
https://arxiv.org/pdf/2210.09558
Abstract
- DR screening : UW-OCTA를 사용하여 초기 DR 진단 가능
- Data collection의 어려움과 public dataset 부재로 Deep Learning based DR 분석 시스템 구축에 어려움 (Sub-par performance에 그침) → Data가 적더라도 Robust한 모델 구축 필요함
- DR analysis를 위한 empirical study 진행 : Lesion segmentation, Quality assessment, DR grading → DR analysis challenge에서 1st place 달성
- 각 model별로 robust training scheme 적용: Ensemble learning, Data augmentation, Semi-supervised learning
- Reliable pseudo labeling (RPL) : model confidence score에 따라 불확실한 label을 배제하여 noisy한 효과 제거
1. Introduction
- Diabetic retinopathy (DR, 당뇨성 망막병증) : 실명을 일으킬 수 있는 당뇨병 합병증, 조기에는 증상이 없거나 미미 → 조기 진단 및 관리 여부가 예후를 결정하는 중요 인자
- 진단 : Color fundus photography, Fluorescein angiography (FA), Optical coherence tomography angiography (OCTA)
+ UW-OCTA(ultra-wide OCTA) : 망막 혈관의 상세한 시각화, 더 넓은 망막 영역 view - Deep Learning based method의 적용 : Fundus photography의 labeled Data가 많아야 성공적 분석 가능
- Sun et al. : Color fundus image에 대해 자동 DR 분석 도구 개발
- Zhou et al. : DR grading 및 Lesion segmentation의 정확도를 높이기 위한 협력적 학습 방법 (semi-supervised learning)
- Color fundus image의 분석 모델은 많으나 UW-OCTA에 관련된 도구는 아직 개발이 덜 됨
- Labeling의 어려움 : 고화질 이미지에 대한 전문가의 manual labeling
- Data가 부족하더라도 Rubust한 model을 개발해야 하는 것이 중요
- 여러 가지 Training 기법을 도입하여 현실적으로 Training model의 성능을 높일 방법 고안
- DRAC22 dataset 사용, 3개의 tasks 수행 : Lesion segmentation, Image quality assessment, DR grading
- Data augmentation, Ensemble of DNN, Semi-supervised learning
- RPL (Reliable pseudo labeling) : Classifier's confidence score에 맞게 믿을만한 pseudo-label 선택, 그 후 classifier를 pseudolabel data로 retraining
- Deep Ensembles, Test-Time data Augmentation (TTA), RPL이 효과적, 1st place in all task for DRAC22
2. Related Work
2.1 Diabetic Retinopathy Analysis
Automatic DR assessment method : Neural network 기반, 안과의 보조용 도구
- Gulshan et al. : DR detection을 위한 CNN network, Fundus photography에서 DL-based computer aided diagnosis
- Dai et al - DeepDR : Color Fundus photography에 대한 통합적 예측 성능 (DR grade, DR-related lesion location, image quality assessment)
- Pan et al. : Fluorescein angiography에서 DR finding 감지 (non-perfusion regions, microaneurysm, laser scars)
- Heisler et al. : OCT, OCTA에서 Ensemble network for DR classification → Robust, calibrated predictions
→ DR grading 정확도의 뛰어난 결과를 보였으나 UW-OCTA에 대한 결과는 X
2.2 Semi-supervised Learning
- Labeled data를 확보하는 것은 높은 cost와 time-comsuming 때문에 어려움 → Semi-supervised learning algorithm을 통해 높은 성과를 보여줌 (semantic segmentation, object detection, image recognition)
- Pseudo-labeling (PL) : pretrained-network's prediction에 의해 형성, re-training with labeled & pseudo-labeled data
- Sohn et al. - FixMatch : Consistency network과 pseudo label을 이용하여 network가 평가한 높은 확률의 pseudo lable만 취합
- Xie et al. : Noisy student training 사용 - labeled data로 학습한 teacher network로 pseudo label 생성, 더 큰 모델을 student network로 사용하여 labeled data와 pseudo labeled data를 동시에 학습
3. Method
Scope of the paper
- 주어진 $x_{i}$에 대하여 $\hat{y_{i}}$를 분류하는 것
3.1 Reliable Pseudo Labeling
Pitfall of pseudo-labels
- Pseudo Labeling은 Data 부족 상황에서 효과적인 성능을 보이나, 부정확한 예측을 발생시켜 확증 편향을 발생시킬 가능성
- 모든 pseudo-labeled data를 수용하는 것은 위험, RPL을 통해 해결
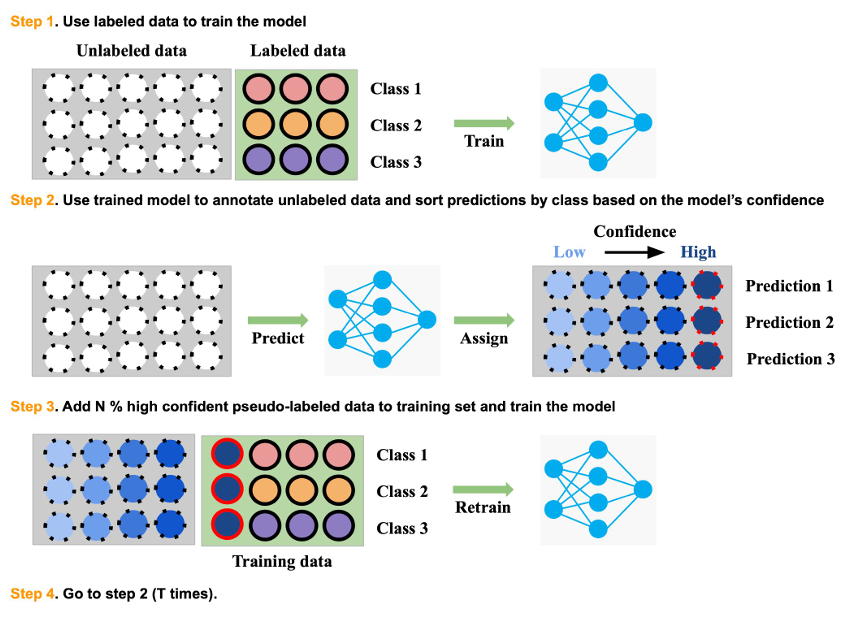
Notation
- Labeled dataset $\mathcal D^l$과 Unlabeled dataset $\mathcal D^u$에 대해 수행
- Softmax classifier $f_{cls}$는 $x_i$를 predictive distribution $\hat{p}(y|\sigma(ln f_{cls}(x_i)))$에 매치시킴
- Regression problem일 경우 $f_{reg}$는 $f_{reg}(x_i)$로 매치시킴
Procedure of RPL
- $f$를 $\mathcal D_{train}^l$로 training, class별 예측값 $\hat{ \mathcal D_k}^u$ 생성
- 각 $\hat{ \mathcal D_k}^u$를 model confidence score로 평가 : score는 $max_c \hat{p}$ 또는 $|[f_{reg}(x_i)]-f_{reg}(x_i)|^1$
- $\hat{ \mathcal D}_c ^u$에 대해 $ \mathcal N_c$%의 trust-worthy pseudo labeled sample 채택
- Retrained with labeled, trust-worthy pseudo-labeled data, 이하 $t$번 반복
3.2 Overview of Solutions

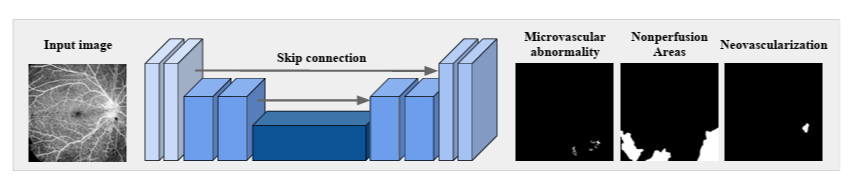
3.3 Lesion Segmentation (Task 1)
Motivation
- Pixel-level lesions detection : IRMA(Intraretinal microvascular abnormality), NP(Nonperfusion areas), NV(Neovascularization)
- Sub-optimal한 기존 모델의 performance 개선 필요, lesion 근처 해부학적 구조의 다양성 때문에 판별이 어려움
- IRMA, NV : small object로 종종 인식되어 불균등한 data distribution을 보임
- NP : signal reduction artifact와 구분이 어려움, hard example mining 필요
- Imbalanced data setting for small lesions, hard example mining의 필요성
Training
- 2개의 독립적인 U-Net model training : $f_{seg} ^{small}$ for IRMA and NV, $f_{seg} ^{NP}$ for NP
→ Predicted lesion map과 ground-truth mask 간 차이 최소화 (Dice loss와 auxiliary loss)

- Dice loss : Dice score 기반

- Auxiliary loss
- $f_{seg} ^{NP}$ : multi-label classification을 위해 Focal loss를 조정
- $f_{seg} ^{small}$ : Binary cross-entrophy loss 사용 - false positive pixel을 적게 penalize

∴ $f_{seg} ^{NP}$는 FP instance와 구별이 어려운 pixel에 대해 penalty를 주지만, $f_{seg} ^{small}$은 positive instance에 대해서만 학습
Augmentation
- $A_{pixel} = {\Omega, \Psi}$ 에 대해 randomly picked operator를 1개씩 적용
- $A^c = {\Phi}$ 에 대해 geometric transformation 적용
- 각 모델은 orginal training sample을 다시 사용하지 않음

Ensemble
- IRMA : TTA (Multiple rotated data에 대한 $f_{seg}$의 평균 예측값)
- NP : TTA를 거친 5개의 독립적 모델의 평균 예측값
- NV : TTA, MPA 사용
Post-processing
- NP : dilation operation 적용
- IRMA : $P_{NV}$가 더 정확할 경우 positive pixel($P_{IRMA}$)을 negative로 대체
- NV : $P_{IRMA}$가 더 정확할 경우 positive pixel($P_{NV}$)을 negative로 대체
3.4 Image Quality Assessment (Task 2) and DR Grading (Task 3)
Motivation
- UW-OTCA의 quality를 구별(PQL, GQL, EQL)하고 DR severity(normal, NPDR, PDR)를 평가하기 위함
- Regression problem으로 간주 : class 간 연관도를 알아보기 위함
Training
- $f_{reg}$를 EfficientNet-b2 pretrained model로 선택
- RPL 적용, DRAC22를 test set으로 적용
Augmentation
Task 1과 동일하나, operator가 다름


Ensemble
5개 독립 모델의 예측값 평균 사용, TTA with flip operator
Post-processing
1) Task 2 : $f_{reg}$ 값에 따라 threshold 결정

2) Task 3
- PDR lesion이 작을 경우 NV region이 무시당함 : NPDR로 오분류하는 문제, NV prediction mask segmentation을 이용해 PDR로 고침
- Task 1의 모든 Class에 대해 normal으로 판정될 경우 DR grading을 normal로 변경

4 Experiments
4.1 Dataset and Metrics
Dataset
- DRAC22
- 3 tasks에 대해 수행
- 20% validation dataset, Validation loss가 제일 낮은 model 확정
- Task 1은 모든 학습 smaple 사용, Dice score 가장 높은거

Metrics
- Task 1 : mean-DSC, mean-IoU
- Task 2, 3 : QWK, AUC
4.2 Results
Task 1
Ensemble을 결합하고 post-processing이 segmentation task에 도움

Task 2
RPL 추가 시 눈에 띄는 변화

Task 3
post-processing이 가장 두드러지는 변화 : NV 영역의 크기에 따라 분류 방법이 달라지며, 정상 샘플에서 artifact를 활성화할 경우 DR grading이 바뀜



5. Conclusion
- UW-OCTA를 이용한 DR analysis system 구현
- Ensemble learning, RPL, TTA는 basline보다 높은 성능을 보이며, 특히 RPL은 Data가 부족한 상황에서 상당한 극적 향상을 보임
- DRAC22에서 1st place 달성, UW-OCTA 연구를 활성화하고 강력한 benchmark가 되어 DR 진단 및 screening에서 많은 이점이 되기를 기원



