
https://arxiv.org/abs/1905.11946
이 논문에서는 모델의 정확도를 효율적으로 높이기 위하여 깊이, 너비, 해상도를 어떻게 상승시켜야 하는가를 연구합니다.
Related Work
이전 연구([1],[2])들에 따르면 ImageNet에서 높은 성능을 내는 모델들 전이학습이나, 객체 탐지에서도 높은 성능을 가집니다.
이에 ImageNet 성능은 범용적인 지표로 사용할 수 있습니다.
| GoogleNet(2014) | 74.8% | 6.8M parameters |
| SENet(2017) | 82.7% | 145M parameters |
| GPipe | 84.3% | 557M parameters |
이처럼 정확도가 높은 모델들은 파라미터 수가 증가하는 경향이 있습니다.
하지만 하드웨어 메모리는 한계가 있기 때문에 더 높은 정확도를 위해서는 컴퓨팅 자원의 효율적인 사용이 요구됩니다.
이전에는 파라미터수를 줄이기 위하여 모델 압축이나 hand-crafted 경량화 모델 설계 들의 방법이 쓰였으나 최근에는 NAS([3])의 방법을 통해 너비, 깊이, 커널의 종류와 크기를 튜닝하여 다른 모델에 비해 더 효율적인 모델을 제작할 수 있습니다.
하지만 NAS는 경량화 모델을 만드는 것에만 용이하기에 이 논문에서는 큰 모델을 스케일링을 초거대 ConvNet을 연구하고자 합니다. 통해 만들어보고자 합니다.
이전 연구들은 통해 깊이, 너비, 그리고 이미지의 해상도를 조절하여 모델의 성능을 조절할 수 있음을 발견하였으나 한가지 요소만
조정하여 복합적으로 조정하였을 때 어떠한 방법으로 조정해야 하는지는 알 수 없었습니다.
이 논문에서는 체계적이고 실험적으로 그 방법을 탐구하고자 합니다.
Compound Model Scaling
복합적 스케일링 방법을 논하기 이전에 문제를 정의하고자 합니다.

ConvNet N은 연산자 F의 리스트로 구성됩니다. 이때 X는 입력 텐서, Y는 출력 센서를 나타내며, H,W,C는 각각 높이, 너비, 채널을 나타냅니다.
위의 식을 설명하면 최초의 입력 텐서 X_1이 F_1,F_2,...F_s까지 각각 L_1,L_2,... L_s번씩 반복되어 적용되어 Y_s값을 도출한다는 의미입니다.
이 논문에서는 연산자 이외의 요소를 효율적으로 찾는 것을 목표로 하기 때문에 F_i는 고정한 채 L_i(길이), C_i(너비), 해상도(H_i,W_i)를 조정하여 확장합니다.

d,w,r은 각각 깊이, 너비, 해상도를 조절하는 계수를 의미하며, 위의 식은 주어진 제약(Memory, FLOPS) 안에서 정확도를 최대화 하는 것이 목표임을 명시합니다.
이전 연구들에서는 각 요소들을 하나씩만 조절하였고 그러한 결과는 다음과 같습니다.
깊이
장점: 깊이가 크면 더 풍부하고 복잡한 특징을 잘 잡아내고, 일반화 능력이 뛰어납니다.
단점: 기울기 소실등이 발생할 수 있고, 매우 깊어졌을 때 성능 향상의 폭이 감소한다는 단점이 있습니다.
너비
장점: 너비가 크면 미세한 특징을 잘 잡아내고, 학습이 용이합니다.
단점: 깊이가 동반되지 않은 너비 상승은 고차원적인 특징을 잡아낼 수 없으며, 매우 넓어졌을 때 성능 향상의 폭이 감소한다는 단점이 있습니다.
해상도
장점: 고해상도 이미지는 더 미세한 패턴을 담고 정보를 많이 가지고 있어 정확도를 높여줍니다.
단점: 해상도가 상승할수록 성능 향상의 폭이 감소한다는 단점이 있습니다.
위의 세 요소 모두 커질수록 정확도는 높아지나 상승폭이 감소하는 것을 알 수 있습니다.

또한 실제 실험 결과 FLOPS의 양 대비 정확도의 상승폭이 감소함을 관측할 수 있습니다.

직관적으로는 고해상도 이미지가 입력된다면 네트워크가 깊고 채널이 많아져야 하기 때문에 넓어져야 합니다.
위의 결과값을 통해 여러 차원의 요소들이 같이 증가할 때 더 효율적으로 정확도를 높일 수 있음을 알 수 있습니다.
따라서 균형적인 깊이, 너비, 해상도의 스케일링이 중요함을 알 수 있습니다.

이 논문에서는 다음과 같은 스케일링 방법을 제안합니다.
φ라는 새로운 상수를 기준으로 스케일링을 진행합니다. 이러한 2^φ는 α*β^2*γ^2에 비례하는 것을 알 수 있는데, 이는 깊이가 2배 증가하면 FLOPS는 2배 증가하지만 채널수와 해상도가 2배 증가하면 채널수는 입력 채널(2배)* 출력채널(2배)로 4배, 해상도는 가로(2배)*세로(2배)로 4배 증가하므로 2^φ ≒ α·β^2·γ^2임을 알 수 있고, 이는 FLOPS가 d*w^2*r^2에 비례함을 나타냅니다.
EfficientNet Architecture
모델 스케일링은 baseline network의 기본 연산자의 최종 모델의 성능과 매우 연관되어 있으므로 baseline network의 선정이 중요합니다. 따라서 이 논문에서는 기존 모델(ResNet, MobileNet 등)을 이용할 뿐만 아니라 더 극한의 효율성을 증명하기 위하여 자체 개발한 baseline network인 EfficientNet도 이용합니다.
NAS를 이용해 baseline network을 찾기 위하여 설정한 조건은 다음과 같습니다.
Optimization goal:
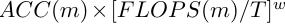
Search space:
블록 종류:MBConv, Squeeze-and-Excitation optimization
커널 크기: 3*3, 5*5
Search Algorithm:
다목적 신경망 아키텍처 탐색 (Multi-objective Neural Architecture Search)
Constraints:
목표 FLOPS:400M
hyperparameter w: -0.07
이때 우리가 만들고자 하는 baseline model은 MnasNet과 같은 search space를 사용하지만 MnasNet은 mobile 기기에 최적화된 모델을 찾고, baseline model은 400M FLOPS에서 최적화된 모델을 찾는 것으로 설정하였기에 더 큽니다.
이를 통해 얻은 B0의 구조는 다음과 같습니다.

이때 위의 스케일링 공식을 이용하여 연구팀은 α=1.2, β=1.1, γ=1.15의 해를 찾고 고정된 상수로 스케일링을 진행합니다.
B1은 컴퓨팅 자원을 2배,... B7은 컴퓨팅 자원을 128배로 설정하고 실험을 진행합니다.
Experiments
각 요소 간의 균형적인 상승이 EfficientNet에서만 작동한다는 것이 아닌 것을 증명하기 위해 MobileNetV1, MobileNetV2, ResNet-50에서도 스케일링 업을 진행하고 정확도와 FLOPS를 측정하였습니다.

컴퓨팅 자원을 4배 사용하였을때 2^φ ≒ α·β^2·γ^2 (φ=2)을 적용하여 깊이, 너비, 해상도를 상승시킨 경우가 각 한 요소만 상승시켰을 때보다 높은 정확도를 얻었음을 알 수 있습니다.
또한 EfficientNet의 ImageNet 결과값은 다음과 같습니다.
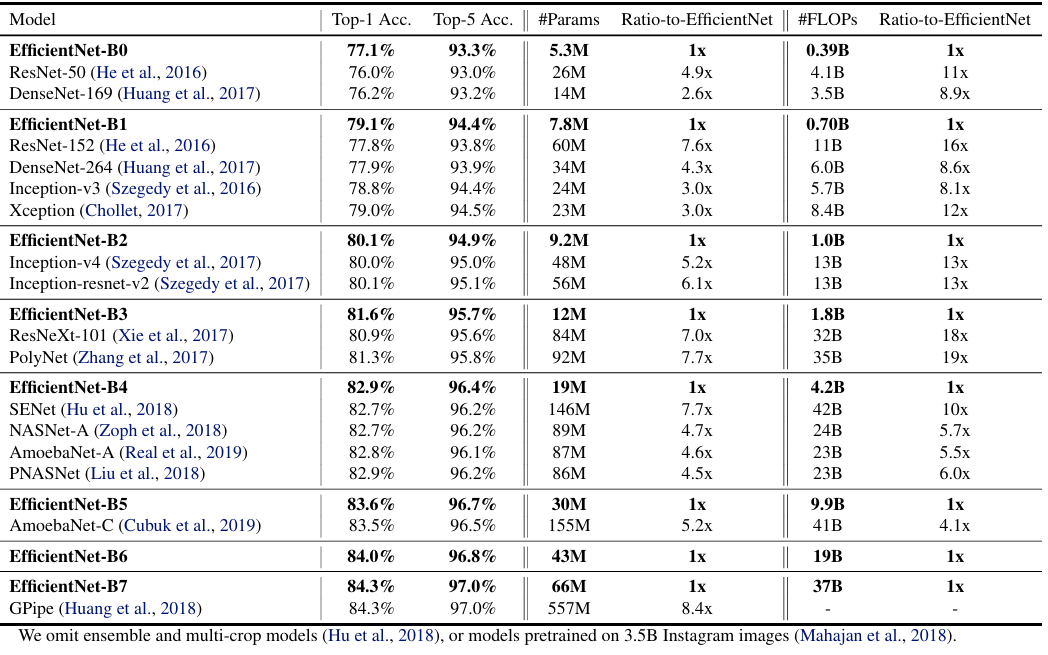
가장 높은 정확도를 가지고 있는 GPipe 모델에 비해 파라미터 수는 8.4배 FLOPS는 6.1배 적게 같은 성능을 발휘했으며,
ResNet-50과 EfficientNet-B4를 비교하였을 때 더 적은 파라미터와 비슷한 FLOPS로 더 높은 정확도의 성능을 가졌음을 알 수 있었습니다.
또한 ImageNet을 통해 Pre-trained 된 EfficientNet을 서로 다른 데이터셋 8개에서 fine-tunning 한 결과는 다음과 같습니다.

비슷한 정확도를 가지는 다른 모델들에 비해서 평균적으로 4.7배 적은 수의 파라미터로 학습하였고, 8개 중 5개의 데이터셋에서 SOTA를 달성하였음을 알 수 있습니다.
이를 통해 EfficientNet과 스케일링은 범용적인 데이터셋에서 낮은 FLOPS로 높은 정확도를 얻어내기 위한 효과적인 방법임을 알 수 있습니다.
Discussion

이 연구팀의 baseline network인 EfficientNet에서 다른 스케일링 업을 진행한 것들과 이 연구팀의 스켈링링 업을 진행한 모델을 비교하였을 때 복합 스케일링을 적용한 모델의 정확도가 항상 더 높았습니다.

또한 CAM의 기술을 사용하여 관측하였을 때 같은 baseline model을 다른 스케일링을 적용한 것보다 배경과 물체를 명확하게 구분하는 것을 알 수 있습니다.
이를 통해 복합 스케일링은 세부적인 패턴을 잘 파악함을 관측할 수 있었습니다.
[1] Kornblith, S., Shlens, J., and Le, Q. V. Do better imagenet models transfer better? CVPR, 2019
[2] He, K., Zhang, X., Ren, S., and Sun, J. Deep residual learning for image recognition. CVPR, pp. 770–778, 2016
[3] Cai, H., Zhu, L., and Han, S. Proxylessnas: Direct neural architecture search on target task and hardware. ICLR, 2019.
