
TabNet: Attentive Interpretable Tabular Learning
We propose a novel high-performance and interpretable canonical deep tabular data learning architecture, TabNet. TabNet uses sequential attention to choose which features to reason from at each decision step, enabling interpretability and more efficient le
arxiv.org
https://www.intelligencelabs.tech/a5b4fc25-1500-4d13-b0fd-10227d7be0a5
정형 데이터를 위한 딥러닝: TabNet
Table of contents
www.intelligencelabs.tech
https://colab.research.google.com/drive/1zMOMUUzBvNQoDpVmIRNhH3qfdQbeRRNC#scrollTo=St7Z06OyYo26
TabNet.ipynb
Colab notebook
colab.research.google.com
TabNet은 정형 데이터 처리를 위한 딥러닝 모델이다. CNN을 비롯해서 ImageNet 등 비정형 데이터 처리 기술은 비약적으로 발전한 반면 정형 데이터 모델은 DT계열이 아직도 우세하다. 그래서 DT와 DNN모델을 적절히 융합한 TabNet이라는 모델을 제안했다.
트리 계열 모델은 학습 속도와 직관성에서 강점을 보인다. Light GBM이나 XGBoost는 특히 성능까지 준수해 큰 인기를 끌었다. 그러나 데이터의 패턴이 복잡해질 경우 학습을 수행하지 못한다. 이러한 한계를 극복하기 위해 복잡한 데이터에서 좋은 성능을 보이는 딥러닝 모델을 활용했다.
TabNet의 특징을 우선 간단히 요약하자면 다음과 같다.
- End to End 모델의 성질을 활용해 데이터 전처리가 크게 필요없다. 여기서는 gradient descent 기반의 최적화를 활용한다.
- 적절한 feature 선택을 위해 Sequantial Attention을 사용한다. 중요한 특성을 선택하고, 그렇지 않은 특성은 0으로 계산한다.
- 높은 성능과 해석 가능성을 보인다.
- 자가지도학습이 가능하다.
TabNet은 sparse feature selection을 활용한다. 논문에서는 soft feature selection with controllable sparsity in end-to-end learning 라고 표현했다.

다음은 sparse feature selection의 예시이다. Feature Selection 단계에서는 각 블럭(Profesional occupation related, Investment Related)에 해당하는 특성을 선택하고 이를 학습에 가능하도록 비선형적으로 처리한다. 한 블럭에서 처리된 정보는 다음 단계로 넘어가 순차적 처리를 가능하게 한다. 마지막으로 각 블럭에서 누적된 정보를 바탕으로 출력값을 산출한다.

또한 TabNet은 자가지도학습 방식을 사용하 라벨이 없거나 부족한 상황에서도 학습을 수행할 수 있게 설계되었다.
자가지도학습에서는 먼저 비지도 학습 방식을 통해서 블라인드 처리 된 값을 다른 특성을 통해 구한다. 여기서 endcoder와 decoder가 활용되는데 encoder에서 특성들을 활용해 encoded representation을 출력한다. decoder에서는 이를 입력받아 블라인드 처리된 값을 복원한다. decoder에서 복원한 값과 원래 값의 차이를 최소화하는 방향으로 모델을 개선한 뒤 그 encoder를 지도학습에서 활용한다.

다음은 TabNet의 endcoder와 decoder의 구조이다. 그 중 encoder의 구조에 대해서 살펴보자면 encoder는 feature transformer, attentive transformer, feature masking으로 구성된다.
feature transformer의 경우에는 입력된 데이터를 통해 encoded representation을 생성한다. attentive transformer는 이전 단계의 출력을 기반으로 Sparsemax 함수를 적용한다. 즉 어떤 특성을 사용하고, 어떤 특성을 0으로 수렴시킬지 결정한다. feature masking(MASK)에서 해당 결과를 수행하고 다음 단계로 넘긴다.
Decoder에서는 직관적으로 보이듯이 주어진 입력값을 원래대로 변환한다.
본격적으로 TabNet 모델을 학습시킬 때, 연속형 데이터의 경우엔 정제되지 않은 상태(raw) 그대로 입력하고 범주형의 경우 학습 가능한 임베딩으로 변환한다. 또한 입력 데이터는 Batch Normalization(BN)으로 정규화시킨다.
TabNet은 또한 순차적 처리 방식을 사용하고 있다. 입력 데이터를 받으면 데이터에서 어떤 특성을 사용할지 선택하고 이를 다양한 곳에 전달하는 다단계 방식과, 이전 단계(i-1)의 출력값이 다음 단계(i)의 입력값이 되는 탑다운 어텐션 방식을 적용한다.
TabNet에서 가장 중요한 특성 선택은

다음과 같은 방식으로 이루어진다.
M[i]는 Sparse Mask를 의미한다. p[i-1]은 이전단계에서 그 특성이 얼마나 자주 쓰였는지, h항은 이전단계의 출력을 학습 가능하게 변환하는 함수이다.
sparsemax함수는 해당 특성의 중요도를 확률값으로 변환한다. 중요하지 않은 특성에는 0이 부여된다는 점이 주목할 점이다.
이렇게 Sparse Mask를 통해 처리된 특성은 Feature Transformer를 통해 비선형 변환이 된다. Feature transformer 내부의 과정은 위 그림의 (c)부분에서 확인할 수 있다.
각 특성이 모델에서 갖는 중요도는 다음과 같이 계산할 수 있다.

i단계에서의 가중치 중요도를 나타내는 수식이다. 여기서 ReLU를 적용해주는 이유는 중요하지 않은 특성에 대해서는 0을 부여하는 한편 음수값을 만들지 않도록 하기 위함이다.

이를 선형 결합해주면 샘플 b의 특성 j에 대한 전체 중요도를 다음과 같이 구할 수 있다.
실험 결과

다른 선행 연구의 데이터셋으로 실험이 진행되었다.
Syn1 ~ Syn3은 모든 샘플에서 동일한 특성이 중요한 역할을 했고(Global Feature) Syn 4 ~ Syn 6에서는 실험마다 중요한 역할을 한 특성이 달라졌다.
Syn1 ~ Syn3에서는 INVASE 모델이 가장 높은 정확도를 보였는데 이는 약 10만개의 파라미터로 연산하는 반면 TabNet 모델은 약 26,000개의 파라미터로 연산을 수행해 상대적으로 낮은 정확도에 비해 훨씬 빠른 모델링 속도를 보였다. 또한 Global모델과 유사한 성능을 보인 것으로 보아 Global Feature를 올바르게 선택했다고 볼 수 있다.
Syn4 ~ Syn 6에서도 마찬가지로 약 31,000개의 파라미터를 사용한 TabNet 모델이 10만개가 넘는 파라미터를 이용한 INVASE보다 우수하거나 비등한 성능을 보였다.





(사진 순서가 바뀜)
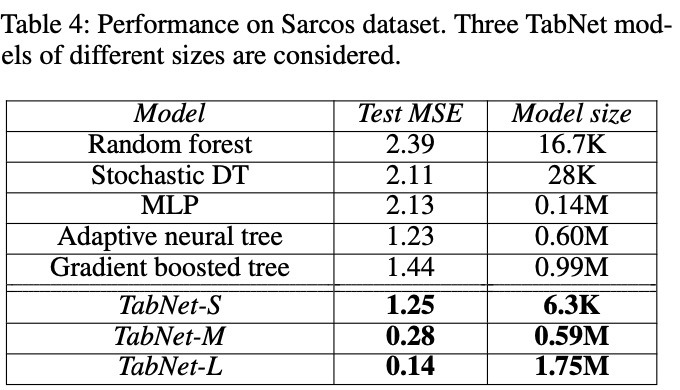
다른 데이터셋에 대해서 실험을 진행한 결과 역시 동일하게 TabNet이 가장 높은 성능을 보였다.
'Miscellaneous' 카테고리의 다른 글
| [2025-1] 임재열 - Instant Neural Graphics Primitives with a Multiresolution Hash Encoding (Instant NGP) (0) | 2025.03.22 |
|---|---|
| [2025-1] 정유림 - GNN (GCN, GraphSAGE, GAT) (0) | 2025.03.16 |
| [2025-1] 임준수 - 밑바닥부터 시작하는 딥러닝 리뷰, (CH 4.2) 손실함수 (0) | 2025.03.12 |
| [2025-1] 윤선우 - 밑바닥부터 시작하는 딥러닝 리뷰, (CH 4.3) 수치 미분 (0) | 2025.03.12 |
| [2025-1] 박경태 - 밑바닥부터 시작하는 딥러닝(CH 4.5): 학습 알고리즘 구현하기 (0) | 2025.03.12 |



