
논문 제목: Forecasting price movements using technical indicators: Investigatingthe impact of varying input window length
논문 인용수: 237회
논문 정보 : Neurocomputing 저널에 2017년 개제된 논문
논문 링크: https://www.sciencedirect.com/science/article/pii/S0925231217311074
1. 소개
머신러닝/딥러닝을 활용한 Financial forecasting은 입력 feature로 Techniqal Indicator(TI)들을 사용한다.
여기서 말하는 TI란 주식 시장에서 차트 분석에 많이 사용되는 지표들인데 예를 들어 RSI, MA, EMA, ATR, ADMI, MACD 등이 있다.
이러한 TI들을 사용해서 Financial forecasting을 수행한 연구들은 많이 존재하지만 TI의 window length (예를 들어 RSI(14)의 경우 window length는 14)를 어떻게 설정해야 할 지 그리고 설정된 window length에 대해 어떤 prediction horizion (예를 들어 5일 뒤 종가 예측이면 prediction horizion은 5)을 사용해야 하는 지 이러한 관계에 대한 연구는 전혀 진
행된 바가 없다.
따라서 저자는 여러 하이퍼 파라미터 세팅에 대해 실험해보고 그 결과들을 분석해보고자 한다.
이때, 저자는 SVM(Support Vector Machine), ANN(Artificial Neural Network), kNN 세 가지 아키텍쳐에 대해 이 실험을 진행했다.
2. Market theories and trading philosophies
Fama가 제안한 효율적 시장 가설(EMA)는 크게 3가지로 나뉜다.
1. Weak Market 2. Semi-Strong Market 3. Strong Market
여기서 Weak Market은 과거의 공개 정보만 현재 가격에 반영되는 시장이고 Semi-Strong은 모든 과거 및 현재 공개 정보가 가격에 반영된 시장이며 Strong Market은 내부자 및 잠재적 정보까지도 즉시 가격에 반영된 시장이다.
즉, 간단하게 말하면 시장이 EMH 가정의 Strong Market을 따른다면 이미 모든 정보가 반영되어 있기 때문에 알고리즘 트레이딩이 시장을 이길 수 없다는 말이다.
하지만 최근(2010년대 무렵) 행동 경제학의 등장으로 적응적 시장 가설(Adaptive Market Hypothesis, AMH)가 등장했다.
AMH는 시장 가격을 순수한 지각 가치로 보며, 시장 참여자들의 인지적 편향(과잉반응, 과신, 정보 편향 등)을 인정한다.
놀랍게도, 실제 연구 결과에서도 AMH가 EMH보다 더 시장 수익률을 잘 설명한다.
덧붙이자면, AMH는 과거 가격 움직임과 유사한 관계를 보이는 의존성 시기와 그렇지 않은 독립성 시기를 가진다고 설명한다.
3. 데이터
2002년부터 2012년까지의 데이터를 가지고 2:1 비율로 학습:validation으로 쪼갰다.
랜덤하게 선택된 총 50개의 주식들이며 Yahoo Finance API를 통해 수집했다.
라벨링은 두 가지 방법을 사용했는데 첫 번째는 "Up"/"Down"이고 두 번재는 "Up/No Move/Down"이다.
이때 두 번재 (three class classification)의 경우 threshold를 통해 3개의 class 비율을 비슷하게 맞춰주려고 했다.

추가로 저자는 각 class 별 비율이 어떻게 되었는 지 아래 표를 통해 설명했다.

입력 feature는 앞서 여러 TI들을 사용한다고 했는데 구체적으로 10개의 TI들을 사용했다.(SMA, EMA, ATR,ADMI, CCI, ROC, RSI, William's %R oscillator, Stochastic %K, Stochastic %D)
4. 결과
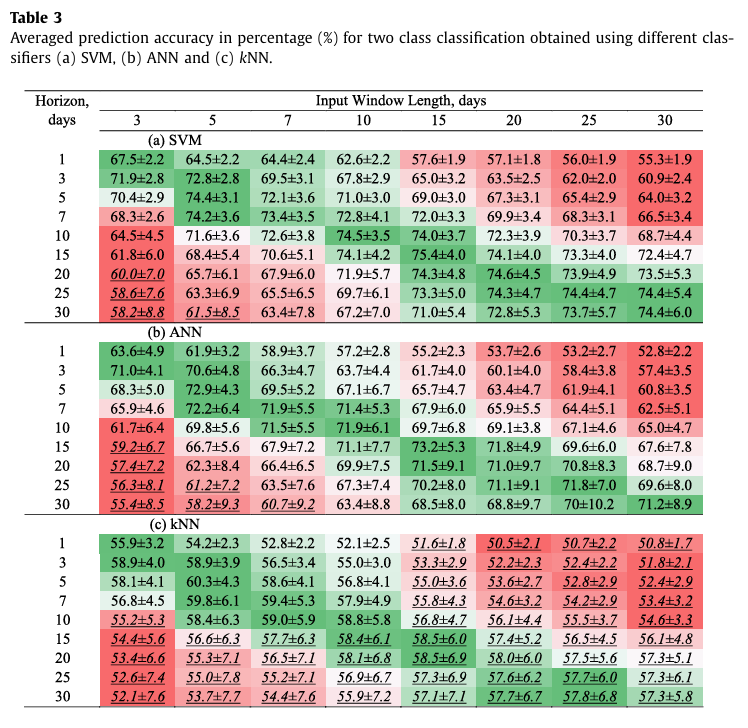
먼저 아래는 이진 분류("Up","Down")에 대한 정확도 결과이다.
이어서 아래는 3가지 분류("Up","No Move","Down")에 대한 정확도 결과이다.

결과를 분석하면
1. 각 예측 기간에 대해 최고 성능은 window length가 prediction horizon과 동일 할 때 달성된다.(변동 폭도 가장 작다)
2. SVM > ANN > kNN 순으로 좋은 성능을 보인다.
3. 이진 분류보다 3 클래스 분류가 정확도가 더 떨어지는데 이는 태스크 자체의 난이도 때문이다.
4. 예측 기간(prediction horizon)이 증가할 수록 성능은 점차 감소한다.
5. 가장 높은 성능은 이진 분류일 때 SVM(15,15)이고 3 클래스 분류일 때 SVM(20,20)이다.
이번에는 Averaged Return으로 분석을 진행했다.

그 결과 이진 분류보다 Three class clasification이 수익이 더 높았는데 이는 "No Move" 클래스를 통해 거래 성능 향상에 기여했기 때문이다(빈번하고 불필요한 거래 방지해줌).
마지막으로 전체 전략들에다가 Buy & Hold와 비교를 해봤다.

SVM은 모든 성능 지표에서 최고 성능을 달성했고 ANN의 경우 SVM보다는 살짝 낮지만 Buy & Hold보다는 모든 기간에서 우수한 성능을 보였다. kNN은 단기 예측에서만 Buy & Hold보다 우수하며 장기 예측에서는 떨어졌다.
'NLP' 카테고리의 다른 글
| [2025-1] 정유림 - Attention Is All You Need (0) | 2025.05.29 |
|---|---|
| [2025-1] 정유림 - MTEB: Massive Text Embedding Benchmark (0) | 2025.04.06 |
| [2025-1] 이루가 - GloVe: Global Vectors for Word Representation (0) | 2025.03.29 |
| [2025-1] 김학선 - LLM-Powered Code Vulnerability Repair with Reinforcement Learning and Semantic Reward (0) | 2025.03.18 |
| [2025-1] 박서형 - Gradient Episodic Memory for Continual Learning (0) | 2025.03.08 |



