
< DETR >
https://arxiv.org/abs/2005.12872
End-to-End Object Detection with Transformers
We present a new method that views object detection as a direct set prediction problem. Our approach streamlines the detection pipeline, effectively removing the need for many hand-designed components like a non-maximum suppression procedure or anchor gene
arxiv.org
DETR은 transformer를 이용하여 post processing 없이 object detection을 수행하는 모델이다.
1. 기존의 object detection 모델
pre defined anchor에서 ground truth값과의 iou값을 구해 bounding box를 regression으로 결정하는 방식을 이용한다. 즉, 정답값에 해당하는 ground truth와 얼마나 겹치는지에 대한 iou 값이 특정 threshold보다 크면 positive로, 작으면 negative로 해서 최종 bounding box를 regression을 통해 matching해내가는 매커니즘이다.
이 방식은 ground truth에 대응하는 정답값을 모든 anchor에서 찾기 때문에 여러 정답의 후보가 생기고 그 중에 하나를 최종 결정하는 many to one 방식이었지만 detr은 하나의 ground truth 값에 대해 하나의 bounding box만 결정하게 하는 one to one 방식으로 기존엔 anchor를 수천개 생성하여 객체를 예측하기 위한 proposal로 사용을 했지만 detr은 고정된 N개에 대해서만 예측을 수행하는 걸로 결정해 수많은 anchor를 생성하지 않고 중복 예측값을 만들지 않아 post processing 과정이 필요없다는 특징이 있다.
2. DETR의 아키텍쳐

1) CNN backbone
: 입력 이미지가 backbone network에 입력되어 feature map 생성한다.
2) Transformer encoder
: backbone에서 생성된 feature map이 encoder의 입력값으로 들어온다. encoder는 이미지 자체의 전역적인 특성을 파악하는 self attention 계산을 수행한다.
3) Transformer decoder
: decoder는 object query를 이용해 bounding box와 class label 예측 쌍을 생성한다. object query는 object feature와 object query positional embedding으로 구성되어 있는데 object feature query는 예측해야 할 객체 정보를 담고 있고, positional embedding은 그 객체가 어디에 위치할지를 나타내는 위치 정보를 담고 있다. 각 query feature는 처음엔 0으로 초기화되어 있어 어떤 객체를 detect해야할지 정해져 있지 않은데 decoder layer를 통과하는 업데이트 과정에서 encoder output 값을 기반으로 점진적으로 어떤 객체를 detect할지에 대한 class label을 결정해나간다. 동시에 결정된 객체의 positional embedding 값도 업데이트 되며 매 layer에서 feature query 값에 더해져 class label과 bounding box 정보를 예측하게 된다. 결과적으로 어떤 객체와 그 객체의 예측된 bounding box 정보를 담은 쌍들의 집합이 도출되는데 이를 마찬가지로 class label과 bounding box 정보로 구성된 ground truth, 즉 정답값과 매칭하여 후에 예측값과 정답값이 얼마나 차이나는지 계산하는데 쓰인다.
+) 예측값 집합과 ground truth 집합의 쌍들을 이진매칭 해줄 때 hungarian algorithm이 사용된다. 이 알고리즘은 두 개의 집합을 일대일 매칭할 때 최소의 비용이 드는 이분 매칭을 찾는 알고리즘으로 두 개의 집합을 행과 열로 가지는 행렬을 만들어 각각의 경우에 대한 cost를 적고 최소의 cost가 발생하는 matching index(순서), 즉, permutation 값을 찾는게 목적이다. 이때 cost가 작아질수록 bounding box 예측과 ground truth값이 비슷해진다.

4) FNN
: decoder output은 벡터 형태의 예측값을 우리가 원하는 형태로 바꿔주는 단계이다. FNN은 3개의 linear layer와 ReLu activation function으로 구성되어 있다.
5) Loss
:이런 식으로 예측한 bounding box에 대해 loss를 계산할 때는 1) L1 loss 2) generalized iou loss 를 사용한다. L1 loss만 쓰면 bounding box가 커지면 loss도 커진다는 문제점이 있는데 giou loss는 scale-invariant하므로 이런 문제 해결 가능하다. 매 epoch마다 loss를 계산하여 점차 loss를 줄여가는 방향으로 학습을 진행하게 된다.
< Deformable DETR >
https://arxiv.org/abs/2010.04159
Deformable DETR: Deformable Transformers for End-to-End Object Detection
DETR has been recently proposed to eliminate the need for many hand-designed components in object detection while demonstrating good performance. However, it suffers from slow convergence and limited feature spatial resolution, due to the limitation of Tra
arxiv.org
1. 기존 DETR의 두 가지의 문제점
1) 수렴하기 위한 Epoch이 매우 길어 학습시간이 길다 -> 관련없는 key ( encoder output ) 과의 attention도 진행하면서 필요없는 계산이 수행된다.
2) 작은 물체에 대한 성능이 매우 낮다 -> 작은 물체는 높은 해상도에서 feature를 추출해야 성능이 올라가는데 transformer는 높은 해상도에서 attention을 수행하면 계산 복잡도가 매우 높아진다.
2. Deformable attention module
1) deformable convolution : 기존의 convolution에서 필터는 고정된 격자 기반으로 일정한 정수값의 스텝으로 이미지를 따라 이동하며, 주어진 격자 내의 특정 위치에서만 정보를 추출한다. 그런데 deformable convolution은 각 필터의 샘플링 위치가 동적으로 조정됩니다. 즉, 고정된 격자가 아니라 offset이 추가된 위치에서 샘플링하는 것이다. 이 offset 값들은 학습 가능한 파라미터로, 모델이 훈련 데이터를 통해 어디에서 중요한 정보를 추출할지 자기 주도적으로 학습한다. 이를 통해 비정형적이고 복잡한 패턴을 더 잘 포착할 수 있다.
2) deformable attention : 이런 deformable convolution 매커니즘을 도입한 것이 deformable attention module이다. 기존의 detr은 query와 encoder output 즉 key와의 attention 값을 구해 그 값이 큰 key의 객체를 detect하는 걸로 결정이 된다. 그런 key는 매우 소수일텐데 모든 key에 대해 attention 값을 구하는 건 시간낭비이다. 따라서 소수의 key에 대한 attention 값만 구하면 계산량을 줄일 수 있다.이때 deformable convolution에서 offset을 통해 필터를 이동시켰던 것처럼 계산할 key의 위치도 이동시키는 것이다.
3. Deformable DETR의 아키텍쳐
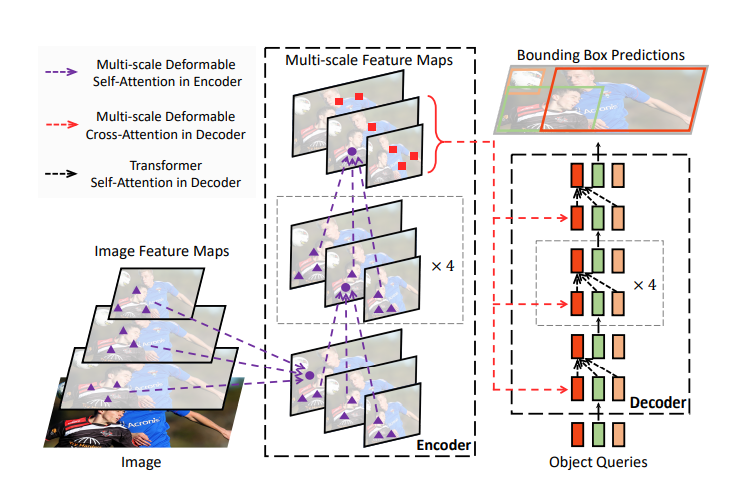
1) ) backbone : 기존의 detr은 single sacle feature map을 사용하였는데 deformable detr은 multi scale feature map을 추출한다. 이를 통해 고해상도에서 저해상도로 이어지는 feature pyramid를 구성해 작은 객체는 고해상도 맵에서, 큰 객체는 저해상도 맵에서 작동하여 기존의 작은 객체 탐지 성능이 낮다는 문제점을 해결할 수 있다.
2) transformer encoder : 모든 key에서 attention 계산을 수행하는 게 아니고 특정 key에서만 수행하는 deformable attention을 진행한다. 이때 두 가지 매커니즘으로 수행하는데 빨간색 선을 따라 수행되는 attention은 특정 query가 속하지 않은 스케일에서도 query와 관련된 key를 선택하여 multi scale 간 정보를 통합하는 기능을 수행하고 보라색 선을 따라 수행되는 attention을 통해서는 query와 같은 스케일 내에서만 중요한 key를 선택해 같은 스케일 내의 국소적인 세밀 정보를 처리할 수 있게 된다. 즉, multi scale의 global, local 정보를 활용하여 적은 계산량으로도 성능이 훨씬 높아질 수 있다. 정리하자면 보라색 선은 여러 스케일에서 Query와 관련된 정보를 선택적으로 수집하여, 최종적으로 Query가 속한 같은 스케일로 통합하고 빨간색 선은 Encoder에서 통합된 정보를 바탕으로, Query가 속한 스케일에서 관련성 있는 정보를 가져와 Decoder의 Object Query로 매핑하는 것이다.
3) transformer decoder : Deformable DETR에서 decoder는 query와 encoder의 feature map 간의 dot product을 계산하여 query가 어떤 key를 중요하게 여기는지 결정하고, 그 결과로 query가 어떤 객체를 detect할지, 그 객체가 어디에 위치할지 예측하는 방식으로 작동한다. 기존의 DETR에서는 full attention을 사용하며, 모든 query와 key 간의 내적을 계산하여 모든 위치에 대해 attention을 계산하고, 그 결과로 모든 feature map을 고려하여 예측을 진행하는데 이 방식은 계산량이 많고, 특히 고해상도 이미지에서는 비효율적이라는 단점이 있다. 하지만 Deformable DETR에서는 선택적 key를 사용하여, attention을 계산하는 위치를 제한하고, 필요한 부분에만 집중함으로써 효율성을 크게 향상시킬 수 있다.
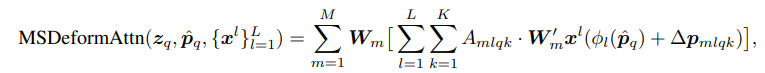
+) Iterative Bounding Box Refinement : 각 디코더 레이어에서 bounding box를 독립적으로 예측하고 점진적으로 업데이트하는 기법이다. 이는 첫 레이어에서만 초기 추정을 하고 나머지 레이어에서는 refinement하는 기존 방식과 다르게, 각 레이어가 초기 추정값을 독립적으로 구하고 그것을 개선하는 방식이다. 이를 통해 bounding box 예측의 정확도를 높이고, 점진적인 refinement가 가능하다. 그리고 각 레이어에서 refinement 과정을 반복적으로 수행하여 추정값을 개선해나간다.
+) Two-Stage Deformable DETR : 초기 예측을 coarse하게 하고, refinement를 세밀하게 하는 방식으로 두 단계를 나누어 처리하는 구조이다.
위의 두 가지 기법을 추가적으로 조합해 더 높은 성능의 모델을 구현했다.



