
https://paperswithcode.com/paper/ccnet-extracting-high-quality-monolingual
Papers with Code - CCNet: Extracting High Quality Monolingual Datasets from Web Crawl Data
Implemented in 2 code libraries.
paperswithcode.com
1. Introduction
사전 학습된 텍스트 표현은 많은 자연어 처리 작업에서 성능 향상을 가져왔다. 트랜스포머와 BERT의 도입 이후 사전 학습된 모델의 품질이 꾸준히 향상되어 왔으며 이는 주로 사전 학습된 코퍼스의 크기가 커진 것에 따른 것이다. 그러나 크기가 커지는 것뿐만 아니라 데이터의 품질을 유지하는 것도 중요하기 때문에 Wikipedia와 같은 기존의 고품질 데이터 소스를 연결하여 만든 임시 데이터셋을 사용하게 되었다. 그러나 이러한 데이터셋은 리소스가 부족한 언어의 경우 데이터셋 자체가 적기 때문에 복제하기 어렵다. 그래서 이 논문에서는 리소스가 부족한 언어를 포함하여 다양한 언어로 고품질의 코퍼스를 수집할 수 있는 데이터 수집 파이프라인, CCNet을 소개한다.
2. Related Work
이전 연구들 중에서는, word2vec, GloVe, fastText와 같은 단어 임베딩 기술을 사용하여 대규모 데이터셋을 전처리하는 방법이 소개되었다. 이 논문에서는, Common Crawl 데이터셋을 사용하여 문장 수준 임베딩 모델을 학습하는 방법을 제안한다. 이전 연구에서는 Common Crawl 데이터셋을 언어 모델링에 사용하여 n-gram 통계를 평가하는 데 사용되었으며, 최근에는 Baevski et al. (2019)에서 Common Crawl 데이터셋을 전처리하여 BERT와 유사한 모델을 학습하는 데 사용되었다. 이러한 연구들은 pre-training corpora의 크기를 증가시킴으로써 문장 임베딩 모델의 성능을 향상시키는 것이 중요하다는 것을 보여준다.
3. Methodology
매월 Common Crawl은 무작위로 URL을 탐색하고 샘플링하여 얻은 웹의 스냅샷을 공개한다. 월별 스냅샷 간에는 콘텐츠 중복이 거의 없으며 전체 아카이브는 8년 동안 웹 크롤링을 통해 수집된 페타바이트 규모의 데이터로 구성되어 있다. 웹 페이지는 제한 없이 전체 웹에서 크롤링되며, 다양한 언어로 제공되고 텍스트의 품질도 다양하다. 이 논문에서는 공동 크롤링 데이터를 가져오고, 추론하고, 필터링하는 데 사용되는 방법론을 설명한다.

1) 전처리
각 스냅샷에는 압축되지 않은 일반 텍스트가 20~30TB 정도 포함되어 있으며, 이는 약 30억 개의 웹 페이지에 해당한다. 각 스냅샷을 독립적으로 다운로드하여 처리하며, 각 스냅샷에 대해 WET 파일을 각각 5GB의 조각으로 재그룹화한다. 그리고 이러한 조각들은 하나의 항목이 하나의 웹 페이지에 해당하는 json 파일로 저장된다.
2) 중복 제거
CCNet 파이프라인의 첫 번째 단계는 텍스트의 70%를 차지하는 중복된 단락을 여러 웹 페이지에서 한 번에 제거하는 것이다. 모든 문자를 소문자로 바꾸고, 숫자를 자리 표시자로 바꾸고, 모든 유니코드 구두점과 악센트 표시를 제거하여 각 단락을 정규화한다. 그 후 중복 제거는 두 가지 독립적인 단계로 수행된다. 먼저, 모든 조각들에 대해 각 단락에 대한 해시 코드를 계산하여 바이너리 파일에 저장한다. 이 때 첫 번째 정규화된 단락의 64비트 SHA-1 숫자를 키로 사용한다. 그 후 모든 조각들을 1, 하위 집합 또는 모든 바이너리 파일과 비교하여 중복을 제거한다. 이 단계는 각 부분에 대해 독립적이며 웹 복사본을 제거하는 것 외에 탐색 메뉴, 쿠키 경고, 연락처 정보와 같은 많은 상용구를 제거한다. 특히 다른 언어로 된 웹 페이지에서 상당한 양의 영어 콘텐츠를 제거하여 다음 단계인 언어 식별이 더욱 강력해진다.
3) 언어 식별
CCNet 파이프라인의 두 번째 단계는 언어별로 데이터를 분할하는 것이다. fastText의 언어 분류기를 사용하며 특징 문자로 n-그램과 계층적 소프트맥스를 사용한다. 176개 언어를 지원하며 각 언어에 대해 [0, 1] 범위의 점수를 출력한다. 그렇게 모든 웹 페이지에 대해 가장 가까운 언어에 대한 점수를 계산하고 점수가 0.5보다 높으면 해당 언어로 문서를 분류하고 그렇지 않으면 문서를 삭제한다.
4) LM 필터링
이 단계에서도 여전히 품질이 낮은 문서가 존재한다. 이것을 걸러내는 방법으로는 타깃 도메인의 유사성 점수를 계산하는 방법이 있다.
5) 파이프라인 없이 결과 재현
4. Ablation Study



통상적으로 LID 후 중복 제거를 하는 것과 달리 중복 제거를 먼저 수행하고 LID를 수행했다. 이유는 다른 언어의 페이지에 많은 영어 보일러플레이트가 포함되어 있어 중복 제거 이전에 많은 저자원 언어 문서가 잘못 분류되었거나 (일반적으로 영어로) 언어를 식별할 수 없어서 폐기되었다는 것을 관찰했기 때문이다. 중복 제거는 이러한 노이즈 데이터의 상당 부분을 제거하므로 언어 식별이 더 잘 이루어진다. 그래서 "LID 후 중복 제거"를 수행할 때 문서 수에 비해 상대적으로 증가하였다. 또한, 필터링 단계가 결과 데이터셋의 크기와 품질에 미치는 영향에 대해 논의한다. Wikipedia와 같은 고품질 소스에 가까운 문서를 선택하기 위해 5-gram Kneser-Ney 모델을 사용한다. 필터링 단계는 데이터셋의 크기를 줄이지만 품질을 향상시킨다.
5. Metrics about the resulting dataset



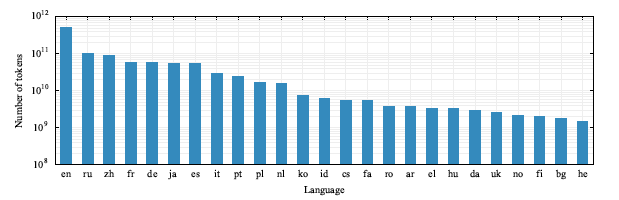
결과 데이터셋에 대한 메트릭은 다양한 언어에 대한 문서 수, 토큰 수, 언어 모델 퍼플렉서티 등이 포함된다. 중복 제거 단계 이후 각 언어별 토큰 수는 히스토그램으로 시각화되어 있으며, 로그 스케일로 표시된다. 필터링 단계에서는 5-gram Kneser-Ney 모델이 사용되며, 이 모델은 KenLM 라이브러리에서 구현되었다. 이 모델은 대규모 데이터를 처리하는 데 효율적이며, 필터링 단계에서는 Wikipedia와 같은 고품질 소스에 가까운 문서를 선택한다. 이러한 메트릭은 결과 데이터셋의 품질과 크기를 평가하는 데 사용된다.
6. Conclusion
이 논문에서는 100개 이상의 언어로 선별된 단일 언어 코퍼스를 생성하는 파이프라인인 CCNet을 소개하였다. 일반적인 크롤링은 (Grave et al., 2018)의 파이프라인을 따라 진행하지만, 문서의 구조를 보존하고 Wikipedia와의 차이에 따라 데이터를 필터링한다는 점에서 차이가 있다. 이렇게 함으로써 결과 데이터셋의 품질이 향상되고 XLM과 같은 다국어 텍스트 레벨의 표현을 학습할 수 있다.



