
<Tacotron: Towards End-to-End Speech Synthesis>
2017년도 구글에서 발표한 논문으로, 문자(character)로부터 직접 음성을 합성하는 end-to-end TTS 모델 Tacotron을 제시한다.
논문 원본 링크
https://arxiv.org/abs/1703.10135
Tacotron: Towards End-to-End Speech Synthesis
A text-to-speech synthesis system typically consists of multiple stages, such as a text analysis frontend, an acoustic model and an audio synthesis module. Building these components often requires extensive domain expertise and may contain brittle design c
arxiv.org
Abtract.
- Attention-seq2seq 기반의 TTS를 수행하는 Tacotron 모델 제시
- <문자, 음성> 쌍으로 이루어진 데이터로 학습 가능
- MOS Test에서 높은 점수를 얻으며 성능적인 측면 확인
Introduction.
- 일반적인 TTS
TTS(Text-to-Speech)란 문자를 음성으로 변화시키는 시스템으로,
정보가 매우 압축된 텍스트를 Decompress 하여 오디오로 변환하는 일종의 대규모 역변환 문제이다.
일반적으로는 다음과 같이 구성된다.
- 언어적 정보를 추출하는 Frontend 모델
- 음향 모델
- 오디오 합성 모듈
TTS는 각 요소들을 구성하는데 광범위하고 전문적인 지식이 필요하기 때문에 설계의 난이도가 높고, 요소 별로 독립적이기 때문에 오차들이 누적될 가능성이 높다는 단점이 있다.
- end-to-end TTS
해당 문제를 해결하기 위해 텍스트와 음성을 쌍으로 학습 가능한 end-to-end TTS가 등장한다.
이 시스템의 경우
- 불안정성을 유발하는 Feature Engineering의 필요를 줄이고
- 말하는 사람, 언어, 감성 등 High-level의 특징을 조절하기 쉽고
- 새로운 데이터에 더 쉽게 적응하고
- 여러 단계로 구성된 모델보다 더 견고하다.
위와 같은 장점을 활용하여 본 논문은 attention 기반의 sequence-to-sequence(이후 seq2seq) 모델을 기반으로 하는 Tacotron을 제시한다.
이전에 TTS를 딥러닝으로 구현하고자 한 연구들은 아래와 같은 한계점이 있다.
- WaveNet : 샘플 단위로 autoregressive한 연산을 해야 해서 속도가 느림
- DeepVoice : TTS의 각 단계를 NN으로 대체했지만 end-to-end가 아님
그러나 Tacotron의 경우, end-to-end에 매우 근접하고,
글자에 따른 발음을 정렬해 제공하지 않아도 되어 즉시 학습이 가능한 장점이 있다.
Tacotron.
1. Model Architecture
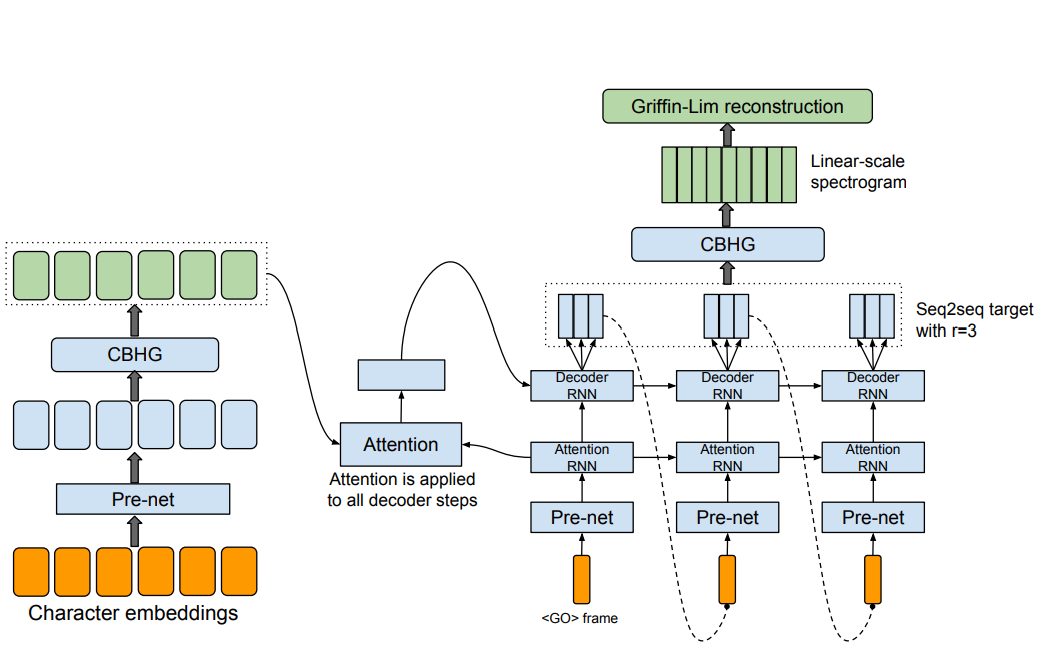
전형적인 Attention 기반의 seq2seq 모델이다.
- seq2seq 모델
seq2seq 모델이란 시퀀스를 입력받아 시퀀스를 출력하는 과제를 수행하는 RNN 기반의 모델로,
시퀀스를 받아들이는 부분(인코더)과 출력하는 부분(디코더)이 분리된 것이 특징이다.
인코더가 시퀀스를 받아들이면 Context vector라는 고정된 크기의 벡터로 변환하고,
디코더는 인코더가 변환한 Context vector를 받아 출력 시퀀스를 출력하는 원리이다.
- Attention
Attention은 입력 시퀀스가 많을 때, 인코더가 모든 정보를 하나의 Context vector로 압축하는 과정에서 발생하는 손실을 줄이기 위해 생성된 메커니즘이다.
디코더에서 시퀀스의 다음 단어를 예상하기 위해 인코더가 만드는 매 순간의 벡터를 사용하는 방식으로
특정 시점에 인코더의 벡터에 집중하여 디코더의 출력해야 하는 벡터와의 유사도를 계산하고,
그 값을 활용하여 다음 단어를 예측하는 것이다.
이를 통해 매 시점의 정보가 디코더로 넘어가기 때문에 시퀀스의 길이가 길어도 손실되는 정보가 거의 없다.
Tacotron의 구성을 살펴보면,
문자를 입력 받는 인코더와 attention 기반의 디코더, post-processing net으로 되어있다.
해당 요소들을 거친 문자는 Linear-spectrogram으로 변환되고
Grifin-Lim을 통해 실제 오디오의 waveform으로 변환하는 과정을 거친다.
- CBHG module
인코더와 디코더에 존재하는 모듈이다.
시퀀스를 처리하는데 특화된 모듈로, Input과 Output이 모두 시퀀스로 이뤄진다.

다음과 같은 과정에 따라 진행된다.
- 시퀀스를 1부터 K개의 필터를 가진 1D Convolution bank에 통과시켜 Feature 벡터 생성
- Feature 벡터를 Max polling Layer에 통과시켜 시퀀스의 변하지 않는 부분을 추출
- 고정된 폭을 가진 몇 개의 1D Convolution Network를 통과시켜 시퀀스와 벡터 사이즈가 일치하는 벡터를 생성
- (3)에서 만든 벡터와 입력받은 시퀀스의 벡터를 더해 Residual Connection을 구성
- 생성된 벡터를 Highway 네트워그에 통과시켜 High-level features를 생성
- 생성한 Feature를 GRU에 입력
이 과정을 통해 모델을 깊게 쌓아 학습 과정에서 빠르게 수렴할 수 있도록 돕는다.
- 인코더
Speech로 변환할 문자 시퀀스를 입력받아 특정 시퀀스로 변환한다.
각 문자는 One-Hot vector로 표현되고, Continuous vector로 임베딩된다.
다음과 같은 과정으로 변환된다.
- Embedding Matrix를 이용해 One-Hot 벡터로 표현된 Input을 벡터로 변환
- 벡터를 Pre-net 모듈에 통과
- 통과시킨 벡터를 CBHG에 넣어 어텐션 모듈에 활용될 시퀀스 벡터 생성
- 디코더
인코더를 통해 생성된 시퀀스 벡터와 이전 시점까지 생성된 디코터의 멜 스펙토그램으로 현재 시점의 멜 스펙토그램을 생성한다.
다음과 같은 과정으로 변환된다.
- t-1 시점까지 디코더가 생성한 멜 스펙토그램을 Pre-Net 모듈에 통과
- 통과해 생긴 벡터를 Attention-RNN의 Input으로 사용
- 이로 인해 추출된 시퀀스 hidden vector를 어텐션 모듈에 넣어 Context vector를 추출
- Attention-RNN hidden vector와 Context vector를 Concatenate 해 Decoder-RNN의 Input으로 사용
- Decoder-RNN에서 추출된 결과 = 디코더의 Output = t 시점의 멜 스펙토그램
- Post-processing net
디코더에서 생성된 멜 스펙토그램으로 Linear spectogram을 생성한다.
멜 스펙토그램의 전체 모습을 보고 생성하며 오디오 파형으로 변환하기 쉽도록 Linear spectogram을 만드는 것이 목적이다. 고차원을 요구하는 작업이므로 디코더에서 바로 진행하지 않고 후처리로 진행한다.
이후 Griffin-Lim 알고리즘을 이용해 Spectogram을 오디오 파형으로 변환한다.
Model details.
모델의 상세 디테일은 다음과 같다.

Experiments.
실제 전문 여성 성우가 24.6시간 가량 녹음하였고 음성이 포함된 Internal North American English dataset을 학습시켰다.
문장들은 모두 영문으로 정규화되었다.
1. Ablation analysis
비교 모델은 다음과 같다.
A. vanilla seq2seq : 디코더가 직접 Linear Spectogram을 예측하여 Pre-Net과 Post-processing net 제외
B. GRU 인코더 모델 : CBHG 인코더를 2-Layer residual GRU로 대체

- vanilla seq2seq의 경우, 많은 프레임을 쌓은 것처럼 보이는데 이는 합성된 신호에서 좋지 않음
- GRU 인코더 모델의 경우, alignment가 상대적으로 더 Noisy 함
- 가장 깨끗하고 부드러운 alignment 보임
불안정한 alignment는 잘못된 발음으로 이어지기 때문에 깨끗한 alignment일수록 길고 복잡한 구절도 잘 변환한다는 것을 알 수 있다.
2. Post-processing net 비교
Post-processing net의 유무에 따른 결과를 확인해 보면 다음과 같다.
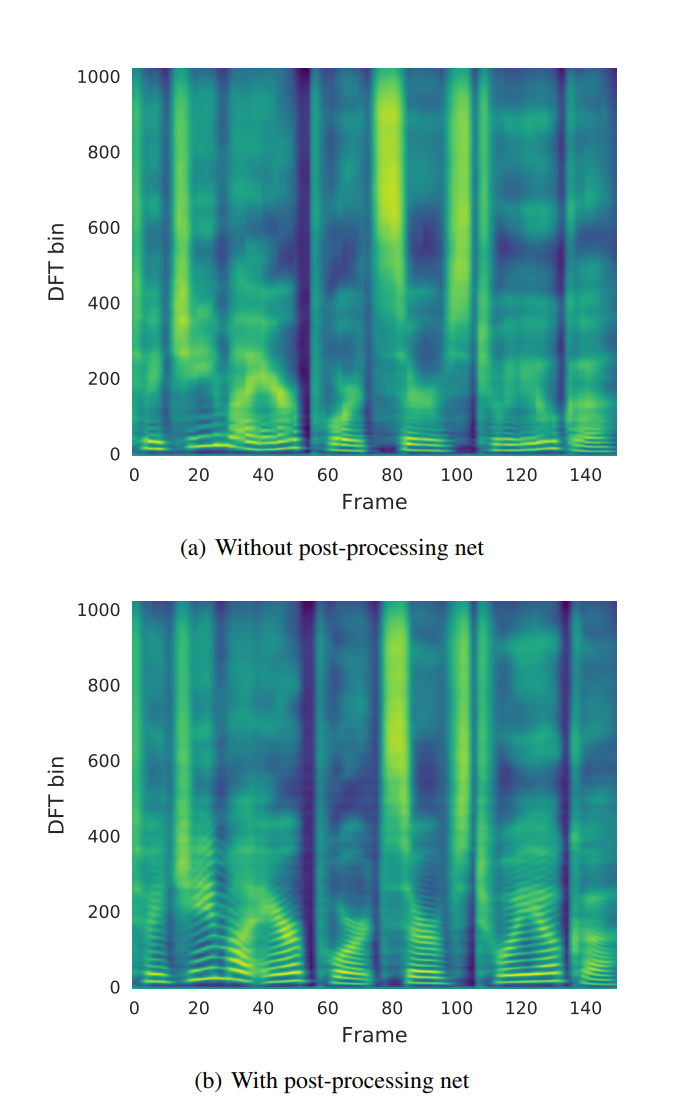
(b) With post-processing net에서 DFT bin 하단 부분에 더 많은 줄무늬를 형성한 것을 볼 수 있는데, 이는 더 많은 Harmonic을 생성한 것을 의미하며 더 자연스러운 소리를 생성했다는 것을 말한다.
3. Mean Opinion Score Tests
생성된 음성을 피실험자에게 들려줘 점수를 매기는 MOS Test를 5 point 리커트 척도를 사용해 진행한 결과 다음과 같다.
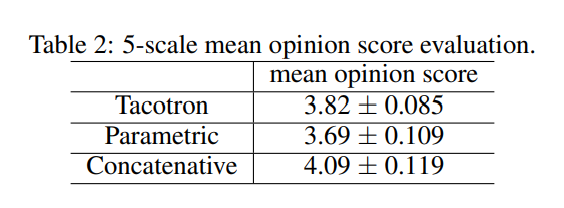
LSTM을 사용하는 'Parametric' 보다 높은 점수를 받은 것을 알 수 있다.
'Concatenative' 보다는 점수가 낮은 것을 볼 수 있는데, 이 모델의 경우 전문가의 텍스트 분석과 음향 모델링 등이 필요하다. 반면, Tacotron은 전문가의 개입이 필요하지 않기 때문에 상대적으로 좋은 결과임을 알 수 있다.
Discussions
Attention 기반의 end-to-end TTS 모델 Tacotron을 제시했다.
전문적인 지식이나 복잡한 과정을 줄이고, 간단한 waveform 합성기 모듈을 통해 자연스러운 오디오를 형성했다.
하지만 여전히 개선 가능성이 있고, 특히 Graffin-Lim 출력의 경우 오디오 파형을 합성하는 과정에서 문제가 있으므로
더 높은 퀄리티의 Neural-network-based Spectogram inversion 연구가 필요하다.
PS. 본 논문은 이후 WaveNet을 음성 합성에 사용하는 Tacotron2 논문으로 발전하게 된다.



