

Fig. 1 Transformer의 Encoder-Decoder 구조를 도식화한 것
왼쪽은 Encoder, 오른쪽은 Decoder
self-attention과 feed-forward 사이사이에 반복적으로 Residual Connection과 Layer Normalization이 들어감. Transformer 블록은 (Self-Attention → Add & Norm → Feed-Forward → Add & Norm) 순서로 구성됨
Encoder (왼쪽)
- Input Embedding:
- 입력 문장(예: 영어)을 각 단어별로 벡터로 변환(임베딩).
- Positional Encoding:
- 단어의 위치 정보를 반영하기 위해 임베딩에 위치 인코딩을 더함.
- N개의 인코더 블록 반복: 각 블록(레이어)은 아래와 같은 두 부분으로 구성됨
- Multi-Head Attention + Add & Norm:입력 임베딩에 대해 self-attention 연산을 수행한 뒤, 원래 입력과 더해(residual connection), layer normalization 적용.
- Feed Forward + Add & Norm: 각 토큰에 대해 동일하게 Feed Forward Network를 적용, 다시 residual connection과 layer normalization 수행.
Decoder (오른쪽)
- Output Embedding:
- 생성할 문장(예: 프랑스어)의 이전까지의 단어를 임베딩(shifted right;디코더 입력을 한 칸 오른쪽으로 shift해서 이전까지의 출력만 가지고 다음 단어를 예측하도록 만드는 것.).
- Positional Encoding:
- 마찬가지로 위치 정보를 더함.
- N개의 디코더 블록 반복: 각 블록(레이어)은 아래 세 부분으로 구성됨:
- Masked Multi-Head Attention + Add & Norm:
- 자기 자신에 대한 self-attention이지만,
- 미래 토큰은 보지 못하도록 마스킹(masking) 적용.
- Multi-Head Attention + Add & Norm:
- Encoder의 출력을 K,V로, Decoder의 출력을 Q로 사용하여
- 입력(원문)과 출력(번역문) 사이의 attention을 계산.
- Feed Forward + Add & Norm:
- Encoder와 동일하게 각 토큰별 Feed Forward Network 적용.
- Masked Multi-Head Attention + Add & Norm:
- 마지막 출력:
- Linear layer와 Softmax를 거쳐
- 다음 단어의 확률 분포를 출력.

Fig. 2 Attention 구조 (Scaled Dot-Product Attention & Multi-Head Attention)
Scaled Dot-Product Attention (왼쪽) (Self-Attention에서 사용되는 핵심 연산 로직.)
- Q, K, V:
- 입력 임베딩에서 Query(Q), Key(K), Value(V)로 변환.
- MatMul (Q, K):
- Q와 K의 행렬곱으로 attention score 계산.
- Scale:
- score를 sqrt(dk)로 나눠 스케일링.
- (Optional) Mask:
- decoder의 masked attention에서 미래 정보 차단용 마스크 적용.
- Softmax:
- 각 단어별로 확률화.
- MatMul (softmax, V):
- 확률값을 Value에 곱해 최종 attention output 생성.
Multi-Head Attention (오른쪽)
- 여러 개의 head(병렬 attention)
- 입력을 여러 head로 나누어 각각 다른 Q,K,V projection을 적용.
- 각 head별로 Scaled Dot-Product Attention 연산
- 위 과정(왼쪽 그림)을 head 수만큼 병렬로 수행.
- Concat
- 각 head의 output을 연결(concatenate).
- Linear
- 최종적으로 다시 Linear projection을 통해 output 차원 복원
How Fast? Parallelization
기존의 RNN은 순차적으로 encoding을 진행한다.

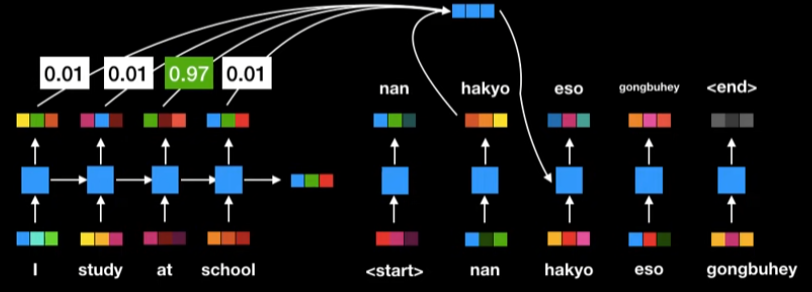
고정된 context vector를 사용하지 않고 모든 상태값을 활용. 하지만 순차적으로 계산하기때문에 느리다



즉, transformer는 RNN을 사용하지 않아, 병렬화를 가능하게 하여 빠른 학습을 가능하게 한다.
Positional Encoding
RNN에서 NLP에서 많이 활용되었던 이유 : 단어의 위치와 순서 정보를 잘 활용했기때문.
상대적인 위치정보를 더해주는 positional encoding을 이용해서 transformer는 이부분을 보완했다.
즉, 각단어의 word embedding + positional embedidng



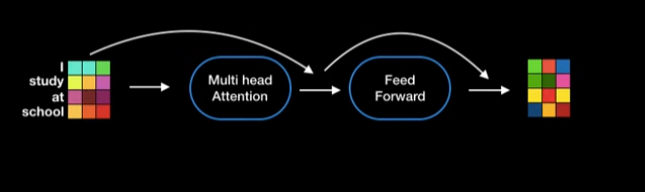
Self Attention
word embedding + positional embedidng 다음 self attention 연산이 encoder에서 이루어진다.
Q,K,V는 행렬곱으로 한번에 구함
Q,K,V는 벡터의 형태.
- Q,K,V구하기
현재 단어의 Q
그 단어와 다른 단어의 상관관계를 알고싶을때 그 다른 단어의 K. - score구하기
Q와 K를 dot product로 곱하면 그게 attention score. - softmax 취하기
softmax(score/sqrt(dim of key))→ 0~1사이의 값. - softmax * V
그 확률값을 다른 단어의 V와 곱해주면, 연관성을 고려한 V값이 만들어짐. (attention이 고려됨.) - sum (softmax * V)
attention layer output
: 현재 단어가 그 문장 속 (다른 단어와의 관계 속)의 의미를 반영한 벡터가 만들어짐.


Multi head attention : 위의 self attention을 병렬로 이용하는 기법




Add&Norm

Add : Skip Connection
입력차원과 출력의 차원을 동일하게 맞추었기에 Residual Learning, 즉, skip connection을 적용하는 것이 가능
word embedding에 positional encoding을 더해줬는데, 이것은 역전파에 의해 손실될수있어, residual connection으로 다시한번 positional encoding을 더해준다.

Norm : Layer Normalization: Gradient vanishing 방지

Layer Normalzation은 각 단어 vector(feature별로)들에 대해 정규화 함으로써 gradient vanishing 문제에 대응하기 위함이다.
출력 vector의 차원의 크기가 입력 vector와 동일하다. → encoder layer는 여러개를 붙여서 사용할 수 있다.

Feed-Forward Networks
Feed-Forward Network (FC) : Residual + LayerNorm된 결과가 각 Fully Connected Layer(Feed-forward network, 그림에서 FC)로 전달됩니다.
Transformer의 feed-forward layer는(Fully Connected + Non-linearity)로 구성된 네트워크이며, 각 토큰별로 적용되어 비선형적인 feature transformation을 가능하게 합니다.
두 번의 Linear + 중간에 ReLU로 구성
토큰(x)별로 이 연산을 적용.차원 확장(2048) 후 다시 축소(512)

Decoder :
동일하게 self-attention이 적용되지만, encoder와 다르게 Masked self-attention을 사용.
정답을 순차적으로 생성해야하기때문에 필요. (현재 상태만을 이용해 답변을 생성)




Label smoothing
(일반화와 overfitting의 해결. 정답 label에 대한 강한 확신을 가지지 못하게함.)
vector를 최종 단어로 출력하는 법 : decoder마지막 부분에 Linear layer(Logit생성), Softmax(확률값)생성. 가장 높은 softmax값을 갖는 단어가 다음 단어로 출력됨.
→ 이때 Label smoothing을 사용해서 성능을 더 높인다.(0또는 1이 아닌, 0에 가까운값, 1에 가까운값을 사용해서 overfitting을 방지. noisy한 lable의 경우 필요함.)

Transformer에 존재하는 세 종류의 attention 정리
- self-attention in encoder
encoder에서 사용되는 self-attention으로 queries, keys, values 모두 encoder로부터 가져온다. 이를 통해 문장에서 특정 단어가 문장의 모든 단어들과 어떤 관계를 가지는지(correlation)를 학습한다. - (masked) self-attention in decoder
encoder의 self-attention와 같지만, masking을 통해 sequence model의 auto-regressive property를 보존한다. 즉, 해당 position 이후의 벡터들을 참조하지 못하게 한다. - encoder-decoder attention
decoder에서 self-attention 다음으로 사용되는 layer로, queries는 이전 decoder layer에서 가져오고, keys와 values는 encoder의 output에서 가져온다. 이는 Decoder에서 단어가 Encoder의 어떤 부분을 참조해야할지를 학습하는 부분이다.
결과 해석 :
- Complexity
n : sequence length,
d : representation dim
Recurrent와 비교했을때, 일반적으로 n이 d보다 작기때문에 time complexity가 적다고 볼수있지만, n에 의존적으로 메모리 요구량이 기하급수적으로 늘어날 수 있음.

2. Machine Translation
English-to-German
English-to-French
둘을 비교한 결과를 보면, Transformer가 BLEU score도 높고, Traning Cost도 낮은것을 확인할 수 있다.

3. Model Version
모델의 변형 결과,
(B),(C) 차원이 클수록(head 많고, d_model/d_ff 큼) 성능이 향상됨
(D) dropout 등도 성능에 영향을 미치나, 핵심은 모델 차원 크기와 head 수

4. English Constituency Parsing

다른 task에도 transformer가 잘 작동하는지를 확인하기 위해, 특정 단어가 문법적으로 어디에 속하는지 분류하는 task진행. tuning을 하지않았음에도 좋은 성능을 확인.
참고 링크
- Vaswani, A., et al. (2017). Attention Is All You Need. arXiv:1706.03762.
https://arxiv.org/abs/1706.03762 - https://secundo.tistory.com/96
- https://www.youtube.com/watch?v=mxGCEWOxfe8



