
# SML
- 딥러닝 이전의 전통적인 Language Model
- 딥러닝이 등장하기 전 전통적인 언어 모델이다.
- 통계적 언어 모델로 SLM이라고 한다.
- 해당 모델을 알기 전에 조건부 확률의 연쇄 법칙(Chain Rule)을 알아야 하는데 이는 아래 식과 같다.
P(x_1,x_2,x_3,...x_n)=P(x_1)P(x_2|x_1)...P(x_n|x_1x_2...x_{n-1})
- 예를 들어 문장 “I like dogs and cats”을 생성할 때 해당 문장이 생성될 확률은 다음과 같다.
P(I,like,dogs ,and, cats)=P(I)P(like|I)P(dogs|I,like)P(and|I,like,dogs)P(cats|I,like,dogs,and)
- 이때 각 단어에 대한 확률은 카운트를 기반으로 계산이 된다.
- 예를 들어 모델이 학습한 단어들에서 보지 못한 새로운 단어가 있다면 이 단어에 대한 확률은 0이다.
- SLM의 대표적인 예시: N-gram
- 예를 들어 When I was cleaning my room, he scored ____. 에서
빈칸에 들어오는 단어를 예측하기 위해서 전체 단어를 고려하는 것이 아닌 N개의 단어 만을 고려하게 된다.
- N이 3이라고 할 때 빈칸 x를 예측하기 위한 식은 다음과 같다. P(x| room he scored) 이때 빈도를 기반으로 P(paper|room he score)= 0.256, P(goal|room he score)=0.513 해당 단어들이 등장할 확률이 나오게 된다.
- N-Gram은 간단히 말해서 주위 n개의 단어를 참고하여 단어를 예측하는 모델이다.
- 이렇게 충분한 데이터를 관측하지 못해 정확히 모델링하지 못하는 문제를 희소 문제라고 한다.
- 이때 발생하는 문제점은 바로 **희소 문제(Sparsity Problem)**이다.
## RNN
(https://www.fit.vutbr.cz/research/groups/speech/publi/2010/mikolov_interspeech2010_IS100722.pdf)
- RNN기존 전통적인 모델은 순차적인(시계열) 데이터를 가지고 다음 데이터(Ex 단어)를 예측하는데 어려움을 겪고 있다.
- 현재 언어 존재하는 언어 모델들은 simple baseline에서 작은 수준의 향상을 보여주고 있다.
- Intro
Model Description
신경망을 언어 모델에 사용하는 것은 획기적인 발전을 이뤘지만 이전 모델은 fixed context만을 고려한다.
반면에 RNN은 제한된 context를 고려하지 않고 해당 정보는 긴 시간 동안 순환한다.
해당 논문에서는 이전에 소개된 simple recurrent neural network 구조를 사용한다.
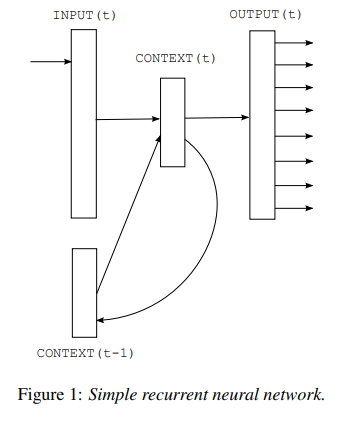
모델의 수식은 아래와 같다.

- x는 입력, s는 hidden layer / context layer라고 한다.
- w는 현대 단어를 표현하는 벡터와 이전 hidden state s의 concat으로 입력이 생성된다.
- 해당 식에서 f는 시그모이드 함수이고 g는 소프트맥스 함수이다.
- 초깃값으로 s(0)은 0.1 같은 매우 작은 값을 나타낸다.
- 벡터 x의 크기는 vocabulary V+hidden size와 같고
- w(t)는 현재 단어를 1-of-N 인코딩한 벡터이다.(원핫인코딩)
- y는 각 단어에 대한 확률 분포를 나타내는 벡터로 출력된다.
- 일반적으로 V는 30000-200000 사이의 값이고 hidden layer의 size는 30-500 사이이다.
모델 훈련 테크닉
- 훈련 시 Back Propagation과 Gradient Descent 알고리즘을 사용했다.
- 이때, learning rate는 0.1이고 매 epoch마다 learning rate를 반틈씩 작아지게 했다.
- 10-20 epoch가 지나면 일정 수준으로 수렴했다.
- Loss함수는 Cross Entropy 함수로 사용되었다.

```
Optimization
성능을 높이기 위해 일정 임계치 이하로 등장하는 단어들을 모아서 special rare token으로 합쳐줬다.
그리고 단어 확률은 다음과 같이 계산된다.

```
이때 C_rare은 임계치 이하의 단어의 총합이다. 그러므로 모든 rare 단어들은 같은 값으로 나눠진다.
Conclusion
RNN이 현재 모델보다 더 높은 성능을 보였다. (심지어 더 큰 데이터 셋으로 학습했을 때도)
동일한 조건에서 Word error rate는 18%가 감소했다.
Perplexity 또한 엄청나게 감소했다.
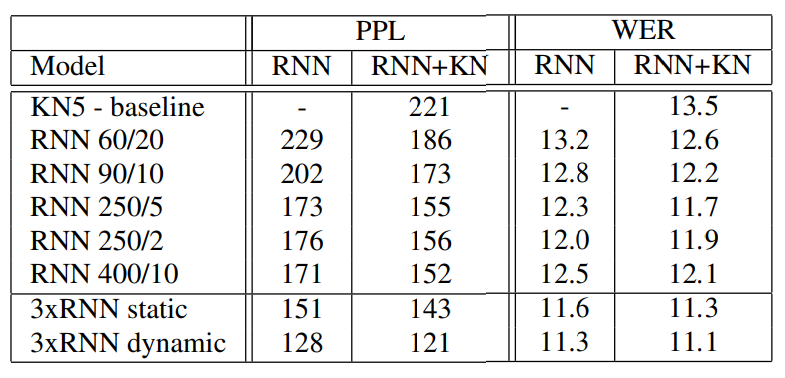
하지만 이렇게 간단한 신경망 모델이 긴 context information을 제대로 포착할 수 있다고 생각하지 않는다.
+ Perplexity, PPL
NLP모델에서 두 모델의 성능을 비교할 때 쓰이는 지표
Perplexity: 헷갈리는, 당황스러운
⇒즉 낮을수록 성능이 좋다!
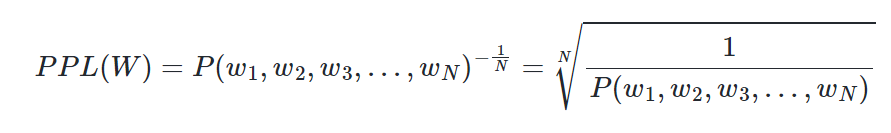
Chain Rule에 의해 다음과 같이 바뀐다.
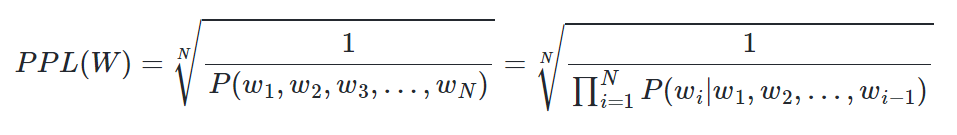
만약 모델이 각 time step마다 평균 5개의 uniform 확률 분포 선택지에서 고려한다면 PPL값은 5가 된다.
⇒ 즉 적은 선택지를 가질수록 좋다.



