

BERT : "대규모 unlabeled 데이터로 양방향 문맥을 깊이 있게 사전 학습한 후, 다양한 NLP task에 fine-tuning하면 강력한 성능을 발휘할 수 있다"는 것을 처음으로 입증한 모델

BERT vs GPT
BERT
- Bidirectional LM
- Loves Fine Tuning
GPT
- Left to Right LM
- Hates Fine Tuning
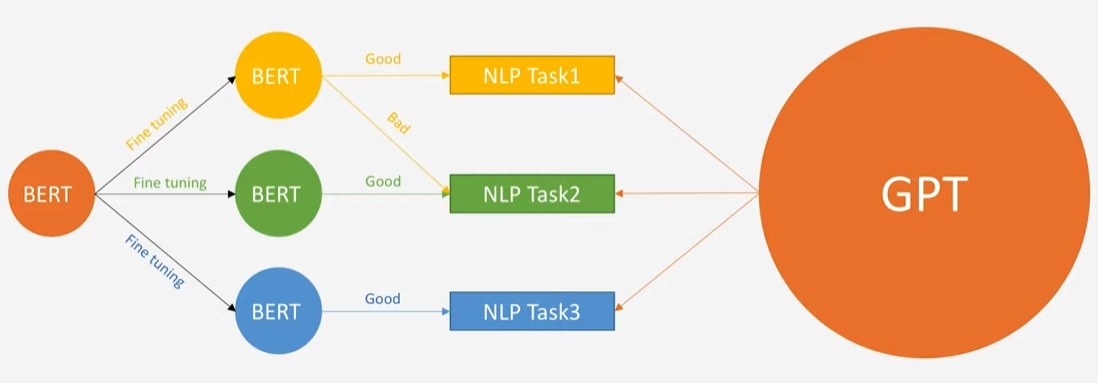
orange : pretrained model
size : model size.

배경 및 한계
- 기존의 언어 모델들은 대부분 unidirectional (좌→우 또는 우→좌)이라 문맥을 한 방향에서만 볼 수 있었습니다.
- 예: OpenAI GPT는 좌→우 방식이고, ELMo는 좌→우, 우→좌 독립적으로 훈련한 후 결합하는 구조였습니다.
- 이 접근법은 문맥의 Bidirectional 정보를 충분히 반영하기 어려워, 특히 문장 수준의 이해나 정밀한 토큰 예측에 한계가 있었습니다.
BERT의 핵심 아이디어
- Deep Bidirectional Transformer 기반으로, 양방향 문맥을 모두 반영할 수 있도록 설계.
- 이를 가능하게 하기 위해 2가지 pre-training task를 제안:
- Total Loss=MLM Loss+NSP Loss
- Masked Language Model (MLM):
- 입력 문장에서 15% 단어를 랜덤하게 [MASK]로 바꾸고, 이를 예측하는 방식.
- 이 15% 중에서 학습 시 80%는 [MASK], 10%는 랜덤 단어, 10%는 원래 단어로 유지하는 전략을 사용.
- Next Sentence Prediction (NSP):
- 두 문장이 연속인지 아닌지 판별하는 이진 분류.
- 문장 간 관계를 학습하게 하여 다양한 NLP task에 효과적
- Masked Language Model (MLM):


모델 아키텍처
- Transformer encoder 구조 사용 (Vaswani et al., 2017).
- 두 가지 버전:
- BERTBASE: 12 layers, 768 hidden units, 12 attention heads (110M parameters)
- BERTLARGE: 24 layers, 1024 hidden units, 16 attention heads (340M parameters) BERTLARGE가 3배 이상 큰 모델로, 더 깊고 넓은 표현력을 가짐.
- 입력:
- WordPiece tokenizer (vocab size 30,000) WordPiece Embedding(단순 띄어쓰기가 아님)으로 문장을 token단위로 분리. ex. playing을 play와 ing로 분리.
- Special token: [CLS], [SEP] CLS : 문장 전체가 하나의 벡터로 표현된 special token.
- SEP : 두문장으로 구성되어있을때 이것으로 구분.
- Token embedding + Segment embedding (문장 A/B 구분) + Position embedding 두개의 다른 문장이 있는걸 알려주는 segment embedding Position embedding : token의 상대적 위치정보를 알려줌. sin,cos함수 사용.
Fine-tuning 전략
- Task-specific layer만 추가하고, BERT의 모든 파라미터를 함께 fine-tune.
- 다양한 downstream task (GLUE benchmark, SQuAD 1.1/2.0, SWAG 등)에 적용:
- 문장쌍: QA, NLI 등에서는 문장 A, B를 [SEP]으로 구분.
- 문장 분류: [CLS]의 hidden state를 사용.
- 토큰 태깅: 각 토큰의 hidden state를 사용. → BERT가 토큰별로 생성한 contextual representation을 기반으로 token-level classification을 수행
주요 실험 결과
- GLUE Benchmark: 기존 최고 모델 대비 큰 성능 향상 (BERTLARGE 기준 평균 82.1점)General Language Understanding Evaluation 다양한 언어 이해 과제를 포함하는 8개 Task 모음집. GLUE Benchmark: 기존 최고 모델 대비 큰 성능 향상 (BERTLARGE 기준 평균 82.1점)
- GLUE Benchmark
- SQuAD v1.1/2.0: SOTA 기록 달성 (v1.1 F1 93.2, v2.0 F1 83.1)
- SWAG (상식적 문장 선택): 기존 최고 대비 +8.3% 정확도 향상
- 모델 크기 효과: 모델 크기가 커질수록 모든 task에서 성능 향상
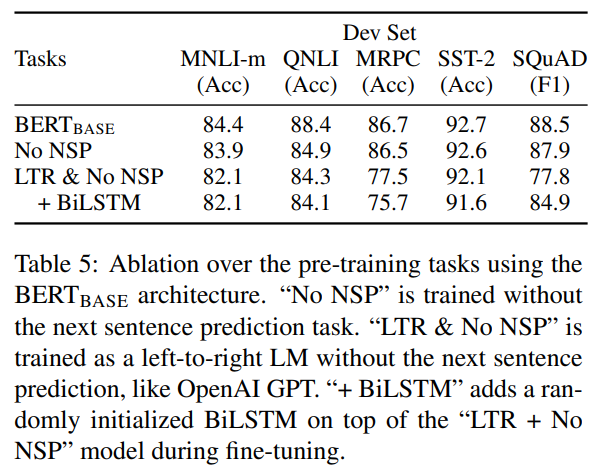
Ablation Study (성능 분석)
- NSP 제거 시 성능 저하 → 문장 간 관계 학습의 중요성 입증.
- 좌우 방향성 제한 (LTR;Left-To-Right) 모델은 성능 저하, 특히 QA task에서 큰 차이.
- BiLSTM 추가해도 bidirectional Transformer보다 못함.

Feature-based vs Fine-tuning
- Fine-tuning: 성능이 가장 좋음.
- Feature-based (고정된 embedding 추출 후 별도 모델 학습): 조금 떨어지지만 여전히 강력.
- Embeddings: WordPiece embedding만 사용했을 때 성능 낮음 (91.0)
- Second-to-Last Hidden: 마지막에서 두 번째 layer representation이 더 좋음
- Concat Last Four Hidden: 상위 4개 layer의 representation을 concat했을 때 Dev F1 최고 (96.1)
결론
- Pre-trained deep bidirectional 모델이 NLP 다양한 task에 범용적이고 효과적임을 최초로 증명.
- 특히 Transformer encoder의 강력한 표현력과 MLM+NSP pre-training이 큰 역할.
- 이 연구 이후, BERT는 NLP에서 범용적인 foundation model로 자리잡았음.
Reference :
https://www.youtube.com/watch?v=30SvdoA6ApE 허민석 유튜브
https://arxiv.org/abs/1810.04805v2 BERT
https://medium.com/data-science/2019-year-of-bert-and-transformer-f200b53d05b9
'NLP' 카테고리의 다른 글
| [2025-2] 박지원 - QLORA (0) | 2025.07.17 |
|---|---|
| [2025-2] 박제우 - GRAPH ATTENTION NETWORKS (0) | 2025.07.13 |
| [2025-2] 이루가 - LEGAL-BERT: The Muppets straight out of Law School (0) | 2025.07.13 |
| [2025-2] 김지원 - From Transcripts to Insights:Uncovering Corporate Risks UsingGenerative AI (0) | 2025.07.13 |
| [2025-1] 임준수 - Self-Adapting Language Models (0) | 2025.07.10 |



