
손실 함수 (Loss Function)
신경망 학습에서는 현재의 상태를 '하나의 지표'로 표현한다. 그리고 그 지표를 가장 좋게 만들어주는 가중치 매개변수의 값을 탐색하는 과정을 거친다.
신경망 학습에서 사용하는 지표는 손실함수라고 한다. 이 손실함수는 임의의 함수를 사용할 수도 있지만 일반적으로는 평균 제곱 오차와 교차 엔트로피 오차를 사용한다.
즉, 손실함수는 현재의 신경망이 훈련 데이터를 얼마나 잘 처리하지 못하느냐를 나타낸다. 때문에 손실함수의 값은 낮을수록 좋다.
평균 제곱 오차 (mean squared error)
평균 제곱 오차의 수식은 아래와 같다.
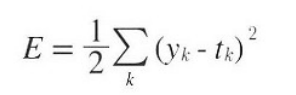
여기서 y는 신경망의 출력(신경망이 추정한 값),. t는 정답 레이블, k는 데이터의 차원 수를 나타낸다.
아래와 같은 원소 10개의 데이터가 있다고 하면

신경망의 출력 y는 소프트맥스 함수의 출력이고, 이 예에서는 이미지가 0일 확률은 0.1, 1일 확률은 0.05, 2일 확률은 0.6이라고 해석된다. 한편 정답 레이블인 t는 정답을 가리키는 위치의 원소는 1로, 그 외에는 0으로 표기한다.
여기에서는 숫자(인덱스) '2' 에 해당하는 원소의 값이 1이므로 정답이 '2'임을 알 수 있고 추정값 또한 정답값에서 가장 높은 수치를 나타낸다.
이처럼 정답인 한 원소만 1로하고 그 외에는 0으로 나타내는 표기법을 원-핫 인코딩이라 한다.
평균 제곱 오차를 파이썬으로 구현하면 다음과 같다.
def mean_squared_error(y,t):
return 0.5*np.sum((y-t)**2)
여기에서 인수 y와 t는 넘파이 배열이고 위 식을 그대로 구현한 코드이다.
이 함수를 실제로 사용해보면
t = [0, 0, 1, 0, 0, 0, 0, 0, 0, 0]
# 예1
y = [0.1, 0.05, 0.6, 0.0, 0.05, 0.1, 0.0, 0.1, 0.0, 0.0]
# 예2
y = [0.1, 0.05, 0.1, 0.0, 0.05, 0.1, 0.0, 0.6, 0.0, 0.0]
mean_squared_error(np.array(y), np.array(t))예1 출력결과

예2 출력결과

두 가지의 예 중에서 첫번쨰의 예는 정답이 '2'이고 신경망 출력도 '2에서 가장 높은 경우이다. 두번쨰 예에서는 정답은 같지만 신경망 출력은 '7'에서 가장 높다. 이 실험의 결과로 첫 번쨰 예의 손실 함수 쪽 출력이 작으며 정답 레이블과의 오차도 작은 것을 알 수 있다. 즉 첫 번쨰 추정 결과가 오차가 더 작으니 정답에 더 가깝다고 판단할 수 있다.
교차 엔트로피 오차
또 다른 손실함수로서 교차 엔트로피 오차도 자주 이용한다. 교차 엔트로피 오차의 수식은 다음과 같다.
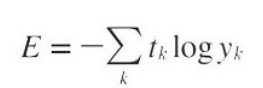
여기에서 log는 밑이 e인 자연로그이다. y는 신경망의 출력, t는 정답 레이블이다.
또 t는 정답에 해당하는 인덱스의 원소만 1이고 나머지는 0이다(원-핫 인코딩).
그래서 실질적으로 정답일 떄의 추정의 자연로그를 계산하는 식이 된다.
예를 들어 정답 레이블은 '2'가 정답이라고 하고 이때의 신경망 출력이 0.6이면 교차 엔트로피 오차는
-log0.6 = 0.51이 된다. 또한, 같은 조건에서 신경망 출력이 0.1이라면 -log0.1 = 2.30이 된다.
( 자연로그(ln)는 밑이 e = 2.718이고 -log0.6 실제 값을 계산해보면 0.51, 근사식 이용하고 그러는데 계산기가 짱...)
이 말은, 신경망이 0.1이라는 값을 출력했을 때 훨씬 더 큰 오차를 가지게 된다는 뜻이다.
즉, 교차 엔트로피 오차는 정답일 때의 출력이 전체 값을 정하게 된다.

이 그림에서 보듯이 x가 1일 때 y는 0이 된다. 즉, x가 0에 가까워질수록 오차 값 y는 점점 작아져서 0에 수렴한다.
위 교차 엔트로피 식도 마찬가지로 정답에 해당하는 출력이 커질수록 0에 다가가가다가, 그 출력이 1일 떄 0이 된다. 반대로 정답일 때의 출력이 작아질수록 오차는 커진다.
*y값 음수인 이유 - 로그 함수 y=lnxy = \ln x 는 입력 xx 가 1보다 작을 때, 항상 음수 값 을 가진다.
교차 엔트로피 오차를 구현하면 다음과 같다.
def cross_entropy_error(y,t):
delta=1e-7
return -np.sum(t*np.log(y+delta))여기에서 y와 t는 넘파이 배열이다. 그런데 코드 마지막을 보면 np.log를 계산할 떄 아주 작은 값인 delta를 더했다. 이는 no.log()함수에 0을 입력하면 마이너스 무한대를 뜻하는 -inf가 되어 더 이상 계산할 진행할 수 없기 때문이다.
마이너스 무한대가 발생하지 않도록 처리한 것이다.
위 MSE처럼 함수로써 계산을 해보면 아래와 같다.
예1
# 정답값
t = [0, 0, 1, 0, 0, 0, 0, 0, 0, 0]
# 예 1
y = [0.1, 0.05, 0.6, 0.0, 0.05, 0.1, 0.0, 0.1, 0.0, 0.0]
cross_entropy_error(np.array(y), np.array(t)).

예2
# 예 2
y = [0.1, 0.05, 0.1, 0.0, 0.05, 0.1, 0.0, 0.6, 0.0, 0.0]
cross_entropy_error(np.array(y), np.array(t))
첫 번쨰 예는 정답출력이 0.6인 경우고 이떄의 교차 엔트로피 오차는 약 0.51이다.
그 다음은 정답일 떄의 출력이 더 낮은 0.1이고, 교차 엔트로피 오차는 무려 2.3이다.
즉, 결과(오차 값)가 더 작은 첫 번째 추정이 정답일 가능성이 높다고 판단한 것으로, 앞서 평균 제곱 오차의 판단과 일치한다.
미니배치 학습,
지금까지는 데이터 하나에 대한 손실 함수만 생각해왔으나, 훈련 데이터 모두에 대한 손실함수의 합을 구하는 방법으로의 교차 엔트로피 오차는 아래와 같다.
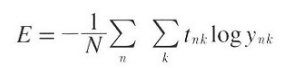
식을 보면 단순히 N개의 데이터로 식을 확장했을 뿐이다. 다만 마지막에 N으로 나누어 정규화하고 있다.
이렇게 평균을 구해 사용하면 훈련 데이터가 1000개든 10000개든 상관없이 평균 손실 함수를 구할 수 있다.
하지만, 훈련 데이터가 많아진다면 일일이 손실 함수를 계산하는 것은 현실적이지 않다.. 따라서 미니배치 학습 기법을 이용한다. 예를 들면 MNIST 데이터 셋의 60000장의 훈련 데이터 중 100장만을 무작위로 뽑아 학습하는 것이다.이를 미니배치 학습이라고 한다.
미니배치 학습을 구현하는, 즉 훈련 데이터에서 지정한 수의 데이터를 무작위로 골라내보자, 그전에 MNIST데이터셋을 읽어오는 코드는 다음과 같다.
import sys, os
sys.path.append('/content/drive/MyDrive/outtaDeepLearning')
import numpy as np
from dataset.mnist import load_mnist
(x_train, t_train), (x_test, t_test) = \
load_mnist(normalize=True, one_hot_label=True)
print(x_train.shape) # (60000, 784)
print(t_train.shape) # (60000, 10)
load_mnist함수는 MNIST 데이터셋을 읽어오는 함수이다. 이 함수는 훈련 데이터와 시험 데이터를 읽는다. 또한, one_hot_label=True로 원핫 인코딩을 사용한다.
코드를 읽은 결과로 60,000개의 훈련 데이터와 입력 데이터는 784열인 이미지 데이터임을 알 수 있다.
( 각 이미지는 28×28 픽셀 크기의 흑백 이미지)
또 정답 레이블은 10줄짜리 데이터가 된다.
np.random.choice() 함수를 쓰면 지정한 범위의 수 중에서 무작위로 원하는 개수만 꺼낼 수 있다.
train_size = x_train.shape[0]
batch_size = 10
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]위 예시에서는 전체 0부터 59999까지(60000미만)의 인덱스 중 10개의 인덱스를 랜덤으로 뽑고 있다.
(배치용) 교차 엔트로피 구현
def cross_entropy_error(y, t):
if y.ndim == 1:
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
batch_size = y.shape[0]
return -np.sum(t * np.log(y + 1e-7)) / batch_size
가 1차원 데이터인 경우는 reshape 함수로 데이터의 형상을 바꿔준 후, 배치 크기로 나눠 정규화하고 이미지 1장당 평균의 교차 엔트로피 오차를 계산한다.
정답 레이블이 원핫 인코딩이 아닌, '2'나 '7'등의 숫자 레이블로 주어진 경우의 교차 엔트로피는 아래와 같이 구현 가능하다.
def cross_entropy_error(y,t):
if y.ndim == 1:
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
batch_size = y.shape[0]
return -np.sum(np.log(y[np.arange(batch_size), t] + 1e-7)) / batch_size
이 구현에서는 원핫 인코딩일 떄 t가 0인 원소는 교차 엔트로피 오차도 0이므로, 그 계산은 무시해도 좋다는 것이 핵심이다.
왜 손실 함수를 설정하는가?
앞서 진행한 숫자 인식의 경우도 마찬가지로 우리의 궁극적인 목적은 높은 '정확도'를 끌어내는 매개변수 값을 찾는 것이다.
그렇다면 정확도라는 지표를 놔두고 손실함수의 값이라는 우회적이 지표를 사용하는 이유는 뭘까?
이 의문은 신경망 학습에서의 '미분'의 역할에 주목한다면 해결된다.
신경망 학습에서는 최적의 매개변수(가중치와 편향)을 탐색할 떄 손실 함수의 값을 가능한 한 작게 하는 매개변수 값을 찾는다.
이떄 매개변수의 미분(정확히는 기울기)를 계산하고, 그 미분 값을 단서로 매개변수의 값을 서서히 갱신하는 과정을 반복한다.
미분 값이 음수나 양수면 각 반대 방향으로 전환시켜 손실 함수의 값을 줄일 수 있다.
그러나 미분 값이 0이면 가중치 매개변수를 어느 쪽으로 움직여도 손실 함수의 값은 달라지지 않는다.
그래서 그 가중치 매개변수의 갱신은 거기서 멈춘다.
미분 값이 0이면 가중치 매개변수를 어느 쪽으로 움직여도 손실 함수의 값은 달라지지 않는다. 그래서 그 가중치 매개변수의 갱신은 거기서 멈춘다.
즉, 정확도를 지표로 삼아서 안되는 이유는 미분 값이 대부분의 장소에서 0이 되어 매개변수를 갱신 할 수 없기 때문이다.
정확도는 단순히 맞춘 개수의 비율을 의미한다.
예를 들어, 100개의 샘플 중 85개를 맞췄다면 정확도는 85% (0.85) 이다.
정확도를 지표로 삼으면 매개변수의 미분이 0이 되는 이유는 정확도는 매개변수의 미묘한 변화에는 거의 반응하지 않고, 반응이 있더라도 불연속적으로 갑자기 변화한다. 이는 계단 함수를 할성화 함수로 사용하지 않는 이유와도 들어맞는다.
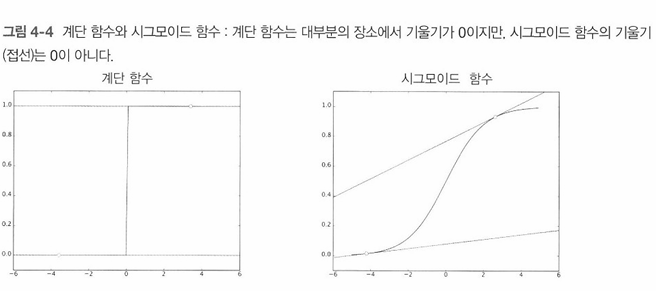
계단 함수와 비교해 시그모이드 함수의 미분은 출력값과 기울기가 연속적으로 변한다. 즉, 어느 장소라도 0이 되지는 않는다.
*손실함수의 정확도와 경사하강법과의 관계
경사 하강법(Gradient Descent)은 손실 함수의 미분(기울기, gradient)을 이용해서 모델을 업데이트하는 최적화 알고리즘이다.
즉, 손실 함수가 연속적이고 미분 가능해야 경사 하강법을 사용할 수 있다. 손실함수에서 정확도 사용불가 이유와 유사.
퀴즈
1. 교차 엔트로피 오차(Cross Entropy Error, CEE)의 특징으로 올바른 것은? 그리고 올바른 이유는?
① 예측 값이 정답과 가까울수록 손실이 증가한다.
② 예측 값이 1에 가까울수록 손실 값이 커진다.
③ 정답에 해당하는 출력이 1이면 손실 값은 0이 된다.
2. 손실 함수(Loss Function)의 주요 목적은 무엇인가?
① 신경망의 가중치를 무작위로 초기화하기 위해
② 모델의 예측이 정답과 얼마나 차이가 있는지 측정하기 위해
③ 학습 속도를 빠르게 조절하기 위해
④ 정확도를 직접적으로 계산하기 위해
'Miscellaneous' 카테고리의 다른 글
| [2025-1] 정유림 - GNN (GCN, GraphSAGE, GAT) (0) | 2025.03.16 |
|---|---|
| [2025-1] 박제우 - TabNet : Attentive Interpretable Tabular Learning (0) | 2025.03.15 |
| [2025-1] 윤선우 - 밑바닥부터 시작하는 딥러닝 리뷰, (CH 4.3) 수치 미분 (0) | 2025.03.12 |
| [2025-1] 박경태 - 밑바닥부터 시작하는 딥러닝(CH 4.5): 학습 알고리즘 구현하기 (0) | 2025.03.12 |
| [2025-1] 노하림 - Beyond Scalar Reward Model: Learning Generative Judge from Preference Data (6) | 2025.03.10 |


