

Figure 1 KOSMOS-G는 입력된 이미지를 “외국어”로 간주하며 여러 이미지를 포함하는 일반화된 비전-언어 입력을 이해하고 이미지를 생성하는 능력을 가지고 있음.
Abstract
- 최근 텍스트에서 이미지로의 변환 (T2I, text-to-image) 및 비전-언어에서 이미지로의 생성 (VL2I, vision-language-to-image) 분야에서 상당한 발전이 있었음.
- 특히 여러 이미지를 포함하는 일반화된 비전-언어 입력에서의 생성은 미개척된 분야임.
- 본 논문에서는 MLLMs(Multimodal Large Language Models)의 고급 지각 능력을 활용하여 이러한 도전 과제에 대처하는 KOSMOS-G 모델을 제안함.
- KOSMOS-G는 제로샷 다중 개체 주체 구동 생성(zero-shot multi-entity subject-driven generation)의 고유한 기능을 보여줌.
- CLIP의 원활한 대체와 세분화된 제어에서 개인화된 이미지 디코더 변형에 이르는 수많은 U-Net 기술과의 쉬운 통합이 가능함.
- KOSMOS-G를 “이미지 생성에 있어서 외국어로서의 이미지”라는 목표를 향한 초기 시도로 제시함.
CLIP (Contrastive Language-Image Pre-Training)
- 다양한 (이미지, 텍스트) 쌍에 대해 훈련된 신경망
- GPT-2 및 3의 제로샷 기능과 유사하게 작업을 직접 최적화하지 않고 이미지가 주어진 가장 관련성이 높은 텍스트 스니펫을 예측하도록 자연어로 지시할 수 있음
1 Introduction
- 최근의 연구에서 특히 확산 모델을 통한 텍스트-이미지(T2I) 생성의 발전은 텍스트 설명에서 매우 사실적이고 정확하며 다양한 이미지를 생성하는 데 놀라운 발전을 보여줌. 텍스트 설명에서 매우 정확한 이미지를 생성하는 전례 없는 성공을 바탕으로 수많은 연구에서 더 정교한 비전-언어-이미지(VL2I) 생성 기술을 탐구함.
- DreamBoot, SuTI 와 같은 방법: 피사체 이미지와 텍스트 설명을 모두 입력으로 사용하여 새롭게 설명된 맥락에서 피사체를 렌더링하는 피사체 주도 생성을 강조함.
- InstructPix2Pix 와 같은 이미지 편집 모델: 원본 이미지와 편집 명령을 받아들여 수정된 이미지를 출력으로 생성함.
- 그러나 일반화된 비전-언어 입력에서 이미지를 생성하는 방법은 충분히 탐구되지 않음.
- 이러한 목적을 달성하기 위해 많은 연구가 진행되어 왔음. 특히 Re-Imagen와 Prompt Diffusion, SuTI는 이미지 특징을 확산 모델의 U-Net에 주입함. 이러한 모델은 특정 VL2I 작업을 처리하기 위해 이미지와 텍스트 지침를 통합함.
- Re-Imagen: 보강 이미지 생성(retrieve-augmented image generation)에 초점을 맞춤
- Prompt Diffusion: 피사체 중심 생성(subject-driven generation)을 강조함.
- SuTI: 맥락 생성(in-context generation)에 특화되어 있음.
- 그러나 이러한 주입 방법은 텍스트와 이미지에 대한 지침을 분리하여 두 양식 간의 공동 모델링의 효과를 제한함. 또한, 이 방법은 여러 개체가 관련된 경우 시나리오로 확장하기 어려움.
- MLLM은 언어 모델의 기능을 크게 확장하여 이미지와 같은 다양한 양식(modalities)을 처리할 수 있게 하였음. 이러한 멀티모달 인식은 LLM이 문서 인텔리전스 및 그래픽 사용자 인터페이스 이해를 포함하여 이전에 불가능하다고 간주된 작업을 수행할 수 있도록 함.
- 최근 연구에서는 MLLM을 VL2I 작업에 활용하고 있음. 이 접근법은 다음과 같은 몇 가지 장점을 제공함:
1) MLLM 내부의 비전-언어 정렬을 활용함.
2) MLLM 아키텍처는 여러 이미지를 수용할 수 있도록 자연스럽게 교차되는 비전-언어 입력을 지원함. - 이 영역의 선구적인 작업 중 하나는 M-VADER로, image-caption 쌍에 대한 학습을 통해 MLLM과 확산 이미지 디코더 간의 의미적 정렬을 달성함. GILL와 Emu, DreamLLM은 교차되는 비전-언어 생성에 초점을 맞추고 있음. 이들은 MLLM의 출력 공간을 CLIP 지도(supervision) 또는 멀티모달 copora에 대한 pre-training을 통한 확산 이미지 디코더로 효과적으로 정렬함.
- 그러나 이러한 정렬은 주로 의미론적 수준에 머물러 있으며, 이는 이러한 방법이 세부적인 피사체 중심 이미지 생성에 적합하지 않을 수 있음을 의미함.
- BLIP-Diffusion은 피사체를 무작위 배경과 합성하며 객체 표현을 학습함. 이 접근 방식은 제로샷, 피사체 중심 text-to-image 생성 능력을 효과적으로 부여함. 그러나 입력 템플릿 및 학습 데이터의 특정 설계로 인해 여러 객체에 대한 확장성이 제한되어 있음.

Figure 2 KOSMOS-G는 멀티모달 인식을 위한 MLLM을 포함하며, MLLM을 확산 U-Net 이미지 디코더에 연결하는 AlignerNet과 결합함. KOSMOS-G는 교차 입력에서 이미지 디코더로 세부 개념 수준의 지침을 전달할 수 있으며 CLIP에 대한 대안을 제공함. 주황색은 학습 가능한 모듈을 나타내고 파란색은 고정된 모듈을 나타냄.
KOSMOS-G는 일반화된 비전-언어 입력을 다루기 위한 모델로, "명령 전 정렬" 전략을 활용함. 여러 단계의 학습 과정을 거쳐 다양한 작업을 수행하며, 이미지 디코더를 활용하여 이미지를 생성함. 이 모델은 CLIP를 대체할 수 있어 다양한 응용 프로그램에서 사용될 수 있음. KOSMOS-G는 제로샷 설정에서 새로운 개념을 캡처하고, 다중 개체에 대한 주도적 생성 능력을 갖추어 제안된 목표에 도달하고 있습니다. 특히, 구성적 명령어 튜닝 작업을 통해 이러한 능력을 이끌어내고, 스코어 처리 명령어 튜닝을 통해 U-Net 기술과의 원활한 통합을 실현하고 있음. 이를 통해 "이미지 생성에서 외국어로서의 이미지" 목표에 대한 초기 노력으로 KOSMOS-G를 제안함.
여러 개체를 포함한 일반화된 비전-언어 입력을 지원하기 위해, 우리는 MLLM이 “명령 전 정렬” 방식을 따르는 특성을 활용한 KOSMOS-G를 제안함. 구체적으로, 우리는 멀티모달 언어 모델링 단계에서 시작하여 KOMOS-1 MLLM으로 이어짐. 언어 모델을 범용 작업 레이어로 구상하여 자유 형식의 교차된 비전-언어 입력을 인식하고 다양한 작업 예측을 텍스트 형식으로 통합함. 정렬된 비전 언어 표현이 주어지면, 언어 양식을 앵커로 사용하고 MLLM의 출력 공간을 CLIP 텍스트 인코더와 정렬함. 마지막으로 정리된 데이터에 대해 명령 튜닝을 수행함. KOSMOS-G는 캡션을 입력으로 받아 각 개체가 분할된 이미지로 이어짐. 모델은 모든 객체를 충실하게 재현하고, 텍스트 컨텐츠를 렌더링하고, 명령어를 따르도록 학습됨. 이 과정에서 고정된 pre-trained 확산 이미지 디코더는 스코어 메트릭(score metric)의 역할을 수행함. 우리는 학습된 데이터 분포를 처리하여 미분 가능한 기울기를 MLLM으로 전달함. 이를 통해 KOSMOS-G는 이미지 인코더의 풍부한 기능을 활용하여 다양한 맥락에 걸쳐 컨텐츠를 충실하게 재생산하는 이미지를 생성할 수 있음.
KOSMOS-G는 범용 pre-training의 이점을 활용하여 “이미지 생성에서 외국어로서의 이미지”라는 목표에 접근함. 이는 KOSMOS-G가 입력 이미지에서 새로운 개념을 캡처하고 제로샷 설정에서 개인화된 창작물을 보여줄 수 있음을 의미함. 특히 KOSMOS-G는 제로샷 다중 개체의 피사체 중심 생성(zero-shot multi-entity subject-driven genreation)을 마스터한 최초의 모델이기도 함. 스코어 처리 명령어 튜닝으로 인해 KOSMOS-G는 이미지 디코더의 파라미터, 즉 확산 U-Net 및 VAE를 수정할 필요가 없음. 이를 통해 모든 이미지 생성 시스템에서 CLIP을 KOSMOS-G로 원활하게 대체할 수 있음. 그 결과, ControlNet과 같은 세분화된 제어부터 LoRA 체크포인트와 같은 개인화된 또는 양식화된 이미지 디코더 변형에 이르기까지 수많은 애플리케이션이 U-Net 기술과 통합할 수 있음.
전반적으로, 우리는 “이미지 생성에서 외국어로서의 이미지”라는 목표를 향한 초기 시도로 KOSMOS-G를 제안함. 우리의 주요 성과를 다음과 같이 요약함:
1. 텍스트 양식의 앵커를 사용하여 MLLM의 출력 공간을 CLIP 기준으로 정렬하고 이미지 생성을 위해 MLLM의 멀티모달 인식을 효율적으로 활용함.
2. 제로샷 다중 개체의 피사체 중심 생성(zero-shot multi-entity subject-driven generation) 능력을 이끄는 구성적 명령어 튜닝 작업을 제안함.
3. 스코어 처리 명령어 튜닝은 KOSMOS-G가 다양한 U-Net 기술과 원활하게 상호작용할 수 있도록 하며, 다양한 프레임워크에 통합할 수 있는 폭 넓은 적용 가능성을 나타냄.
2 KOSMOS-G: Image as a Foreign Language in Image Generation
KOSMOS-G는 일반적인 모달리티를 지각하고 이미지를 생성할 수 있는 모델로, 다음과 같은 세 단계로 학습됨: 멀티모달 언어 모델링, 이미지 디코더 정렬, 명령어 튜닝. 학습은 “명령 전 정렬” 방식을 따르며, 이미지 디코더는 모든 단계에서 동결된 상태를 유지함.
1. 멀티모달 언어 모델링: 멀티모달 copora에서 MLLM을 처음부터 pre-train하며, monomodal(단일 모드) 데이터, cross-modal paired 데이터 및 KOSMOS-1 이후 언어 모델링 손실이 있는 교차된 멀티모달 데이터를 포함함.
2. 이미지 티코더 정렬: Stable Diffusion v1.5의 U-Net을 이미지 디코더로 사용함. CLIP 지도를 통해 KOSMOS-G의 출력 공간과 U-Net의 입력 공간을 정렬하기 위해 텍스트 데이터에만 AlignerNet을 학습시킴. 여기서, 언어는 anchoring modality의 역할을 하며, 이미지 입력이 이미지 디코더와 호환되도록 보장함.
3. 명령어 튜닝: 고정된 U-Net에서 미분가능한 기울기를 사용하여 큐레이팅된 데이터에 대한 구성 생성 작업을 통해 KOSMOS-G를 추가로 fine-tune함. 1단계에서는 MLLM만 학습함. 2단계에서 AlignerNet은 MLLM을 고정한 상태로 학습함. 3단계에서는 AlignerNet과 MLLM은 모두 공동으로 학습됨. 이미지 디코더는 모든 단계에 걸쳐 고정된 상태로 유지됨.
2.1 Multimodal Language Modeling
KOSMOS-1에 이어 KOSMOS-G는 일반적인 양식을 통일된 방식으로 인식함. 이를 위해 입력 형식을 특수 토큰을 사용하여 단일 시퀀스로 표현함. 특히 토큰을 사용하여 시퀀스 시작 및 종료를 나타냄. 또한 시퀀스 내에 내장된 이미지 표현의 시작과 끝을 나타내기 위해 토큰을 사용함.
KOSMOS-G는 다양한 모달리티를 통일된 방식으로 인식하는 모델로, 입력 형식을 특수 토큰을 사용하여 단일 시퀀스로 표현함. 멀티모달 언어 모델링에서는 텍스트와 이미지를 벡터로 인코딩하고 Transformer 기반 디코더에 전달함. 모델은 다음 토큰 예측 작업을 통해 훈련되며, 이를 통해 텍스트 토큰의 log-likelihood를 최대화함. 이를 위해 MLLM은 24개의 레이어와 다양한 dimension 및 attention head를 사용하며, 이미지는 pre-trained CLIP ViT-L/14 모델에서 얻음.
2.2 Image Decoder Aligning
멀티모달 언어 모델링 후, MLLM 내에서 비전과 언어 지각을 성공적으로 정렬했고 KOSMOS-G가 이미지 생성이 가능하도록 확산 모델을 이미지 디코더로 도입함. 이 과정에서 U-NetNet 아키텍처나 가중치에 어떠한 수정도 가하지 않고, CLIP 텍스트 인코더만을 멀티모달 KOSMOS-G로 대체함.
Preliminaries of Latent Diffusion Models, 잠재 확산 모델의 기초
- 확산 모델은 T 단계에 걸쳐 초기 실제 데이터 z0 ~ q(z)에 가우시안 노이즈 샘플을 추가하여 순방향(forward) 확산 프로세스 q의 Markov chain을 정의함.
- z: 픽셀 값이 아닌 잠재 표현(latent representations).
- 효율적인 저차원 잠재 공간은 고차원 RGB 공간과 지각적으로 동등한 반면, 픽셀 도메인에 존재하는 의미론적으로 의미 없는 중복 정보는 제거됨.
- E와 D로 구성된 지각 압축 모델(Perceptual compression models)(즉, VQ-VAE)은 실제 데이터를 잠재 공간으로 인코딩함.
- 잠재 확산 모델은 확산 과정에서 픽셀 값으로 직접 작업하는 대신 잠재 표현 z = E(x)를 사용함.
- 최종 출력은 D(z)를 통해 픽셀 공간으로 다시 디코딩될 수 있음. 별도의 지각 압축 단계는 인지할 수 없는 세부 사항만을 제거하여 훨씬 낮은 비용으로 경쟁력 있는 생성 결과로 이어짐.
- 각 시간 단계 t에서 순방향 프로세스 는 (1)과 같이 표현할 수 있음.
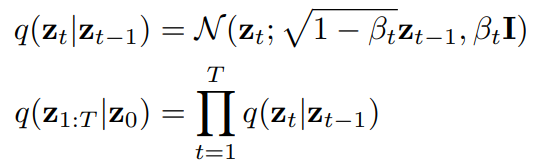
Align Output Space with Diffusion Models , 출력 공간과 확산 모형 정렬
- CLIP 텍스트 인코더를 KOSMOS-G로 교체한 후, 주된 관심은 KOSMOS-G와 이미지 디코더 간의 정렬 문제를 해결하기 위해 AlignerNet을 도입하는 것.
- gradient 를 사용하여 KOSMOS-G를 미세 조정하는 것만으로는 정렬과 이미지 품질에 미미한 영향을 미치는 것으로 발견되어, AlignerNet을 제안함.
- AlignerNet은 인코더 M과 디코더 N으로 구성되어 KOSMOS-G의 소스 공간 S과 CLIP 텍스트 인코더의 대상 공간 T 간의 정렬을 학습하며, 텍스트 소스 임베딩과 대상 임베딩 간의 거리를 최소화하여 정렬을 수행함.
- 단일 텍스트 캡션 C가 주어지면, KOSMOS-G 소스 인코더와 CLIP 텍스트 대상 인코더는 각각 캡션을 인코딩함: s ∈ R ls×ds, t ∈ R lt×dt
- l: the length of features
- d: embedding dimensions

- 인코더 M을 사용하여 텍스트 소스 임베딩과 대상 임베딩 간의 거리를 최소화하고, 근사 M(s) ≈ t를 목표로 함.

- feature discrimination 감소를 완화하기 위해 디코더 N을 사용하여 다음을 통해 소스 임베딩 N(M(s)) ≈ s 를 재구성함.

- KOSMOS-G는 비전-언어 멀티모달 인코더로, 언어 모달리티가 앵커 역할을 하여 KOSMOS-G 공간 전체를 이미지 디코더 입력 공간과 정렬하며 이미지 임베딩에 대한 의미적 정렬을 수행함.
- 긴 시퀀스를 효율적으로 처리하고 메모리 사용을 최소화하기 위해 KOSMOS-G는 가변 길이 임베딩으로 시퀀스를 인코딩하며, 이를 위해 AlignerNet에는 Transformer 기반 아키텍처가 도입되어 일치하지 않는 시퀀스 길이와 임베딩 차원을 효과적으로 정렬함.
- M과 N은 유사한 아키텍처를 갖고 있으며, Transformer 인코더와 디코더로 구성되어 있음.
2.3 Instruction Tuning
- 의미적 정렬(semantic alignment)을 달성한 후, KOSMOS-G는 멀티모달 비전-언어 가이드에 따라 이미지를 생성할 수 있지만, 의미적 일관성만을 보존하며 이미지 인코더의 풍부한 기능을 활용하여 내용을 다양한 컨텍스트에서 콘텐츠를 충실하게 재현하지 못함.
- “이미지 생성에서 외국어로서의 이미지” 목표를 달성하기 위해 KOSMOS-G를 fine-tuning 하고자 함.
- 이를 위해 교차 언어 모델링 및 텍스트만 정렬된 단계에서 나온 모델을 더욱 세밀하게 튜닝하려면 (3)의 확산 손실(diffusion loss)을 사용함.

- 구체적으로 개체를 포함하는 캡션을 입력하고 각 개체에 해당하는 이미지를 입력하는 구성 생성 작업을 제안함.
- “ A cat image embedding of the cat and a dog image embedding of the dog sleeping in the garden image embedding of the garden ”.
- KOSMOS-G 모델은 입력된 명령어에 따라 이미지를 생성하도록 학습함.
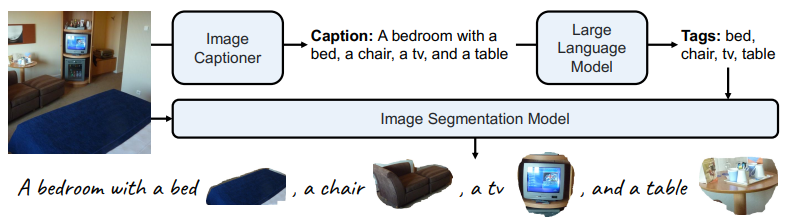
Figure 4 데이터 구축 파이프라인: 필요한 데이터를 구축하기 위해 먼저 이미지에 캡션을 추가하고, 캡션에서 개체를 추출하고 이미지에서 분할 결과를 얻음.
3 Model Training
3.1 Multimodal Training Data
멀티모달 언어 모델링 및 이미지 디코더 정렬에는 웹 규모의 멀티모달 corpora가 사용되었고, 명령어 튜닝에는 Open Images V7 데이터셋 및 InstructPix2Pix의 이미지 편집 데이터가 사용됨. 이미지-캡션 쌍은 여러 데이터셋에서 수집되었으며, 구성된 데이터는 Open Images V7 데이터셋에서 생성됨.
3.2 Training Setup
- 학습은 TorchScale 라이브러리를 사용하여 수행되었고, MAGNETO를 MLLM과 AlignerNet의 백본 아키텍처로 사용함. 전체 학습 과정은 256개의 NVIDIA V100 GPU를 사용하여 약 4일이 걸리며, 이미지 디코더 정렬에는 1일, 명령어 튜닝에는 3일이 소요됨.
- 명령어 튜닝 단계에서는 혼합 구성된 데이터, InstructPix2Pix 데이터, 캡션 데이터를 2:2:1의 비율로 혼합하여 사용함.

- 학습 설정은 세 단계로 나뉘어지며, 각 단계에서는 다양한 데이터 소스를 사용하여 모델을 학습 시킴.
- 멀티모달 언어 모델링: 텍스트 corpora에서 토큰 50만 개, 이미지 캡션 쌍에서 토큰 50만 개, 교차된 데이터 세트에서 얻은 토큰 20만 개 등 120만 개의 토큰 배치 크기를 사용함. MLLM은 총 3600억 개의 토큰에 해당하는 30만 단계에 대해 학습함.
- 이미지 디코더 정렬: AlignerNet 은 30만 단계 동안 3,584개 문장의 배치 크기를 사용하여 학습함.
maximum learning rate은 1e-3, 전체 약 10억 문장에 해당, 나머지 구성은 이전 단계와 일치. - 명령어 튜닝: MLLM과 AlignerNet은 20만 단계에 걸쳐 총 약 2억 개의 이미지를 1,024개의 배치 크기로 공동으로 학습함.
4 Evaluation
4.1 Main Qualitative Results
- KOSMOS-G는 다양한 설정(사용자 특화된 주제 등)에서 의미 있고 일관된 인상적인 제로샷 생성 결과를 생성함.
- 시각적 샘플은 재맥락화, 양식화, 수정 및 액세서리 통합( re-contextualization, stylization, modification, and accessory incorporation )에서 생성 기능을 보여줌.
- 특히, DreamBoot와 같은 fine-tuning 방식의 경우에도 다중 엔티티 VL2I는 매우 어려움.
- 새로운 구성 생성 명령어 튜닝 덕분에 제로샷 설정에서 이를 달성할 수 있는 모델은 KOSMOS-G가 처음임.

Table 1
왼쪽: DreamBench에서의 정량적 비교. ∗는 제로샷 방법.
오른쪽: MS-COCO에서의 제로샷 FID 비교. †는 KOSMOS-G와 동일한 설정 및 시드에서 평가한 결과.
FID (Fréchet Inception Distance): 생성된 영상의 품질을 평가하는 지표. 영상 집합 사이의 거리를 나타냄. GAN을 사용해 생성된 영상의 집합과 실제 생성하고자 하는 클래스 데이터의 분포의 거리를 계산함. 거리가 가까울수록 좋은 영상
4.2 Quantitative Results
- DreamBench 데이터셋에는 30개의 주제가 포함되어 있으며 25개의 프롬프트 템플릿이 있음. 이는 재문맥화, 수정, 액세서리 통합 등의 기술을 다루는 750개의 고유한 프롬프트을 생성함. 각 프롬프트에 대해 4개의 이미지를 생성하여 종합적인 평가를 위해 3000개의 이미지를 생성함.
- DINO, CLIP-I: 주제의 충실도를 평가
- CLIP-T: 텍스트 충실도를 평가
- 제로샷 KOSMOS-G는 Textual Inversion 및 Re-Imagen을 능가함
- 단일 이미지 입력만으로도 DreamBooth 및 BLIP-Diffusion보다 약간 더 나은 성능을 보여줌.
- 지도학습 필요 없는 SuTI와 유사한 결과
- KOSMOS-G는 하나의 이미지만을 입력으로 받으며, 각 주제에 대해 제공된 4-7장의 이미지 중 명확한 이미지를 선택함.
- 명령어 튜닝 데이터와 더 잘 일치하도록 프롬프트 템플릿을 약간 수정함.
4.3 Ablation Studies

- 이미지 디코더 정렬 및 명령어 튜닝의 중요성을 확인하기 위한 실험
- Table 2는 직접적인 end-to-end 튜닝이 의미 있는 이미지를 생성하지 못하는 것을 보여줌.
4.4 Applications

Figure 7: U-Net 기술과 함께 KOSMOS-G의 다양한 응용 프로그램.
- KOSMOS-G는 어떠한 이미지 생성 시스템에서도 CLIP를 원활하게 대체할 수 있음. 이 특성으로 이전에는 불가능했던 다양한 새로운 적용이 가능함.
- Figure 7에서는 ControlNet와 LoRA 변형과의 통합을 보여줌. KOSMOS-G는 이러한 기술과 완벽하게 작동함.
- KOSMOS-G는 CLIP 공간을 기반으로 하여 텍스트 조건 생성에서 비전-언어 생성으로의 전환을 촉진하며 다양한 혁신적인 적용의 길을 열 것으로 기대함.
5 Conclusion
- 여러 이미지를 포괄하는 일반화된 비전-언어 입력으로부터 고품질의 제로샷 이미지 생성이 가능한 KOSMOS-G를 제안함.
- "명령 전 정렬"의 pre-training 학습 전략에 기반함.
- KOSMOS-G는 경쟁력 있는 단일 객체 중심 이미지 생성 및 T2I로의 능력을 보여주며, 또한 제로샷 중심 다중 객체 이미지 생성을 처음으로 확장한 모델로 자리잡고 있음.
- 더욱이, KOSMOS-G는 CLIP를 원활하게 대체할 수 있어 ControlNet 및 LoRA와 같은 다른 U-Net 기술과 함께 다양한 새로운 응용 프로그램을 개방함.
- 즉, KOSMOS-G를 "이미지 생성에서 외국어로서의 이미지"라는 목표를 달성하기 위한 초기 노력으로 제시함.
References
https://arxiv.org/abs/2310.02992v1



