 받지 못한다. 이러한 특성으로 인해 최적화 과정이 더욱 어려워지고, 학습에 많은 반복이 요구된다.
(예를 들어, 한 epoch에서는 object query 34번이 특정 고양이 객체와 매칭되었다가, 다음 epoch에서는 동일한 고양이 객체가 object query 78번과 매칭되는 현상이 발생할 수 있다.)
논문은 이러한 현상을 stochastic optimization 과정에서의 초기 불안정성으로 해석하며, 이것이 DETR의 느린 학습 수렴의 주요 요인 중 하나라고 분석한다.
[ ‼️ DN-DETR의 제안 ] - 학습 보조 task, Query Denoising
문제를 해결하기 위해, 논문은 학습 과정에서 bipartate matching을 안정화할 수 있는 보조 task로서 Query Denoising을 도입한다.
간단히 요약하자면, 학습 시 노이즈가 추가된 GT bounding box를 denoising query로 생성하고, 이를 기존의 learnable anchor queries(= object quries)와 함께 Transformer decoder에 입력한다
노이즈가 추가된 denoising query에 대해서는 GT bounding box와 class label을 복원하는 denoising task를 수행하고, 기존 anchor queries(= object quries)에 대해서는 vanilla DETR과 동일하게 bipartite matching 기반 Hungarian loss를 적용한다. 중요한 점은, denoising query는 bipartite matching을 거치지 않기 때문에 초기 학습 단계에서도 안정적인 감독 신호를 제공하는 쉬운 보조 태스크로 작동한다는 것이다.
다시 한 번 쉽게 정리해보면
- 기존 bipartite matching 기반 학습에서는 모델이 anchor queries(= object queries)와 예측된 bounding box 간의 정답 대응 관계를 학습해야 한다. 그러나 이 과정에서는 각 query에 대해 명확한 정답이 주어지지 않기 때문에, 최적의 대응 관계를 찾기 위해 많은 반복 학습이 필요하다.
- 근데 새롭게 제안된 query denoising에서는 denoising query를 GT로 되돌리기만 하면 되는, 즉 GT 복원이라는 명확하고 일관된 정답이 있기 때문에 모델은 bounding box를 조절하는 법을 빠르게 터득할 수 있다.

또한, 각 denoising query를 bounding box 임베딩과 class label 임베딩의 결합으로 해석함으로써, 논문은 box denoising과 label denoising을 동시에 수행할 수 있도록 설계한다. 이 훈련 방식은 초기 단계에서 불안정한 bipartite matching의 영향을 완화하고, bounding box 예측을 더 빠르게 학습하도록 돕는다.


DN-DETR은 전체 손실 함수를 reconstruction loss(denoising)와 Hungarian loss(matching)의 두 부분으로 구성한 디노이징 기반 훈련 전략을 제안한다. 이 방법은 DETR의 구조 자체를 변경하지 않으며, 기존 DETR 계열 모델에 plug-and-play 방식으로 쉽게 적용 가능하다.
[ ⭐️ DN-DETR의 Contributions ]
본 논문의 주요 기여는 다음과 같다.
- DETR의 학습 수렴을 가속화하는 새로운 훈련 방법을 제안하고, 12-epoch 설정에서 기존 탐지기들 중 최고 성능을 달성함을 보였다.
- DETR의 느린 수렴 원인을 bipartite matching의 불안정성 관점에서 분석하고, 이를 정량화하는 지표를 제안하였다.
- 노이즈 크기, 레이블 디노이징, attention mask 등의 효과를 분석하는 체계적인 ablation study를 수행하였다.
2. Related Work
2.1 Classical CNN Detectors
기존 객체 탐지 모델들은 대부분 2단계로 나뉘어 region proposal을 생성한 뒤 각 영역에 대해 분류 및 bounding box 회귀를 수행한다.
이러한 방법들은 높은 성능을 보였지만, anchor 설계에 민감하고 NMS 및 레이블 할당과 같은 인간 개입이 필요한 규칙에 의존한다는 한계를 가진다. 이로 인해 완전한 end-to-end 최적화가 어렵다.
2.2 DETR-based Detectors
DETR은 학습 수렴이 매우 느리다는 치명적인 단점을 가지며, COCO 기준으로도 좋은 성능을 얻기 위해 수백 epoch의 학습이 필요하다.
이후 많은 연구들이 DETR의 수렴 속도를 개선하기 위해 제안되었지만, 대부분은 Hungarian loss에 사용되는 bipartite matching의 불안정성을 느린 수렴의 핵심 원인으로 다루지 않았다.
이 연구는 DAB-DETR을 베이스라인으로 하고, Hungarian loss 외에 GT 복원을 목표로 하는 denoising loss를 보조 태스크로 추가한다. 이는 bipartite matching을 우회하여, 학습 초기에도 안정적인 감독 신호를 제공한다는 점에서 기존 방법들과 본질적으로 다르다.
이후 DINO, Mask DINO, Group DETR, SAMDETR++ 등 다수의 최신 탐지 및 분할 모델들이 본 논문의 denoising 학습 전략을 채택하거나 확장하였으며, 이는 새롭게 제안한 방법의 효과와 일반화 가능성을 뒷받침한다.
3. Why Denoising Accelerates DETR Training?
3.1 Stablize Hungarian Mathcing
Hungarian matching은 cost matrix에 기반해 최적의 매칭을 찾는 알고리즘으로, DETR은 이를 객체 탐지에 처음으로 도입해 예측 객체와 ground-truth 객체 간의 대응 관계를 동적으로 학습한다.
하지만 이산적인 bipartite matching과 확률적 학습이 결합되면서, cost의 미세한 변화만으로도 매칭 결과가 크게 달라지는 불안정성이 발생한다. 이로 인해 decoder queries는 매 epoch마다 서로 다른 최적화 목표를 가지게 되어 학습 수렴이 느려진다.
논문은 DETR 학습을 anchor query를 학습하는 단계와 상대적 offset을 학습하는 단계로 해석한다. 이때 anchor 업데이트가 불안정하면 offset 학습 또한 어려워진다. DN-DETR에서는 denoising이 bipartite matching을 우회하여, GT 근처에 위치한 noised query로부터 bounding box를 직접 복원하도록 학습한다. 이 과정은 명확한 최적화 목표를 제공하며, Hungarian matching으로 인해 발생하는 할당의 모호함을 효과적으로 완화한다.
나아가 이 논문에서는 bipartite matching의 instability를 정량적으로 평가하기 위한 metric, IS를 설계했다. (i는 i-th epoch)

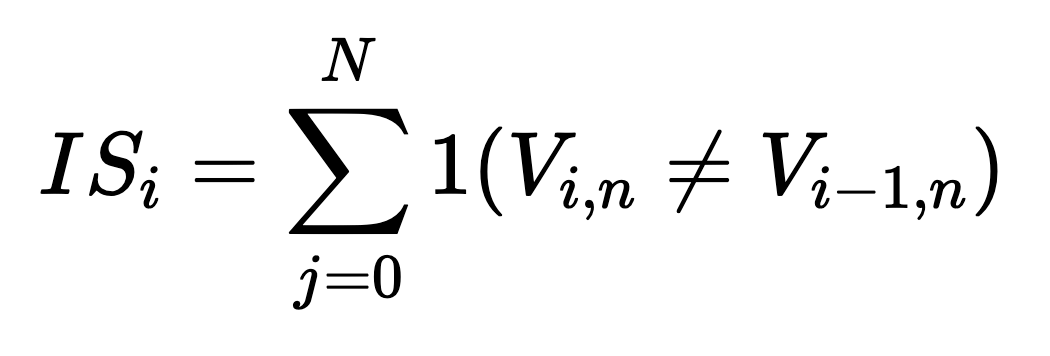

Vanilla DETR, 베이스라인 DAB-DETR과 논문에서 제안한 DN-DETR 의 IS를 계산해 비교한 그래프는 아래와 같다.
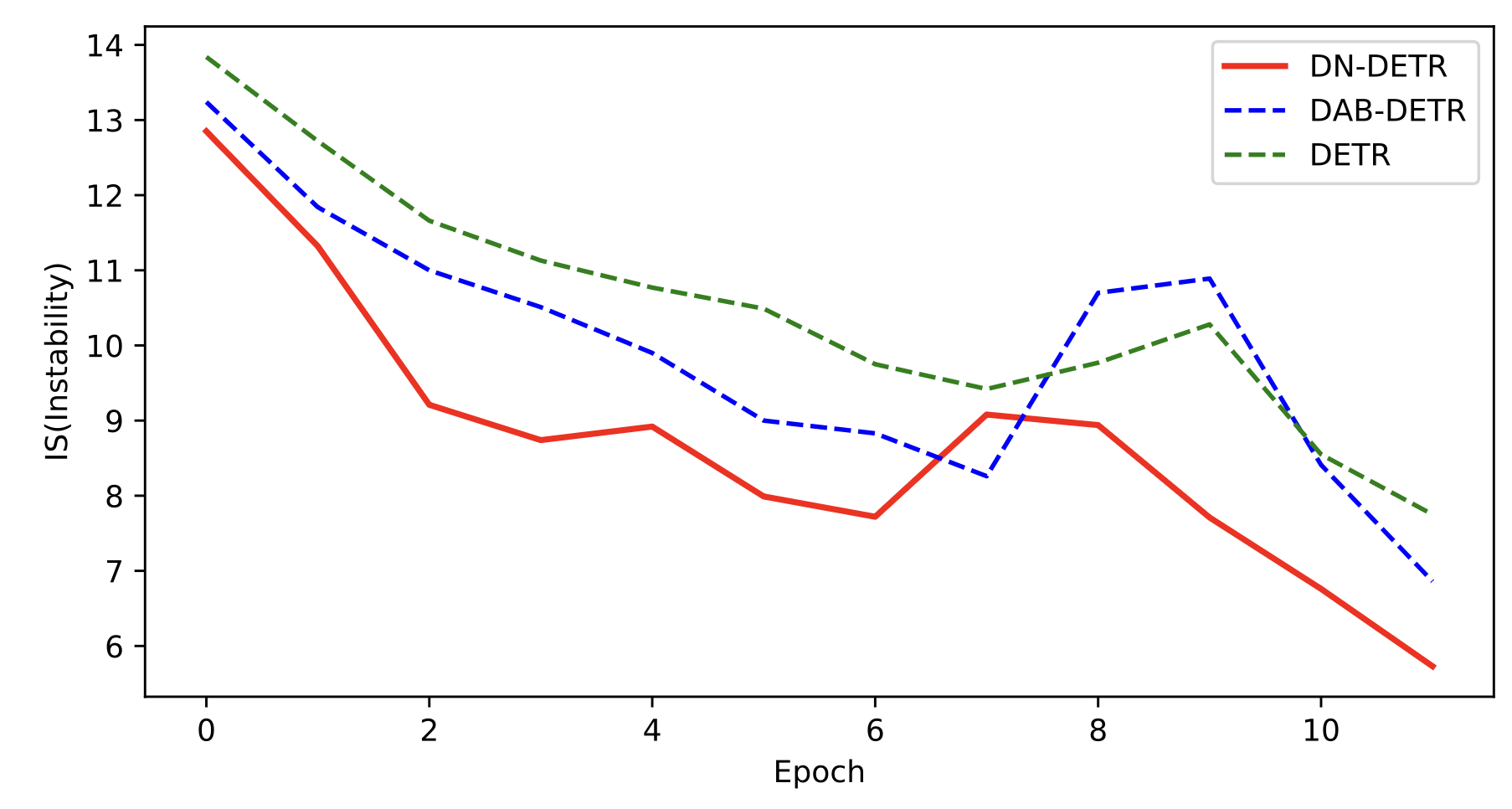
3.2 Make Query Search More Locally
DN-DETR은 denoising 학습을 통해 anchor query와 대응하는 target 사이의 거리를 줄임으로써 학습의 효율을 높인다.
기존 DETR에서는 positional query가 여러 작동 모드를 가지며, 이로 인해 예측을 위해 넓은 공간에서 쿼리 탐색이 이루어진다.
반면, DN-DETR에서는 GT 근처에 위치한 noised box로부터 원래의 bounding box를 복원하도록 학습하기 때문에, 각 query는 자신과 가까운 영역에 집중하여 예측을 수행하게 된다. 이로 인해 쿼리 탐색이 국소화되며, 쿼리 간의 예측 충돌 가능성이 감소한다.
실험적으로도 DN-DETR은 DAB-DETR 대비 초기 anchor와 매칭된 GT box 간의 평균 거리(L1)가 더 짧음을 보이며, 이는 학습 난이도를 낮추고 더 빠른 수렴으로 이어진다.

4. DN-DETR

논문은 DAB-DETR을 기본 탐지 아키텍처로 사용하며, decoder query를 4D bounding box로 명시적으로 공식화하는 기존 설계를 따른다. 구조적인 차이는 label denoising을 지원하기 위해 decoder embedding에 class label embedding을 포함시킨 점뿐이다.
본 논문의 핵심 기여는 모델 구조가 아니라, denoising task를 포함한 새로운 훈련 방법이다.
DN-DETR의 전체 구조는 DETR과 동일한 Transformer encoder–decoder 구조를 따른다.
인코더에서는 CNN backbone으로부터 추출한 이미지 특징에 positional encoding을 더해 Transformer encoder에 입력하고, 이를 통해 전역적으로 정제된 이미지 특징을 얻는다. 디코더에서는 여러 개의 query가 입력되어 cross-attention을 통해 이미지 특징으로부터 객체를 탐색한다.
DN-DETR의 핵심은 디코더에 입력되는 query의 구성 방식이다.
디코더 query는 두 부분으로 나뉜다.
- Matching part
: 기존 DETR과 동일한 학습 가능한 anchor queries(object queries)로 구성되며, Hungarian matching을 통해 예측 결과와 GT 객체를 매칭하고 bounding box와 class label을 학습한다. - Denoising part
: GT bounding box와 label에 노이즈를 추가해 만든 denoising queries로 구성되며, bipartite matching을 거치지 않고 원래의 GT 객체를 복원하는 것을 목표로 한다.
두 종류의 query는 동일한 Transformer decoder에 함께 입력되지만, 비교적 쉬운 denoising 과정에서의 정보가 matching 과정에 영향을 미쳐 어려운 케이스의 학습이 일어나지 않는 것을 방지하기 위해 attention mask를 사용한다.
이를 통해 denoising query가 matching query에 영향을 주는 것을 차단하고 동일한 GT 객체에서 생성된 서로 다른 noised query 간의 상호 참조도 방지한다. 또한 denoising 효과를 높이기 위해, 하나의 GT 객체에 대해 여러 개의 노이즈 query를 생성하여 학습에 사용한다.
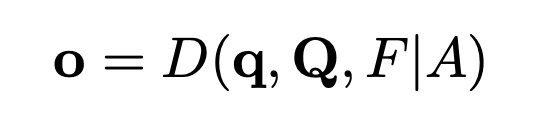
o: Transformer 디코더의 출력
q: denoising 부분 query
Q: matching 부분 query
F: Transformer 인코더의 refined 이미지 특징
A: Attention Mask
D: Transformer 디코더
[ Denoising 부분 ]
DN-DETR에서는 각 이미지에 포함된 모든 GT 객체에 대해, bounding box와 클래스 label 모두에 무작위 노이즈를 추가한 denoising query를 생성한다.
(위에서도 언급했지만, denoising 학습의 효과를 높이기 위해, 하나의 GT 객체로부터 여러 개의 노이즈 버전 query를 사용한다.)
bounding box에 대한 노이즈는 다음의 두 가지 방식으로 적용되며, 두 노이즈의 크기는 각각 하이퍼파라미터로 조절된다.
- Center Shifting
: 박스의 중심 좌표에 무작위 이동을 적용하되, 노이즈가 추가된 중심이 여전히 원래 bounding box 내부에 위치하도록 제한한다. 이를 통해 노이즈가 과도하게 커지는 것을 방지한다 - Box Scaling
: 박스의 너비와 높이를 일정 범위 내에서 무작위로 확대하거나 축소한다.
클래스 label에 대한 노이즈를 위해서는, 일부 GT 객체의 클래스 label을 무작위로 다른 label로 바꾸는 label flipping을 적용한다.
이를 통해 모델은 노이즈가 섞인 박스에서도 올바른 클래스 label을 복원하도록 학습하게 되며, 박스와 label 간의 관계를 더 강하게 학습할 수 있다. label을 뒤집는 비율은 하이퍼파라미터로 조절된다.
Denoising query에 대해서는 GT 객체를 복원하는 reconstruction loss를 적용한다. 박스에 대해서는 L1 loss와 GIoU loss를, 클래스 레이블에 대해서는 focal loss를 사용한다.
- L1 loss
:예측한 bounding box 좌표와 GT box 좌표 사이의 절대 거리 차이를 측정 - GIoU loss
: box가 아예 겹치지 않으면 IoU = 0이 되는 문제를 해결하기 위해,겹치지 않는 경우에도 학습 신호를 줌 - Focal loss
: 잘 맞춘 샘플은 덜 고려하고, 틀리거나 애매한 예측에 loss를 집중
* 이 Denoising task는 훈련 단계에서만 사용되고, 추론 단계에서는 기존 DETR과 동일하게 matching query만 사용한다.
[ Attention Mask 부분 ]
Attention mask는 DN-DETR에서 denoising 학습이 제대로 작동하기 위해 필수적인 구성 요소이다.
실제로 논문에서는 attention mask를 제거할 경우, denoising이 성능을 향상시키기는커녕 오히려 성능을 저하시킨다는 점을 실험적으로 증명했다.
attention mask의 목적은 information leakage를 방지하는 것이다.
구체적으로는 먼저 matching query가 denoising query를 참조하는 경우를 막는데, 이는 이 경우를 막지 않으면 matching query가 GT 정보를 간접적으로 참조하는 문제가 발생하기 때문이다.
또한 서로 다른 denoising group 간에 정보가 공유되는 경우도 막아주는데, 이는 동일한 GT 객체의 한 노이즈 버전이 다른 노이즈 버전을 참고하면 denoising 태스크가 지나치게 쉬워지기 때문이다.
즉, 이를 방지하기 위해 attention mask는 matching 부분이 denoising 부분을 보지 못하게 하고, 서로 다른 denoising group 간의 attention을 차단하도록 설계된다.
(참고로, 반대로 denoising query가 matching query를 보는 것은 성능에 영향을 주지 않는데, 이는 matching query가 GT 정보를 직접적으로 포함하지 않는 학습된 query이기 때문이다.)
[ DN의 plug-and-play ]
논문은 denoising training이 특정 아키텍처에 종속된 기법이 아니라, training strategy임을 강조한다.
이를 입증하기 위해, 명시적인 4D anchor를 사용하는 DAB-DETR뿐 아니라, 2D anchor를 사용하는 Anchor DETR, 그리고 명시적인 anchor가 없는 Vanilla DETR에도 denoising 기법을 확장 적용한다.
나아가 denoising의 핵심 아이디어가 불안정한 레이블 할당을 우회하여 GT를 직접 복원하도록 학습하는 것임에 착안하여, 전통적인 CNN 기반 탐지기인 Faster R-CNN과 segmentation 모델인 Mask2Former에도 denoising training을 적용할 수 있음을 보인다.
5. Experiment
실험은 MS-COCO 2017 Detection task로 진행, 다양한 IoU threshold와 object scales에 따른 COCO 검증 데이터셋의 표준 mean average precision (AP) 결과를 냈다.
실험에서는 DAB-DETR을 기본 아키텍처로 사용하여 denoising training의 효과를 검증했으며, 동일한 학습 설정 하에서 기존 DAB-DETR 및 그 변형 모델들과 공정하게 비교했다.
또한 denoising training이 특정 구조에 종속되지 않음을 보이기 위해, Deformable DETR, Anchor DETR, Vanilla DETR, Faster R-CNN, DINO, Mask2Former, Mask DINO 등 다양한 탐지 및 분할 모델에 동일한 방식으로 denoising 학습을 적용했다.
모든 결과는 동일한 backbone과 학습 조건에서 비교되었으며, 짧은 학습 스케줄(1×, 12 epochs)과 표준 학습 스케줄(50 epochs) 모두에서 denoising training의 효과를 평가했다.
[ Denoising Training 성능 확인 ]

DAB-DETR 및 다른 single-scale DETR 모델들과 비교하여 Denoising Training을 통한 절대적인 성능 향상을 보여주기 위해, 기본 single-scale 설정 하에서 다양한 backbone을 사용한 실험 결과이다.
Table 1을 보면, 널리 사용되는 네 가지 backbone 모두에서 single-scale 모델 중 가장 좋은 결과를 달성했다. 또한 이 표는 denoising training이 추가하는 파라미터와 연산량이 무시할 수 있는 수준임을 보여준다.
기존 모델의 성능 혹은 더 나은 성능을 달성하기 위한 epoch 수도 감소했음을 알 수 있다.
(e.g., DETR-R50이나 Faster RCNN-FPN-R50에 비해 DN-DETR-R50이 각각 1/10배, 1/2배의 epochs만을 필요로 한다. 논문 내 성능을 비교한 다른 Table에서도 이와 같은 수치를 확인할 수 있다.)
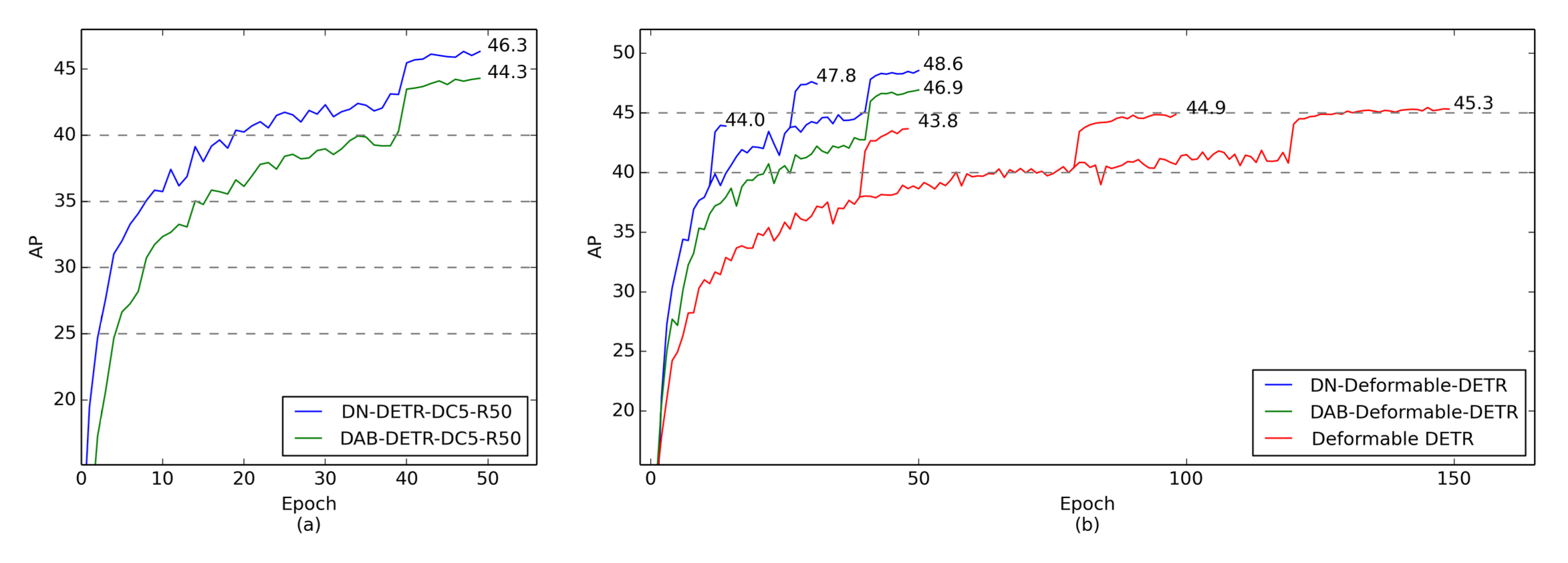
이 두 개의 그래프는 서로 다른 모델 설정에서 Query Denoising 기법의 효과를 시각화한 것이다.
(a) single scale 설정에서의 수렴 곡선
DN-DETR은 학습 초반부터 DAB-DETR보다 훨씬 빠르게 AP가 상승하며, 더 높은 최종 AP를 달성한다.
DN-DETR이 약 20 에포크에서 달성하는 AP 수준은 DAB-DETR이 약 40 에포크에 도달하는 수준과 비슷하다. 이는 DN-DETR이 DAB-DETR 대비 약 2배 빠른 수렴 속도를 보여준다는 것을 의미합니다.
(b) multi scale 설정에서의 수렴 곡선
Deformable DETR보다 DAB-Deformable-DETR이 훨씬 빠르게 수렴하고 더 높은 성능을 달성한다. 이는 쿼리를 ahchor box 형태로 명시화하는 것이 수렴 속도와 성능 향상에 기여함을 보여준다.
DAB-Deformable-DETR보다 DN-Deformable-DETR이 더 빠르게 수렴하며 최종적으로 가장 높은 AP를 달성한다. 이는 Denoising 학습이 ahchor box 기반 쿼리를 사용하는 Deformable DETR 아키텍처에서도 추가적인 수렴 가속화 및 성능 향상을 제공함을 입증한다.(그래프 중간에 AP가 급격히 상승하는 지점은 Learning Rate이 감소하는 시점으로, 일반적으로 이러한 지점에서 모델 성능이 크게 향상된다.)
이 실험 결과는 Query Denoising 기법이 DETR 및 그 변형 모델들의 학습 수렴 속도를 크게 가속화하고, 최종 객체 탐지 성능을 향상시키는 데 매우 효과적임을 보여준다. 이는 DETR 계열 모델들의 느린 수렴 문제를 해결하는 중요한 기여임을 시사한다.
[ Ablation Study ]
ResNet-50 백본을 사용해 50 epochs 설정에서 denoising training의 각 구성 요소에 대한 ablation study를 수행했다.

결과적으로 denoising training의 모든 구성 요소가 성능 향상에 기여함을 확인했고,특히 attention mask가 없을 경우 성능이 크게 저하되어, 정보 누출 방지가 denoising 학습에서 필수적임을 보여줬다.
또한 denoising group 수를 늘릴수록 성능이 향상됨을 알 수 있었다. 다만, 그룹 수가 증가할수록 성능 향상 폭은 점차 감소했고, 실험 전반에서는 5개의 denoising group이 성능과 효율의 균형점으로 사용되었다.
6. Conclusion
이 논문은 DETR의 느린 학습 수렴 문제가 불안정한 bipartite matching에서 비롯된다는 점을 분석하고, 이를 완화하기 위한 denoising 기반 학습 방법을 제안했다. 이 분석을 바탕으로, DAB-DETR에 denoising 학습을 통합한 DN-DETR을 제안하고 그 효과를 실험적으로 검증하였다.
DN-DETR은 디코더 쿼리를 박스와 레이블 임베딩으로 명시적으로 해석하고, bounding box와 class label 모두에 대해 denoising 학습을 도입한다. 또한 본 방법의 범용성을 보이기 위해 Deformable DETR 등 다른 DETR 계열 모델에도 denoising 학습을 적용했다. 실험 결과, denoising 학습은 학습 수렴을 유의미하게 가속화할 뿐만 아니라 탐지 성능 또한 향상시키며, ResNet-50 및 ResNet-101 백본을 사용하는 1×(12 epochs) 설정에서 기존 방법들 대비 최고의 성능을 달성하였다.
이러한 결과는 denoising 학습이 추가적인 연산 비용을 거의 요구하지 않으면서, DETR 계열 모델에 일반적인 학습 전략으로 쉽게 통합될 수 있음을 보여주었다. 나아가 이 연구는 학습 수렴과 최종 성능을 동시에 개선할 수 있는 실용적인 접근법을 제시한다는 점에서 의미를 가진다.
[ ⚠️ 한계점 ]
한편, 이 연구에서는 노이즈를 단순한 uniform distribution에서 샘플링하여 사용하였으며, 보다 복잡한 노이즈 생성 방식에 대한 탐구는 이루어지지 않았다. 노이즈가 섞인 데이터를 복원하는 접근은 비지도 학습과 확산 모델에서 큰 성공을 거두어 왔으며, 본 연구는 이를 객체 탐지에 적용하기 위한 첫 단계로 볼 수 있다.
향후 연구에서는 비지도 학습 기법을 활용한 사전 학습, 약하게 레이블링된 데이터에 대한 활용, 그리고 보다 정교한 denoising 전략을 탐지 모델에 적용하는 방향을 탐구할 예정이다.
