
1. 논문 개요
- 논문 제목: MTEB: Massive Text Embedding Benchmark
- 게재 연도: 2022 (arXiv:2210.07316)
- 인용 횟수: 2025.04.06 기준 739회 인용.
- 주요 성과:
- 텍스트 임베딩 모델의 평가 한계를 극복하기 위해 8개 Task(Clustering, Classification, Retrieval 등)를 포괄하는 벤치마크 제시
- 총 58개 데이터셋과 112개 언어를 포함하여 단일 평가 프레임워크 내에서 다양한 실제 사용 사례 반영
- 모델 성능뿐만 아니라, latency(지연 시간) 및 임베딩 크기와의 trade-off 분석을 통한 효율성 평가 제공
2. 연구 배경 및 필요성
- Text Embedding의 정의 및 활용:
- 텍스트 데이터를 수치 벡터로 변환하여 NLP 작업(Clustering, 검색 시스템, Text Mining, Downstream 모델의 Feature Representation 등)에 활용
- 기존 평가 방법의 한계:
- 주로 Semantic Textual Similarity(STS) 작업 위주로 평가되어, 검색, clustering, classification 등의 실제 응용 사례 반영이 미흡
- MTEB의 필요성:
- 다양한 Task를 아우르는 평가를 통해 텍스트 임베딩 모델의 실제 활용 성능을 종합적으로 측정
- 재현성과 확장성을 고려한 통일된 평가 플랫폼 제공
3. MTEB의 구성 및 특징
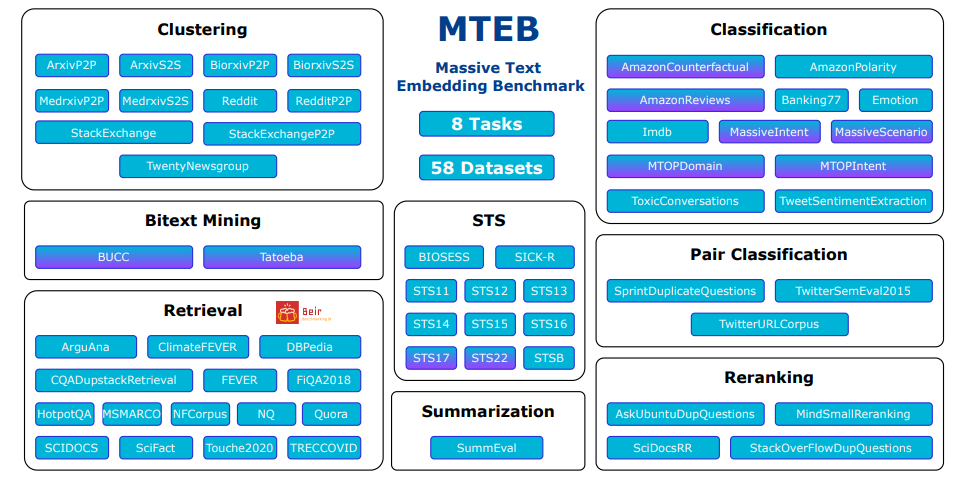

- 다양한 데이터셋:
- 총 58개 데이터셋, 112개 언어 지원
- 텍스트 길이에 따라 분류:
- Sentence-to-Sentence (S2S): 주로 STS 등 문장 간 유사도 평가
- Paragraph-to-Paragraph (P2P): 긴 텍스트(예: 논문 초록 등) 비교
- Sentence-to-Paragraph (S2P): 단일 문장과 여러 문장으로 구성된 단락 비교
- 포함 Task:
- Bitext Mining:
- 두 언어의 문장 집합에서 번역 쌍을 찾기 위해 각 문장을 임베딩 후 코사인 유사도 계산
- 주요 평가 지표: F1 점수, Precision, Recall
- Classification:
- 학습 및 테스트 데이터셋에 대해 임베딩 생성 후 Logistic Regression 분류기를 학습하여 정확도, 평균 Precision, F1 점수 평가
- Clustering:
- Mini-batch K-means 알고리즘을 사용하여 문장/단락을 의미 기반 그룹으로 분류
- 평가 지표: V-measure (클러스터 레이블 순열 무관)
- Pair Classification:
- 두 텍스트 쌍의 관계(예: 중복, paraphrase)를 다양한 거리(metric: 코사인, Euclidean 등) 측정을 통해 분류
- 최적 Threshold 설정 후 Accuracy, Precision, F1 등 평가
- Reranking:
- Query와 관련/비관련 텍스트 목록의 순위를 코사인 유사도 기반으로 재정렬
- 평가 지표: MAP, MRR@k 등
- Retrieval:
- Corpus 내 모든 문서를 임베딩 후, Query와의 코사인 유사도로 순위 매김
- 평가 지표: nDCG@10, MRR@k, MAP@k, Precision@k, Recall@k
- Semantic Textual Similarity (STS):
- 문장 쌍의 유사도를 임베딩 후 Pearson 및 Spearman Correlation으로 평가
- 주로 코사인 유사도를 기반으로 성능 측정
- Summarization:
- 기계 생성 요약과 인간 작성 요약 간의 임베딩 유사도를 비교하여 상관관계(pearson, spearman) 평가
- Bitext Mining:
- 재현성과 확장성:
- 데이터셋 및 소프트웨어 버전 관리를 통해 결과의 재현성 보장
- 새로운 Task 및 데이터셋 추가가 용이하도록 단일 파일 설정 기반 확장 구조 제공
4. 기존 Benchmark와의 비교
- SemEval:
- STS 작업에 초점을 맞춰 다양한 실제 사용 사례(예: 검색, 클러스터링)를 충분히 반영하지 못함
- SentEval:
- 여러 STS 데이터셋을 통합했으나, 검색 또는 군집화 Task 미포함 및 최신 트렌드 반영 어려움
- USEB:
- 주로 reranking 작업에 집중, 다른 Task 평가에는 한계 존재
- BEIR:
- 제로샷 정보 검색 평가에 강점을 보이나, 텍스트 임베딩의 전체 활용 사례를 포괄하지 않음
- MTEB의 차별성:
- 다양한 Task와 데이터셋을 하나의 평가 프레임워크로 통합하여 임베딩 모델의 전반적인 성능 평가 가능
5. 임베딩 모델
- Word Embedding Models:
- 예: Glove, Komninos – 단어 단위 벡터 매핑 및 평균화 기반으로 문맥 인식에 한계 존재
- Transformer 기반 모델:
- Pre-trained 모델: BERT, SBERT 등 기본 임베딩 모델
- Fine-tuning 모델: SimCSE, TSDAE, GTR, SGPT 등 contrastive learning을 통한 supervised/unsupervised finetuning
- MTEB의 접근:
- Word Embedding과 Transformer 기반 모델 모두를 평가하여 문맥 인식의 이점을 정량화
- Self-supervised와 supervised 방법의 성능 차이를 다양한 Task에서 비교 분석
6. 실험 결과 및 분석

- 모델 성능의 다양성:
- Task별로 모델 성능 차이가 큼 – 특정 모델이 모든 Task에서 최고 성능을 보이지 않음
- 데이터셋별 결과 변동성 존재, 실제 응용 시 Task에 맞는 모델 선택 필요
- Self-supervised vs Supervised:
- 대규모 언어 모델을 활용한 Self-supervised 접근도 성능 향상을 보이나, supervised fine-tuning이 여전히 임베딩 품질 개선에 중요
- 모델 크기와 성능(Fig.3):
- 전반적으로 파라미터 수가 많을수록 성능 개선 효과가 있으나, 동시에 latency(지연 시간; 모델이 텍스트 임베딩을 생성하는 데 걸리는 시간 ) 증가라는 trade-off 존재
- Efficiency (Latency-Performance Trade-off)(Fig.4):
- 모델 후보 선택 가이드 제공
- Maximum speed 최대 속도: Glove 등 워드 임베딩 모델
- Maximum performance 최대 성능: GTR-XXL, ST5-XXL, SGPT-5.8B 등 (높은 임베딩 품질, 다만 지연 시간 길음)
- Speed and performance 균형 모델: MiniLM, MPNet 등 속도와 성능의 적절한 타협
- 모델 후보 선택 가이드 제공


7. 다국어 지원 및 분석 (Multilinguality)

- 다국어 데이터셋 구성:
- Bitext Mining, Classification, STS 등 Task에 걸쳐 10개 이상의 다국어 데이터셋 포함
- 모델별 다국어 성능:
- LaBSE: Bitext Mining Task에서 두드러진 성능
- Multilingual MPNet: Classification 및 STS Task에서 전반적으로 강력한 성능
- SGPT-BLOOM: 사전 훈련 언어에 따라 성능 편차 존재
- 언어별 특성 및 평가:
특정 언어 또는 Task에서 모델별 성능 차이가 관찰되며, 사용자 환경에 맞는 모델 선택의 필요성 강조
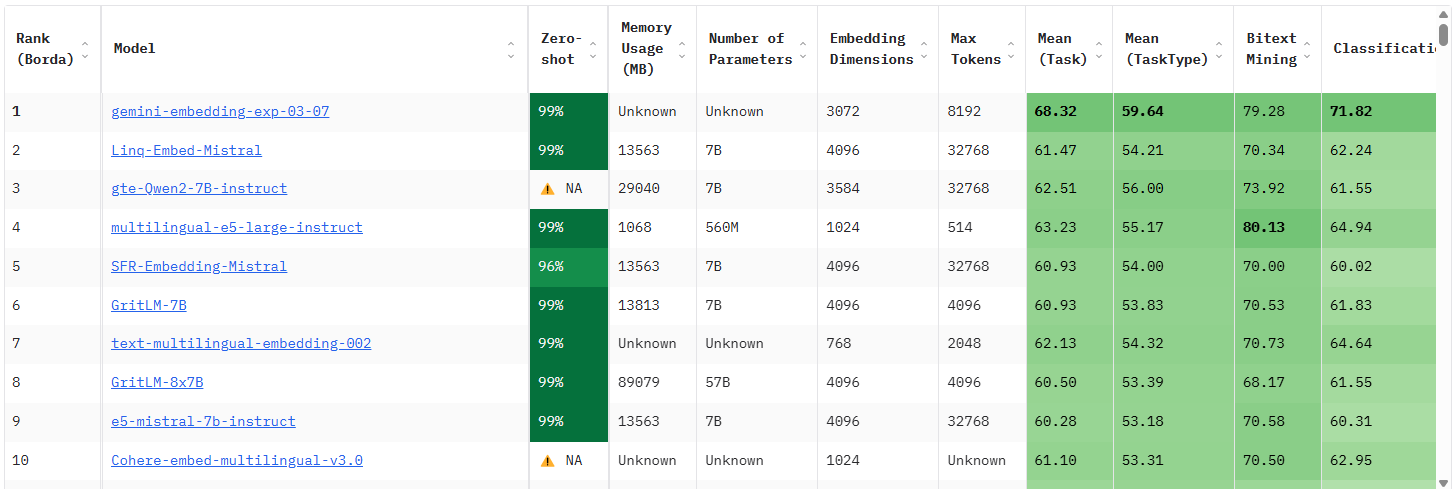
9. MTEB leaderboard rank
Borda Count 방식 사용.
Task 마다 모델들의 성능을 측정해서 순위를 매김. -> 이 모든 작업에서 얻은 순위를 합쳐서 총합 점수를 계산.
즉, 모든 task에서의 상대적인 순위를 기반으로 점수를 매겨, 일관되게 좋은 성능을 보이는 모델을 확인.
8. Reference
- Hugging Face Leaderboard: https://huggingface.co/spaces/mteb/leaderboard
- GitHub Repository: https://github.com/embeddings-benchmark/mteb
- 모델 등록 가이드 코드: https://github.com/embeddings-benchmark/mteb/blob/main/docs/adding_a_model.md
- Paper : https://arxiv.org/abs/2210.07316



