
https://arxiv.org/pdf/2305.10415v6
Abstract
- MedVQA를 생성(generative) 문제로 재구성하여 인간-기계 상호작용을 자연스럽게 구현
- Pre-trained vision encoder와 LLM을 결합한 생성 기반 모델 제안
- PMC-VQA dataset 구축 : Image - Q&A pair로 구성된 VQA로 다양한 medical modality를 다룸
- Model 성능 평가 : PMC-VQA에서 훈련 후 VQA-RAD, SLAKE, Image-Clef-2019 benchmark에서 fine-tunning, 기존 MedVQA 모델보다 더 정확하고 적절한 답변 생성.
- Test set 제시 : manual verification을 거친 새로운 test set 제안하여 모델 성능을 더욱 철저히 평가.
- PMC-VQA는 의료 VQA 연구에 중요한 데이터셋으로 자리 잡고, MedVInT 모델은 MedVQA 분야에서 큰 진전을 이룸.
1. Introduction
LLM의 의료 자연어 처리 분야에서 성공 : 언어 이해에 뛰어나지만 visual content를 input으로 받는 데 한계
→ Medical visual content 해석이 필요한 MedVQA 분야에서 한계가 뚜렷
MedVQA (Medical Visual Question Answering) : 의료 이미지 이해, 해석 후 관련 질문에 대한 답변을 제공하는 시스템 개발
- AI를 의료 전문 지식과 통합하여 healthcare 결과, 환자 치료, 의학 분야에 영향
기존 방식에서는 제한된 선택지 중 정답을 분류하는 작업으로 취급, 제한된 사례에서만 유용
→ 자유형 답변 생성 모델인 Open-ended MedVQA 제안
기존 visual-language representation learning (ex. Flamingo, BLIP)은 의료 시나리오의 복잡하고 미묘한 visual concept에 의해 적용이 제한적이라는 한계
기존 Dataset의 size 문제를 해결하기 위해, 대규모 medical visual-language dataset를 구성하고 확장가능한 자동 pipeline 구성
PMC-VQA : 149k image의 227k VQA 쌍 포함, 방사선 이미지의 80% 포괄 - 양과 다양성 측면에서 향상
MedVInT : Generative visual-language model
- PMC-VQA training set 사용
- 기존 public bnechmark (VQA-RAD, SLAKE, ImageClef-VQA-2019) fine-tuning
- 높은 정확도, 개발 잠재성
Contibution
- MedVInT : MedVQA의 문제를 generative learning task로 재구성, Visual instruction tuning을 통해 pre-trained vision encoder를 LLM과 정렬하여 얻은 모델
- PMC-VQA : 확장 가능한 pipeline 및 large-scale MedVQA dataset, 다양한 modality와 질병 포함
기존 dataset의 크기와 다양성 확장 - Fine-tune : PMC-VQA에서 MedVInT pre-training 후 VQA-RAD, SLAKE에 적용
SOTA performance, 기존 모델 능가 - Evaluation : 새로운 test set 제안, 어려운 benchmark 제시하여 VQA 성능 평가
2. Results
MedVInT(Medical Visual Instruction Tuning)
- MedVQA 수행을 위해 PMC-VQA 조직화 : Dataset 포괄적 분석 및 비교
- Trained model 평가 지표 : MedVQA benchmark
- 새로운 평가 지표인 MedVQA benchmark 설정, Framework를 통한 pre-trained model 평가
2.1 Data Analysis
- 227k개 image-question pairs
- Image의 광범위한 다양성 : 기존 MedVQA dataset보다 크기, modality 다양성 측면에서 뛰어난 성능
- 다양한 난이도의 질문 : Image modality, perspective, organ 식별부터, 전문적 지식 판단이 필요하거나 sub-figure를 가려내는 능력을 요구하는 질문까지
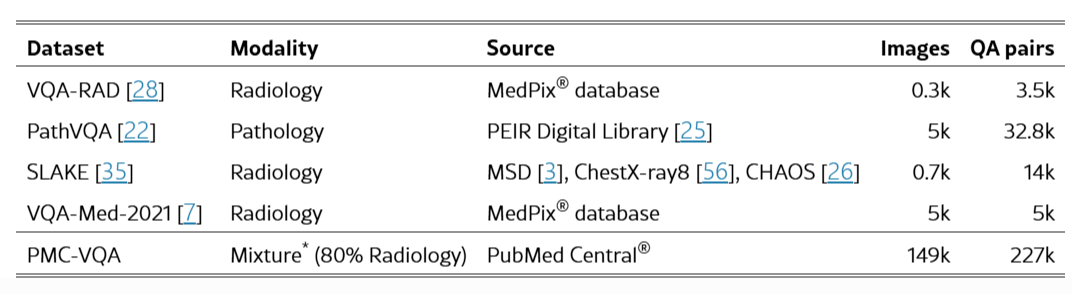
- Images : 다양한 유형, Radiology에서 signal까지
- Questions : 다양한 질문 유형 (차이점, 영상 유형, 영상 특징 등), 5~15개 단어 범위
- Answers : 위치 설명, image modality, 특정 해부학적 영역에 대한 서, 5 단어 내외

2.2 Evaluation on Public Benchmarks
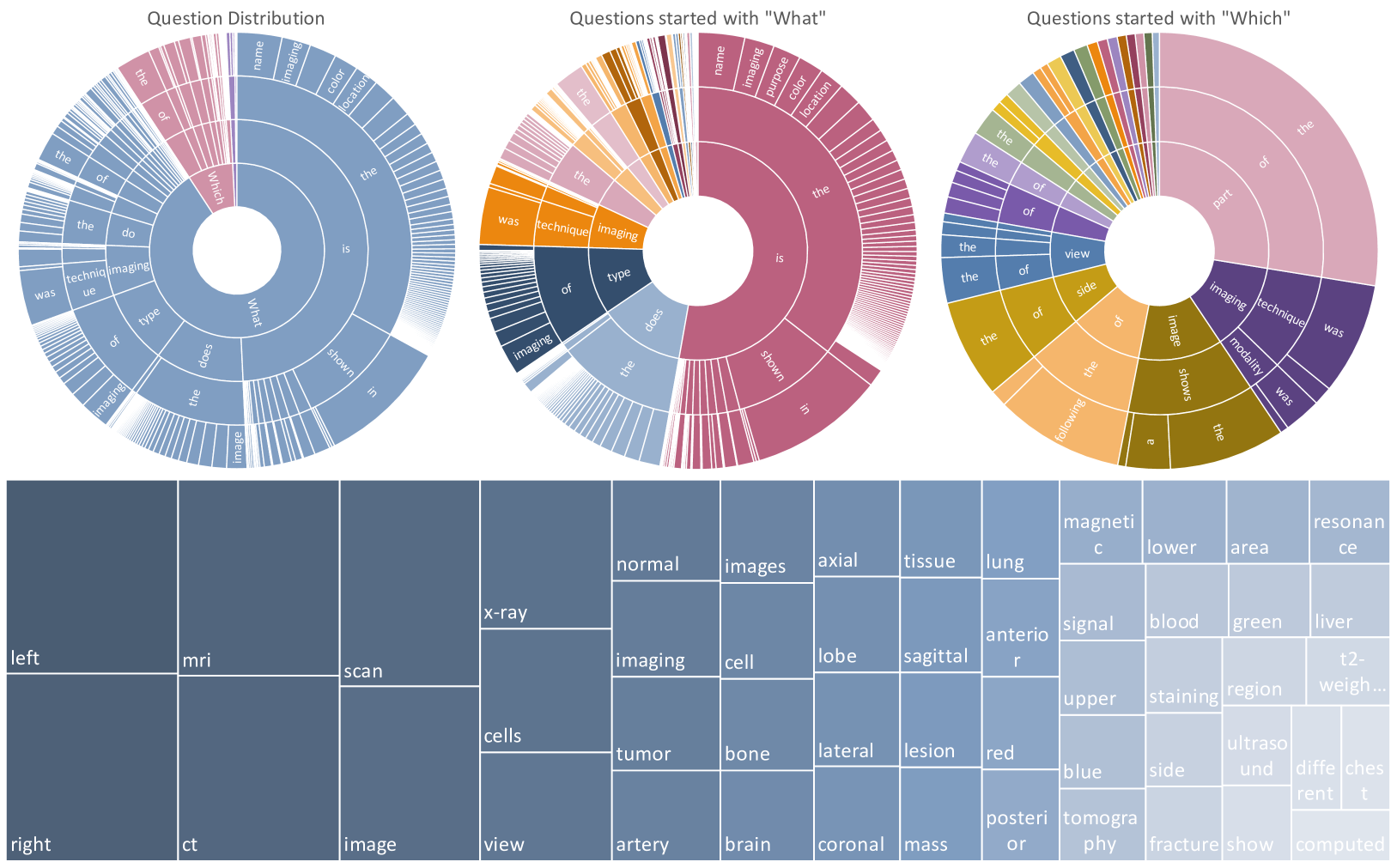
- 기존 MedVQA benchmark인 VQA-RAD, SLAKE, ImageClef-VQA-2019로 MedVInT 성능 평가
- MedVInT-TE, MedVInT-TD version 모두 VQA-RAD, SLAKE dataset에서 최고 성능 달성
- PMC-CLIP을 visual backbone, PMC-LLaMA를 language backbone으로 사용 시 최고 성능을 달성
- 질문 유형별 평가 : 개방형, 폐쇄형 질문 모두 정확도 향상
- Architecture별 비교 : Pre-train없이 학습한 MedVInT-TE-S, MedVInT-TD-S 모두 이전 architecture인 M3AE, PMC-CLIP 능가
- 사전학습 유무 : 사전학습된 모델 (MedVInT-TE, MedVInT-TD)에서 사전학습 없는 모델(MedVInT-TE-S, MedVInT-TD -S)보다 정확도 증가

2.3 Evaluation on PMC-VQA
PMC-VQA-test : 새로운 MedVQA benchmark, Blanking(개방형), Choice(선택형) 작업에 대해 다양한 모델 평가 용도
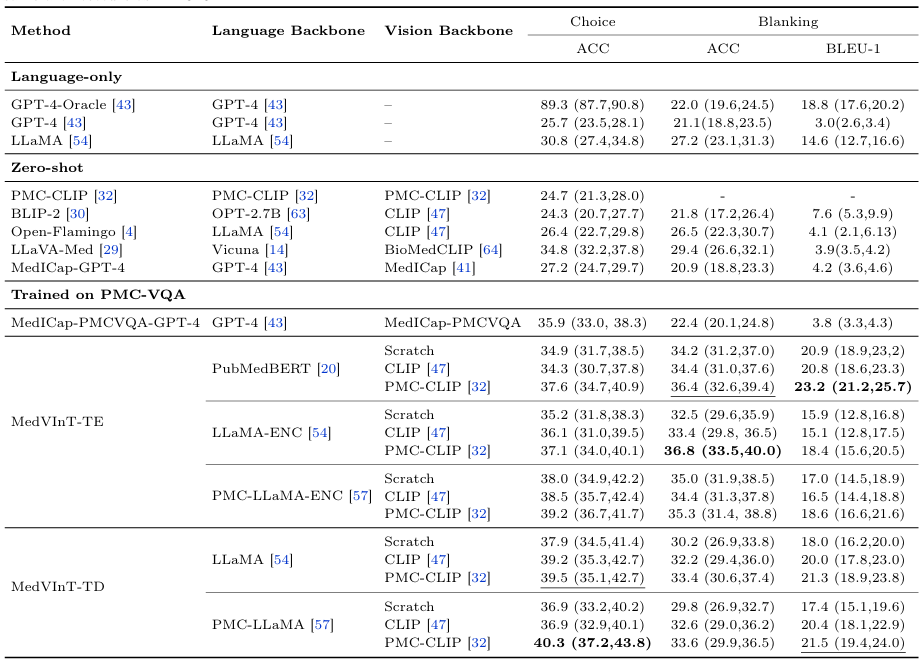
1. Language-only model별 비교
- GPT-4-Oracle : GPT-4를 이용해 논문의 image caption을 기반으로 답변, 모델 성능의 상한
- Language-only model에서 무작위적인 결과, 정확도가 떨어짐
- Blanking에서 특정 선택지와 올바르게 매치되지 않는 긴 문장 출력 경향
- Choice에서 추측만으로 나올 수 있는 최대 정답율과 동일한 정확도
- Multimodal 이해의 중요성, Image-question 관계성 강조
- 다른 training set과 다르게 PMC-VQA-test는 철저한 manual checnking을 거쳐 평가 신뢰성 보장, PMC-VQA-test-initial test set 추가 제공
2. Zero-shot
- 일반 VQA model(PMC-CLIP, BLIP-2, Open-Flamingo)은 Choice task에서 상대적으로 낮은 성능
- Medical-specific VQA (LLaVA-Med) : 일반 모델보다 우수하나, MedVInT보다 뒤쳐짐
3. Trained on PMC-VQA
- PMC-CLIP vision backbone과 결합 시 뛰어난 성능 : MedVInT-TE + PMC-CLIP + PubMedBERT에서 최고 성능
- Pre-trained되지 않은 Scratch보다 Domain-specific pre-trained PMC-CLIP을 사용 시 더 좋은 성능을 보이는 경향
4. 2 stage VQA model과 비교
- 2단계 VQA 방법(ChatCAD 방식, MedICap) : Image captioning 후 LLM을 통해 질문에 대답
- Zero-shot, PMC-VQA training 후 둘 다 정확도가 떨어짐 : Caption과 question 간 focus 차이가 원인

2.4 Evaluation of Visual Backbone Performance
- Visual backbone의 성능과 개선 사항 확인, MedMNIST dataset에서 모델 평가
- 3가지 MNIST 모두에서 MedVInT가 경쟁력 있는 성능
- CLIP 스타일 학습에 비해 VQA 기반 pre-training의 효과 : 더 깊은 컨텐츠 이해도 목표

3. Discussion
VQA model의 낮은 정확도 개선의 필요성 (무작위 추측과 비슷한 정도)
MedVInT : Pretrained Vision encoder의 visual data를 Language model과 정렬 → SOTA 달성
PMC-VQA pipeline : 다양한 modality와 질병을 커버할 확장 가능한 파이프라인 제시 → 다양한 method 평가를 위한 새롭고 신뢰할 수 있는 benchmark
Medical Imaging Ecosystem을 위한 Medical VQA의 중요성
- Radiologist, Referring physicians : 강력한 의사결정 지원 도구로써 진단 정확도 향상, 영상 해석 프로세스 간소화 → 임상적 workflow 효율화 및 환자 치료에 더 많은 시간 할애
- Patient : 복잡한 medical information 전달 개선, 환자의 이해도 및 치료 과정 참여 강화, patient-centered care와 공동 의사 결정
- 연구, 교육 : 대학생, 연구자에게 interactive learning 경험, 연구 계획 설계, medical imaging concept에 대한 통찰, 의학 지식과 기술 개발 기여
Medical VQA Domain에 귀중한 자원으로써의 PMC-VQA
- 다양하고 복잡한 VQA requirement 해결하는 광범위한 리소스 제공
- 의료영상에 대한 이해, 해석 모델 개발에 용이
- Pre-training을 통해 심층적 이해 향상 : Generative MedVQA system 개발의 주요 과제 해결
일반적인 Visual-language model의 MedVQA 영역에서 한계성
- 기존 Multimodal model (BLIP-2, Flamingo) 는 질답에서 문제 발생 : dataset와 biomedical relevance의 특수성
- PMC-VQA-train dataset이 Generative MedVQA system 개발에서의 중요 역할 강조
MedVInT의 Generative MedVQA SOTA 달성
- MedVInT-TE와 MedVInT-TD 모두 좋은 성과 달성, Generative model backbone 변화와 연관지어 비교
- Specialized medical visual backbone 대체 시 성능 향상, visual understanding의 중요성
- Domain-specific language backbone 사용 시에도 미세하게 성능이 개선되는 결과
- 개방형 질문에서 성능 향상 효과 두드러짐, benchmark별 효과 차이 (VQA-RAD는 긴 답변의 MedVInT-TD, SLAKE는 짧은 응답의 MedVInT-TE에서 강점)
PMC-VQA-test - Challenging Benchmark
- 이전 medical multimodal SOTA model인 PMC-CLIP도 어려움을 겪는 benchmark (blanking, multi-choice형 문항에서 무작위 추측과 비슷한 정확도)
- PMC-VQA-test benchmark의 어려운 난이도, VQA 모델에 대한 엄격한 평가 지표, 추가 개선 사항 여지 남아있음
Impacts
- PMC-VQA dataset의 빠른 채택과 광범위한 활용, 수많은 생성 모델 개발을 위한 기초 리소스, 다양한 작업에 영향
- Dataset 구성 방법론과 전략이 몇몇 작업에 영향
- MedVInT가 선구적인 medical generative foundation model로 인식되고 있으며, Robustness와 utility, scientific community에서의 역할 강조 중
Limitation
- 잠재적 분포 편향 : 임상 환경 비교 시 데이터가 단순할 가능성, 하지만 실제 임상 이미지를 더 잘 이해하는 데 여전히 중요한 역할
- 평가 지표의 한계 : ACC와 Bleu score가 문장 유창성을 반영하지 못함 (단순 문자열 유사성), 향후 더 정확하고 효과적인 평가 지표 필요
- 생성 모델 한계 : hallucination 문제 발생, VQA proof-of-concept 단계로 간주되며 추가 연구 필요
4. Method
4.1 The PMC-VQA Dataset
- Multimodal MedVQA dataset 부족이 모델 개발의 중대한 장애물
- Dataset 수집 프로세스, dataset을 다양한 관점에서 분석하여 속성과 잠재적 응용분야 소개
Source data
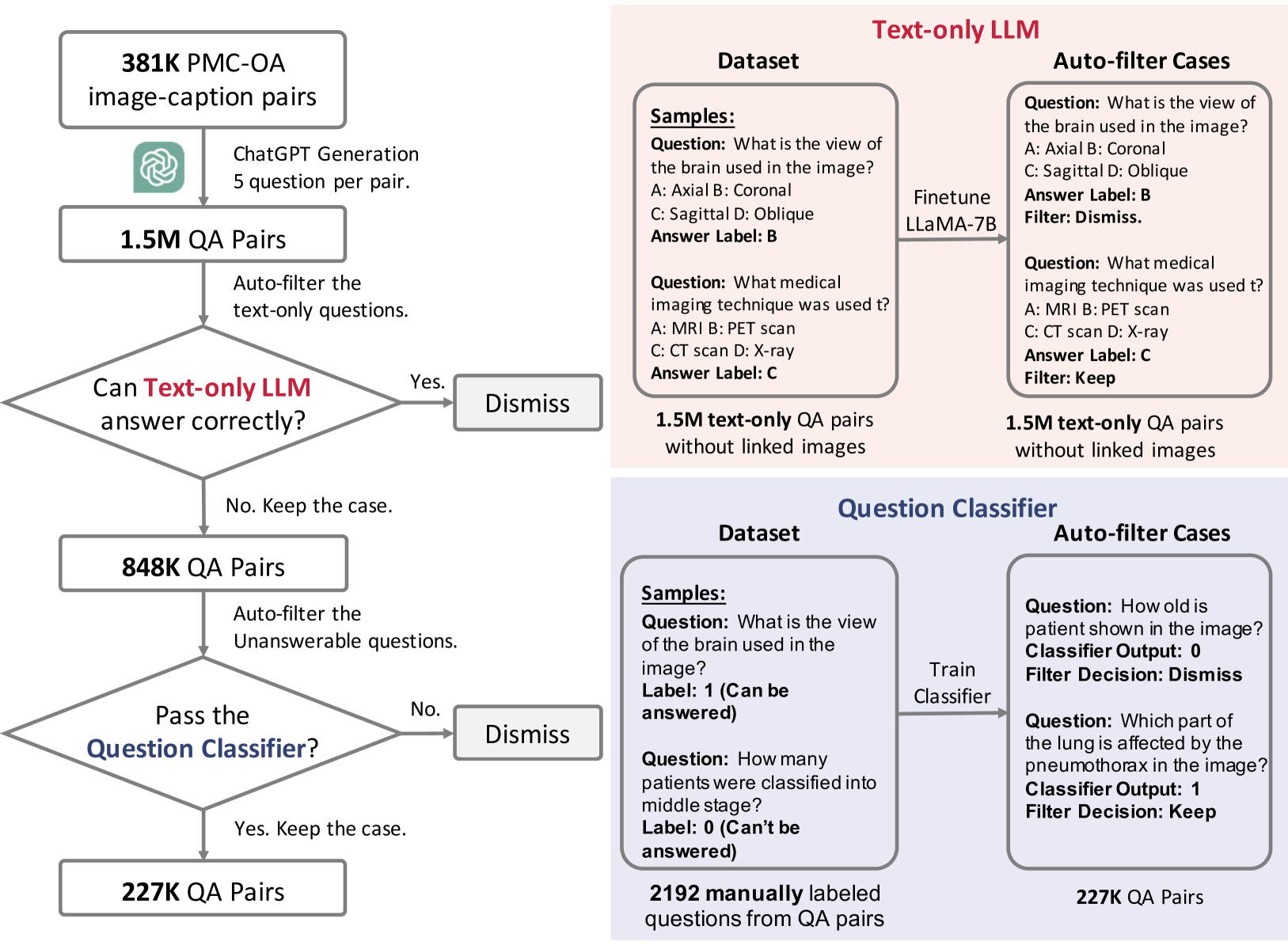
- PMC-OA; PubMedCentral OpenAccess에서 수집한 image-caption text pair (381K)
Question-Answer Generation
- PMC-OA의 image caption을 Chat-GPT에 입력한 후 각 caption별 5개의 Question-Answer pair 생성 (1.5M)
- 각 content별 5개의 질문, 4개의 선택지, 각 QA pair는 caption의 image와 연결
- 다양한 주제를 포괄하는 고품질의 질문 대량 생성, Filtering process를 통해 포맷 요구사항 충족 여부 확인
Automatic & Manual Data Filtering
- 단순 language model만으로 답변 가능한 질문 제거 : LLaMA-7B 이용 (848K)
- Image 기반하여 답변 불가한 질문 제거 : Question classifier model을 학습시켜 적용
- PMC-VQA dataset 완성 : 149,075개 image, 226,946개 QA pair
PMC-VQA-test-initial : 50,000개의 image-question pair 무작위 선택, training set와 다른 image
PMC-VQA-test : Manual로 test sample을 검사하여 2K의 정리된 test set
→ 질문과 이미지 관련성, 오답 선지의 난이도, image 품질 및 포함된 정보 등 고려
4.2 Architecture Design
4.2.1 Problem Formulation
- MedVQA는 medical visual content에 대한 자연어 질문에 답하는 작업, 주어진 질문에 대한 해당 답변을 출력할 수 있는 모델 학습
- 기존 방식에서는 VQA를 classification 문제로 처리(후보 집합에서 정답 선택) → 미리 정의된 결과로 제한하여 자유형 상호작용 잠재력 방해
- 개방형 답변 생성 목표, 실제 정답 생성 확률을 최대화하여 다양하고 유익한 답변 및 광범위한 시나리오 생성


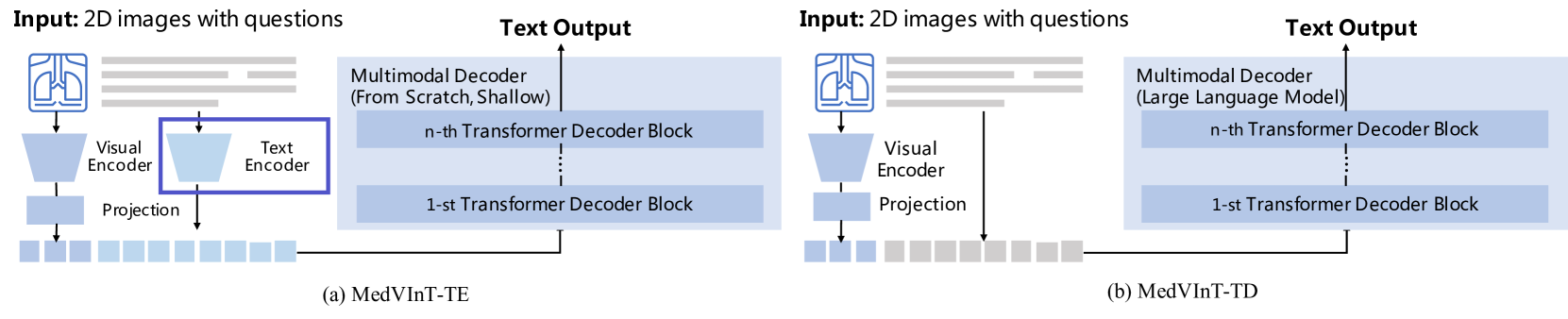
4.2.2 MedVInT-TE
Visual Encoder : Image input에 대한 embedding
PMC-CLIP에서 채택한 pre-trained ResNet-50 기반
Projection module : MLP-based, transformer-based variant 존재
Text Encoder : Question에 대해 prompt를 설정하고 text embedding
Pre-trained language model 사용
개방형, 폐쇄형 질문에 알맞게 prompt 변형
Multimodal Decoder : Visual embedding과 question embedding을 concatenate
4-layer transformer 구조, Scratch (Pre-training X)
Mask language modeling 작업 : Question input에 여러 개의 mask token padding, masked token에 대한 예측 생성
4.2.3 MedVInT-TD
Visual Encoder는 MedVInT-TE와 동일
Text Encoder : Simple tokenization embedding layer (GPT-like LLM 방식)
LLaMA, PMC-LLaMA 등 pre-trained LLM의 구조 사용
개방형, 폐쇄형 질문에 알맞게 prompt 변형
Multimodal Decoder : pre-trained weight가 존재하는 transformer decoder-based LLM
PMC-OA로 전체 네트워크 pre-training : Image encoding space의 gap을 줄이기 위함
4.3 Datasets and Backbones
4.3.1 Existing MedVQA Datasets
- VQA-RAD : Radiology를 위해 특별히 설계된 VQA dataset
- SLAKE : 영어-중국어 이중언어 VQA dataset, 영어만 사용
- ImageClef-VQA-2019 : MedPix image 기반 VQA dataset, 질문을 modality, plane, organ system, abnormality 4개 유형 분류
4.3.2 Proposed PMC-VQA Dataset
- Multi-choice Answering : 4개의 선택지가 prompt로 제공, 올바른 선택지를 고르는지 ACC score로 평가
- Open-ended Answering : 기존 VQA 선택형 접근 극복, Input option 없이 직접 answer 생성, Bleu, ACC score로 평가
Flamingo, BLIP-2 등 CV분야의 강력한 Generative model과 비교 (Zero-shot evaluation)
4.3.3 Pre-trained Backbones
Pre-trained된 Language, Visual backbone으로 구분
기본적으로 의료 데이터에 적합하다 알려진 PMC-LLaMA 및 PMC-CLIP을 backbone으로 사용
Visual backbone
- CLIP : 12개 transformer layer가 있는 ViT-base-patch32 version을 pre-trained visual encoder로 사용
- PMC-CLIP : CLIP 구조 기반 medical-specific visual model, PubMed 논문에서 수집한 image-text pain data 활용
→ medical image와 text 처리에 특별히 설계
Language backbone
- LLaMA : SOTA LLM, 32개 transformer layer로 구성된 7B version Language backbone
- PMC-LLaMA : LLaMA-7B을 biomedical 논문에 대해 fine-tuning, 강력한 fitting 가능과 medical task에서 뛰어난 성능
- PubMedBERT : PubMed 초록과 PubMedCentral article를 사용하여 학습된 BERT 유사 모델, 뛰어난 text-embedding
- LLaMA-ENC, PMC-LLaMA-ENC : LLaMA와 PMC-LLaMA에서 full attention mask 전달 및 embedding sampling을 통해 encoder model로 활용, BERT 유사 모델과 직접적 비교 가능
4.3.4 Implementation Details
: training setting 및 구현 방법 설명
4.3.5 Baseline Methods
Established generative model
- Open-Flamingo : DeepMind 최첨단 모델 Flamingo Open-source version, Zero-shot evaluation을 위해 공개된 checkpoint 사용
- BLIP-2 : Flamingo를 능가하는 visual-language generative model, Zero-shot evaluation을 위해 공개된 checkpoint 사용
다양한 medical VQA model 중 SOTA approaches
- Hanlin : VQA-Med 2019 task에 참여한 팀 중 가장 좋은 결과, public leaderboard 결과 차용
- MEVF-BAN : Unsupervised denoising auto-encoder와 supervised Meta-Learning을 결합한 framework, PMC-CLIP에서 보고한 finetuned 결과 활용
- CPRD-BAN : 2 stages pre-training framework (Radiologt images에서 전이가능한 feature 학습 + compact visual featrue extractor distilling), PMC-CLIP에서 보고한 finetuned 결과 활용
- M3AE : Multimodal masked autoencoder를 이용한 Self-supervised learning 접근법, PMC-CLIP에서 보고한 finetuned 결과 활용
- PMC-CLIP : Zero-shot setting의 VQA task 수행을 위해 imaging embedding을 가장 유사한 QA pair text embedding과 매칭하여 정확도 계산
4.3.6 Evaluation Metrics
- BLEU-1 : 참조 텍스트와 비교하여 single word나 unigram의 정확도에 초점
- ACC : 전체 질문 수에서 정답을 맞춘 질문의 백분율, 문장 요소의 sequence 비교, 유사점과 차이점 찾기
5. Conclusion
- MedVQA의 문제를 human-machine interaction을 반영하는 generative task로 반영
- Pre-trained vision encoder를 통해 medical visual understanding 수행
- PMC-VQA dataset을 활용한 pipeline 제시, SOTA 달성 및 다양한 model을 평가할 benchmark 제시



