
https://cseweb.ucsd.edu/~yfreund/papers/IntroToBoosting.pdf
0. Abstract
- boosting은 당시 주어진 learning 알고리즘보다 정확도를 향상시킴. AdaBoost에 대해 설명하는데, boosting의 기본 정리들, 왜 overfitting문제가 왜 없는지 설명하고, svm과의 관계에 대해 설명하는 논문임.
1. Introduction
- 경마 순위 예측에 대해 경마전문가들이 말을 선택하는 기준을 설명해달라하면 그 이유를 잘 설명하지 못함. 그러나, data가 주어졌을 때 말을 선택할 수 있음. >> (최근에 가장 많이 우승한 말에 베팅하거나 그 확률이 가장 높은 말에 베팅을 진행) 일명 rule of thumb
- rule of thumb의 이득을 최대화 하기위해 다음의 문제가 존재함.
- 전문가에게 제시된 collection 어떻게 선택해야, 전문가들의 유용한 rule of thum을 추출할 수 있는가?
- 많은 경험 법칙에 대해 어떻게 하나의 정확도 높은 예측 규칙으로 결합할 수 있는가?
- boosting은 일반적이고, 효과적으로 매우 정확한 prediction rule을 만드는 방식이며, AdaBoost 알고리즘에 집중해서 여러 test 결과, boosting의 theory설명 및 왜 overfitting issue가 없는 경향이 있는지 설명하고자 한다.
2. Background
- Boosting은 PAC 모델이라 불리는 것이 이론적 framework에 근간을 가지는데, Kerans와 Valiant는 weak(약한) 학습 알고리즘이 (강한) 학습 알고리즘보다 더 낫다는 것을 보였음. 이후에는 더 효과적은 boosting 알고리즘을 보였고, 실험은 ocr task로 수행
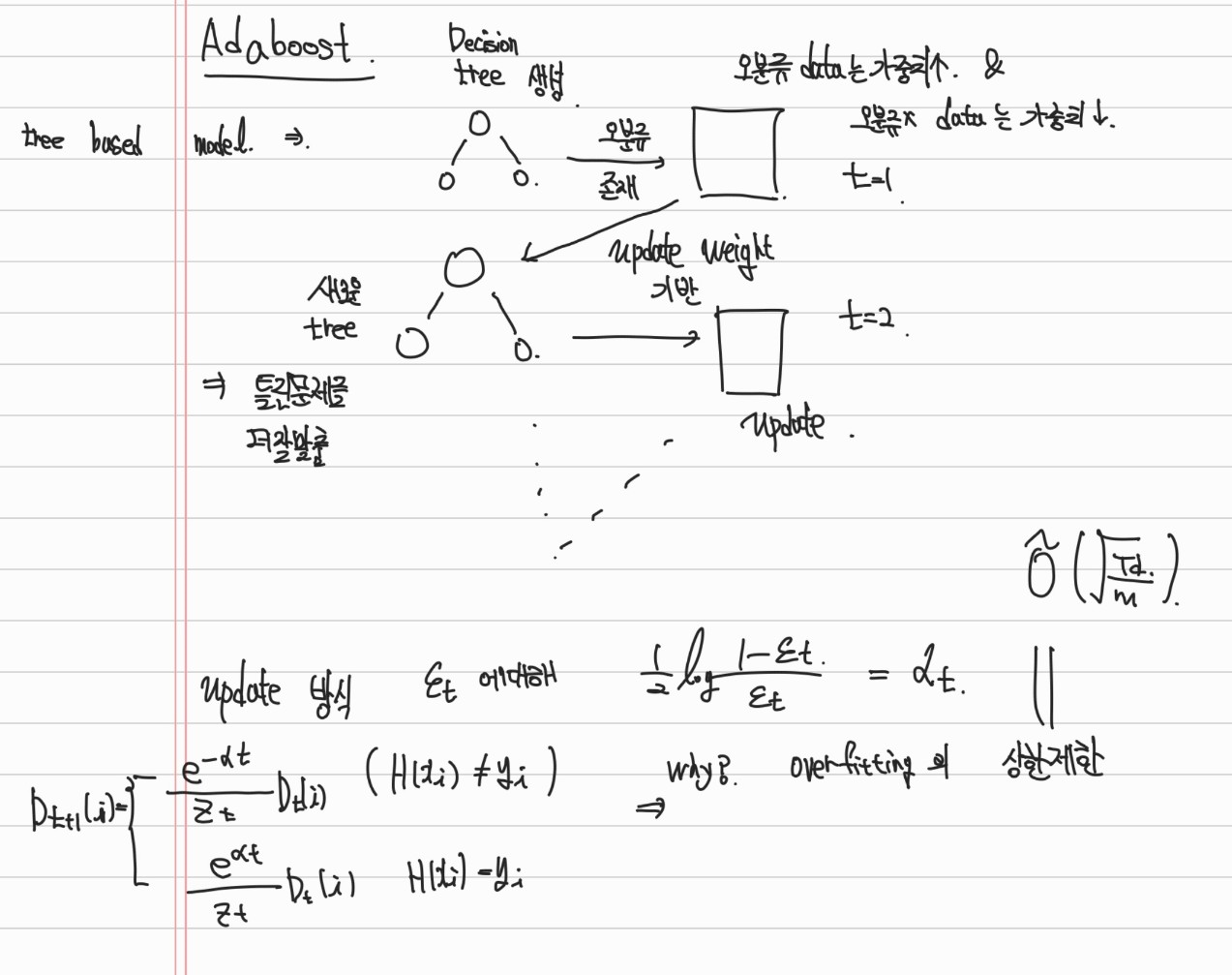
3. AdaBoost
- 1995년에 Freund와 Schapire에 의해 소개되었는데, 이전의 boosting 모델들의 실용적 어려움을 해결함.
- (xi, yi) training set이고, 우선은 binomial case y를 -1, 1로설정하고, 나중에 multicase로의 확장을 얘기할것임.
- t = 1 ~ T 에서 주어진 약한 learning algorithm 각각 진행
- t시점에서의 training example i의 분포 weight를 D_t(i)라 함.
- 초기에는 동일한 가중치 > 잘못분류된 데이터에 대해서는 가중치를 증가시켜서 hard example에 더 집중하도록 함.
- 각 t시점의 오류는 기존의 weight일때의 오분류율이고, 이는 오분류가 나타난 weight의 합.


- Z_t 는 normailization factor임 이는 D_t+1이 density가 되도록 정규화 하는것임.
- 가중치 업데이트는 맞춘 문제에 대해서는
예) 오분류율이 0.1이면, a_t = 0.5*log(9)
- 맞춘 sample에대해서는 weight를 감소 / 틀린 sample에 대해서는 weight를 증가시킴
- 최종적으로는 T라운드에서 sign( sum( a_t * h_t(x))) 으로 판단하는 것임. 그동안의 weight 수정해온 a_t를 따라 각분류기의 weight 곱해서 최종 부호로 결정.

- round횟수를 늘릴수록 train / test error가 감소. marginal CDF 5회 / 100회 / 1000회 iteration이후에 나타나는 CDF의 형태.
4. Analyzing the training error

5. Generalization error
6. Relation to support-vector machines
- svm에서의 idea와 boosting의 분류기 방식이 비슷한느낌이 위처럼 쓰여질 수 있음.
- 그러나, 다음의 내용들에서 확실히 다른점을 찾을 수 있음.
- 다른 norm의 사용이 다른 margin의 결론을 냄.
- 위의 식을 maximization 하는 것은, 2차식 programming에 해당 / adaboost 는 linear progamming
- high dimmensional space에서 확실한 차이가 있음.

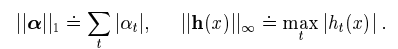

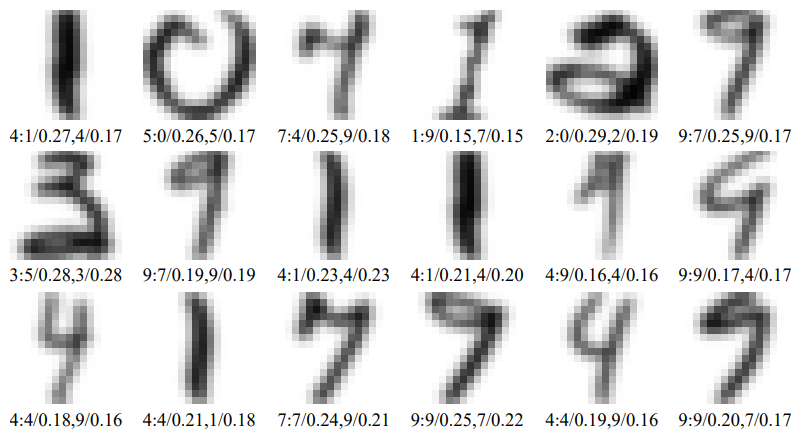
label : label추정1 / 확률, label추정2 / 확률
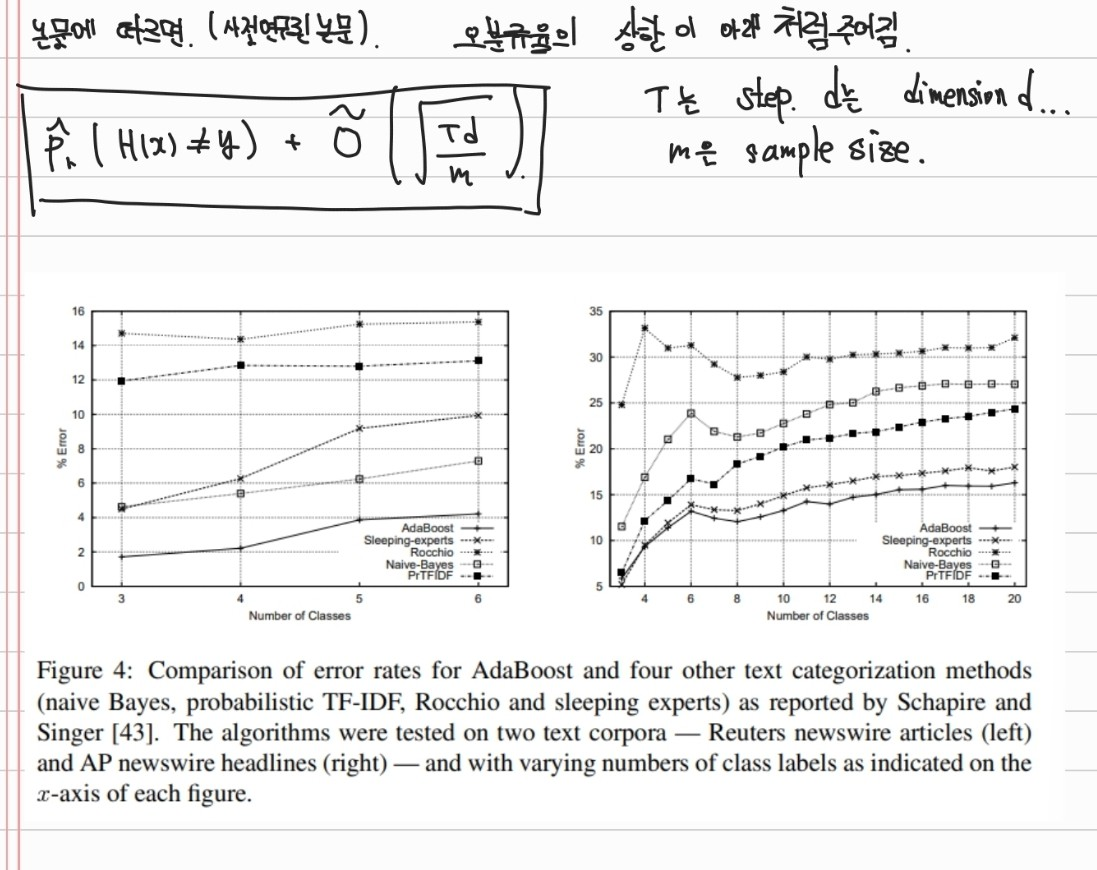
7. Experiments and applications
실제로, 적용이 빠르고 간단하고 program이 간단한 편임
그외 실험 적용 사례를 여러 논문들에 적용하고 있는데, 통계논문 특성상, 실제 모델, data별 비교보다는 각 논문에서의 문제에 적용했더니 잘된다. 등의 여러 사례들을 적어놓아 궁금하면 논문을 참고하면 될 것 같습니다.
cf) 내용 총 정리.
- 통계적으로 수렴성이 극히 제한적이지만 증명된것으로 알고 있으며, 해석가능한 tree기반 모델이면서, 여러 tree의 결과를 합쳐서 내는 앙상블 기법. 그러나, 여러 tree가 존재하여 전체적인 해석가능성은 떨어지지만, 딥러닝을 제외한 모델 중 예측력이 높고, 해석가능성도 어느정도 가져갈 수 있으므로, 금융권의 예측모형으로 자주 사용되는 것으로 알려져있음.
- 현재 논문에서는 binary classification을 기준으로 설명을 하였으나, continous인 상태에서도 잘 작동하며, 여러 가정이 많이 들어가지 않아 유용한 모델이다.
'Miscellaneous' 카테고리의 다른 글
| [2024-2] 황징아이 - 차원축소 : PCA, SVD, LSA, LDA, MF (0) | 2024.12.21 |
|---|---|
| [2024-2] 김영중 - Learning representations by back-propagating errors (2) | 2024.12.08 |
| [2024-1] 박지연 - Rectified Linear Units(ReLU) Improve Restricted Boltzmann Machines (0) | 2024.05.12 |
| [2024-1] 백승우 - A Unified Approach to Interpreting Model Predictions (0) | 2024.05.07 |
| [2024-1] 홍연선 - A Brief Introduction into Machine Learning (0) | 2024.04.14 |



