
https://arxiv.org/pdf/2305.13062.pdf
Abstract
- 이 논문에서는 대형 언어 모델(Large Language Models, LLMs)이 구조화된 데이터, 특히 테이블과 같은 데이터를 얼마나 이해하는지에 대한 연구를 진행하고자 한다.
- 테이블은 LLMs에 직렬화(serialization)를 통해 입력으로 사용될 수 있지만, 이러한 데이터를 LLMs가 실제로 이해할 수 있는지에 대한 포괄적인 연구가 부족하다.
- 논문에서는 LLMs의 구조적 이해 능력(Structural Understanding Capabilities, SUC)을 평가하기 위한 벤치마크를 설계하였고, 이를 통해 GPT-3.5와 GPT-4에 대한 일련의 평가를 실시한다.
- 벤치마크에는 셀 조회, 행 검색 및 크기 감지와 같은 각각 고유한 도전 과제를 가진 일곱 가지 작업이 포함되어 있다.
- 실험에서는 다양한 입력 선택지에 따라 성능이 달라지며, 이에 대한 인사이트를 통해 자가증식(self-augmentation) 방법을 제안하고 이를 통해 다양한 테이블 작업에서 LLMs의 성능이 향상됨을 보여준다.
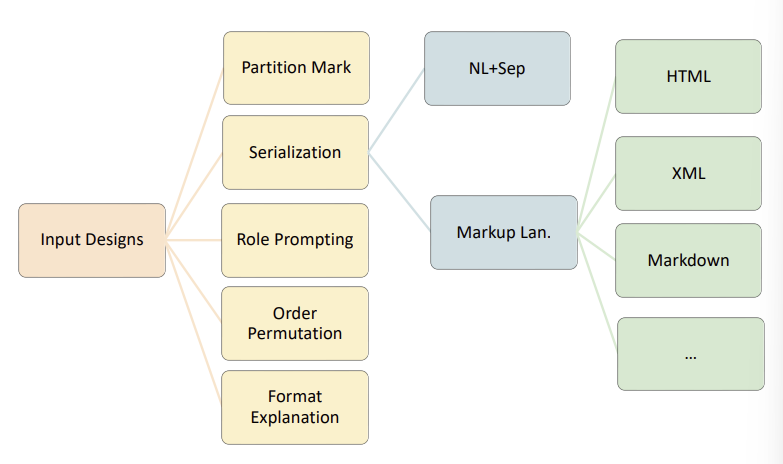
- 테이블 입력 형식, 내용 순서, 역할 프롬프팅 및 분할 표시와 같은 여러 입력 선택에 따라 성능이 다양하게 나타났다.
- 코드 및 데이터는 https://github.com/Y-Sui/GPT4Table에서 공개되어 있다.
INTRODUCTION
- 구조화된 데이터는 사전에 정의된 구조에 따라 조직된 일반 텍스트 블록으로 구성되어 반복되는 정보를 압축한다. 이는 데이터를 더 효과적으로 관리하며 기계에 의한 데이터 분석 및 처리를 용이하게 한다.
- 테이블은 Table-based Question Answering (TQA), Table-based Fact Verification (TFV), Table-to-Text, 그리고 Column Type & Relation Classification와 같은 여러 응용 분야에서 사용되는 구조화된 데이터 유형 중 하나이다.
- 구조화된 데이터의 채택은 정보 검색 및 웹 마이닝, 콘텐츠 분석에서 지식 추출의 발전에 크게 기여했다.
- 프롬프트 엔지니어링은 문맥 학습(in-context learning)에 대한 매우 효과적인 방법으로 입증되었다.
- 프롬프트(prompt): 챗GPT(ChatGPT)와 같은 대규모 언어 모델 기반의 생성형 인공지능은 텍스트를 입력받고 이에 대한 응답을 생성하는데, 이때 입력하는 텍스트 또는 질문 https://100.daum.net/encyclopedia/view/55XXXXX98533
- 프롬프트(prompt): 챗GPT(ChatGPT)와 같은 대규모 언어 모델 기반의 생성형 인공지능은 텍스트를 입력받고 이에 대한 응답을 생성하는데, 이때 입력하는 텍스트 또는 질문 https://100.daum.net/encyclopedia/view/55XXXXX98533
문제 제기
- 그러나 이전 연구들은 LLMs가 테이블 데이터를 실제로 이해할 수 있는지에 대한 포괄적인 연구를 제공하지 않았거나, LLMs가 이미 어느 정도의 구조적 이해 능력을 갖추었는지에 대한 상세한 논의를 제공하지 않았다. 또한, 자연어 처리에서의 놀라운 성공에도 불구하고 테이블 데이터 모드에 대한 LLMs의 적용은 고유한 도전이다. 각각의 테이블은 구조와 특징을 다른 방식으로 정의하며 순차적 텍스트로 직접 변환하기 어렵다(테이블 직렬화).
- 즉, 테이블 작업에 대한 LLMs의 상식적이거나 철저한 입력 디자인이 무엇인지에 대한 확고한 합의나 포괄적인 조사가 부족하다. 이전 연구들은 다양한 입력 디자인을 적응적인 방식으로 사용했다.
- TaPEx는 헤더 및 행과 같은 구성 요소를 나타내는 특수 토큰을 사용했다.
- TABBIE는 행별 및 열별로 테이블을 직렬화했다.
- TableGPT는 각 테이블 레코드에서 속성-값 쌍을 직렬화하는 템플릿 기반 방법을 사용하며, "name: Elon Musk"를 "name is Elon Musk."로 변경하고 레코드 순서에 따라 모든 문장을 연결한다.
- 입력 디자인의 다양성과 복잡함은 이 분야의 연구자와 개발자들이 직면한 어려움을 더욱 복잡하게 만든다. 따라서 본 논문에서는 다음 질문에 대한 답을 찾고자 한다. "LLMs가 테이블을 이해하는 데 가장 효과적인 입력 디자인 및 선택은 무엇인가?”
목표 및 방법
- 본 논문의 목표는 다양한 입력 디자인을 다루고 LLMs가 테이블 데이터를 실제로 이해할 수 있는지 여부를 결정하는 것이다. 또한, LLMs가 이미 어느 정도의 구조적 이해 능력을 보유했는지에 대한 논의를 목표로 한다.
- 이를 달성하기 위해 우리는 SUC (Structural Understanding Capabilities)라는 벤치마크를 제안하여 여러 입력 디자인을 비교하고 LLMs의 각 구조적 이해 능력에 중점을 둔 구체적인 작업을 만들었다.
- 여러 입력 선택의 효과를 평가하기 위해 우리는 다양한 프롬프트 변형을 사용한 일련의 실험을 수행한다.
- 입력 형식, 형식 설명, 역할 프롬프팅, 분할 표시, 제로샷 / 원샷
사전 지식
1. 테이블 구조
- 테이블 데이터는 유연성 있는 다양한 구조로 나타나며, 이러한 구조에는 관계형 테이블, 엔터티 테이블, 행렬 테이블, 레이아웃 테이블 등이 포함된다. 테이블은 수평 또는 수직 방향으로 구성되며 평평한 것에서 계층적인 것까지 스펙트럼을 가지고 있다.
- 본 논문에서는 주로 flat 관계형 테이블에 중점을 두지만 ToTTo와 같은 계층적 테이블에 대한 논의도 일부 다룬다. 이러한 테이블에서 각 행은 구별되는 레코드에 해당하며, 열은 계층 구조적 배열 없이 특정 필드를 나타내다.
- 테이블 데이터는 값의 형식 지정에 대한 다양한 접근 방식을 보여줍니다. 이러한 형식에는 텍스트, 숫자, 날짜/시간, 수식 및 기타 관련 정보가 포함된다.
- 특히 텍스트는 헤더, 주석, 캡션 및 데이터 영역 내의 셀과 같은 메타 정보를 포착하여 테이블에서 중요한 역할을 한다.
- 반면, 숫자는 종종 합산 및 비율과 같은 산술적 관계뿐만 아니라 분포와 추세와 같은 통계적 속성을 포함한다.
- 테이블 직렬화 및 분할
- 테이블 직렬화는 테이블에서 데이터를 선형 및 순차적인 텍스트 형식으로 변환하는 과정을 의미하며, 이는 LLMs의 훈련 및 활용에 필수적이다.
- 간단한 직렬화 함수는 테이블을 행별로 직렬화하는 것이다. TaPas, MATE, TableFormer, TUTA, 그리고 TURL과 같은 많은 작업들이 이 방법을 사용한다.
- TaPEx는 헤더 및 행과 같은 구성 요소를 나타내기 위해 특수 토큰을 사용한다.
- TABBIE는 테이블을 행별 및 열별로 모두 직렬화한다.
- TableGPT는 각 테이블 레코드에서 속성-값 쌍을 직렬화하기 위해 템플릿 기반 방법을 사용한다.
- 대부분의 LLMs는 긴 문장을 처리하는 데 비효율적이므로 특정 제약 조건을 미리 정의했다.
- (1) 잘림에 의한 잠재적인 혼동을 피하기 위해 테이블의 토큰 수가 특정 임계값을 초과할 때 무작위 행 샘플링 전략을 사용한다.
- (2) 추정된 남은 토큰 용량에 기반하여 1회성 예제를 추가한다.
SUC 벤치마크
- 다양한 입력 디자인을 비교하고 LLMs의 구조적 이해 능력을 조사하기 위한 벤치마크를 개발했다.
- 주로 LLMs가 테이블을 어떻게 이해하는지를 비교하고, 구조적 이해 능력을 조사한다.
- 어떤 입력 디자인이나 선택이 LLMs의 테이블 이해에 효과적인지
- 이미 LLMs가 구조화된 데이터에 어느 정도 이해 능력을 보유하고 있는지
- 다양한 입력 디자인의 복잡한 트레이드 오프를 분석한다.
구조적 이해 능력
우리는 테이블 구조를 인간적인 시각에서 이해하는 데 필요한 핵심 능력을 두 가지 구분으로 나눈다.

Partision & Parsing: 테이블 데이터셋은 항상 다른 출처의 지식과 짝을 이루어 추가적인 맥락을 제공하고 특정한 하위 작업을 해결한다. 테이블을 다른 지식과 조합하여 하위 작업을 수행하기 위한 전제 조건으로, 이를 위해 데이터를 정확하게 파티셔닝하고 테이블의 구조적 레이아웃을 기본적으로 이해해야 한다. 또한, 다양한 테이블 저장 형식과 이에 따른 도전 과제에 대한 논의가 있으며, 특히 이러한 포맷 소스를 정확하게 파싱하고 어떤 입력 디자인이 LLMs에게 가장 적합한지를 결정하는 방법을 확인하려고 한다. 또한, LLMs가 이미 모든 유형의 저장 형식을 처리할 수 있는 능력이 있는지도 확인할 수 있다.
Search & Retrieval: 구조화된 데이터 내에서 특정 위치에서 정보를 정확하게 검색하고 검색하는 능력에 중점을 둔다. 이 능력은 Table-QA 및 Column Type & Relation Classification을 포함한 다양한 하위 작업과 관련이 있으며 사용자의 질문이나 요청에 기반하여 구조화된 데이터에서 관련 정보를 효과적으로 식별하고 추출하는 데 도움이 된다. LLMs의 하위 작업에서 검색 및 검색 능력을 분리함으로써 테이블 데이터에 대한 LLMs의 내부 학습 프로세스에 대한 유용한 통찰력을 얻는다.
데이터 수집 및 SUC의 형식 재정비
LLMs의 테이블 이해 능력을 평가하기 위해 여러 특정 작업을 디자인했다. 이러한 작업들은 난이도를 점진적으로 증가시키는 방향으로 디자인되었다.
- 테이블 파티션: 테이블의 구조를 식별하는 능력, 주어진 사용자 입력 디자인 내에서 테이블의 경계를 감지해야 한다.
- 테이블 크기 감지: 구조적 정보를 올바르게 파싱하는 능력, 테이블 크기 특징은 테이블에 인코딩된 행과 열의 수에 대한 직접적인 제약 사항을 나타내므로 중요한 특징이다.
- 병합된 셀 감지: 병합된 셀을 감지함으로써 LLM의 구조적 정보 파싱 능력을 평가 LLMs의 견고성을 테스트하기 위해 우리는 병합된 셀을 계층적 스프레드시트 테이블의 기능으로 고려한다. 병합된 셀이 포함된 테이블이 주어진 경우 LLM은 (𝑟𝑖, 𝑐𝑗)와 같은 병합된 셀 인덱스를 감지해야 한다.
- 셀/열 검색: 구조적 정보를 검색하는 능력, 특정 위치에서 셀 값을 정확하게 검색해야 한다. 이 작업은 정보 파티셔닝과 파싱 능력에 의존한다.
- TabFact, FEVEROUS, SQA, HybridQA, 그리고 ToTTo와 같은 다양한 공공 데이터셋으로부터 구조화된 데이터를 수집한다.
- 모든 테이블은 Wikipedia에서 가져온 것이며, 우리는 원본 데이터셋의 "table," "rows," 또는 "headers"와 같이 레이블이 지정된 구조적 부분만을 고려하며, "ID," "Answer," "Question," "FileName"과 같은 다른 부분은 제외한다.
- 구조화된 데이터 내에서 특정 값을 식별하기 위해 우리는 각 파싱된 샘플에 독특한 질문을 추가한다. 대부분의 이러한 질문은 한 문장으로 이루어져 있으며 중앙값 길이는 15 단어이다. 각 질문은 원본 데이터셋에서 가져온 "groundtruth"로부터의 참조 답변과 함께 제공된다.
- 예를 들어 "테이블에는 몇 개의 행(열)이 있나요?"와 같은 질문이다.
- 평가를 더 잘 수행하기 위해 대부분의 이러한 질문은 "각 질문에 대답하고 "|"로 답을 나누세요."와 같은 제약 조건과 함께 짝지어진다.
- GPT-3.5 (Text-Davinci-003)2를 사용하여 이러한 질문을 평가하고, 모델이 일정한 temperature 에서 여러 무작위 샘플을 생성할 때 일관되게 정답하는 질문은 수동으로 제거한다.
One-shot 설정
SUC 벤치마크는 테이블 작업을 위한 원샷 인컨텍스트 학습 벤치마크로 설계되었다. 이는 모델이 SUC에서 하나의 예제에 접근하고 답을 생성할 때 일부 컨텍스트를 얻을 수 있다는 것을 의미한다. 대형 언어 모델(Large Language Models, LLMs)은 fine-tuning 없이 few-shot 프롬프트를 따르는 능력을 보여왔다. 이 능력은 작은 언어 모델로는 포착되지 않았습니다. SUC는 LLMs가 가지고 있을지도 모를 잠재 능력을 더 잘 드러내기 위해 이 특성을 활용한다. Zero-shot 설정에서도 실험을 수행하여 비교한다.
평가
CSV, JSON, XML, markdown, HTML, XLSX를 다양한 형식 옵션으로 고려한다. 각 형식은 테이블 콘텐츠를 이해하는 데 LLMs에 대한 다른 정보 압축 수준을 나타내며 다양한 도전 과제를 제시한다. 또한 특별한 토큰을 구분자로 사용하는 것과 같은 가장 일반적인 방법을 기준으로 고려한다. 다른 입력 디자인 옵션에 대한 실험도 수행되며, 각 작업의 정확도를 사용하여 결과를 평가한다.
실험
실험 설정
- 모델: 본 연구에서는 GPT-3.5 및 GPT-4의 성능을 평가한다. 특별한 언급이 없는 한 모든 실험에서는 text-davinci003을 사용한다. 구체적으로 실험을 수행할 때 하이퍼파라미터로는 temperature를 0, top_p를 1로 설정하고, n은 1로 설정한다.
- 하위 작업 및 데이터셋: 벤치마크를 통한 구조화된 데이터 이해 능력을 평가하는 것 외에도, 다섯 가지 테이블 하위 작업에서 실험을 진행합니다.
- SQA (Structured QA): 6,066개의 질문 시퀀스로 구성 데이터셋
- HybridQA: 단일한 형식의 정보가 아닌 다양한 정보에 대한 추론을 요구하는 작업으로, 62,682개의 질문을 포함 데이터셋
- ToTTo: 10만 개가 넘는 예제를 포함하는 고품질 영어 테이블 투 텍스트 데이터셋
- FEVEROUS: 87,026개의 검증된 주장을 포함하는 사실 확인 데이터셋
- TabFact: Wikipedia에서 추출된 테이블과 크라우드 워커들이 작성한 문장을 사용한 사실 확인 데이터셋
벤치마크 강점
다양한 입력 디자인을 사용하여 SUC(SUC Benchmark)의 다양한 구조적 이해 작업에 대한 포괄적인 평가
- HTML 마크업 언어를 사용하고 형식 설명 및 역할 프롬프트가 있는 경우 전반적인 정확도가 가장 높아지며 순서 변경 없이 일곱 작업에 대해 65.43%의 전반적인 정확도를 달성한다. LLM이 이 특정 형식의 테이블의 구조 정보를 이해하는 데 상당한 잠재력을 가지고 있음을 나타낸다.
- 그러나 LLM의 성능은 특정 기능이 제거되었을 때, 특히 프롬프트 예제가 제거된 경우 부정적으로 영향을 받는다.
- NL+Sep (natural language with specific separators) vs. Markup Lan: 자연어와 특정 구분 기호 (NL+Sep) 사용과 HTML, XML 및 JSON과 같은 마크업 언어 사용을 비교한다.
- "NL+Sep"은 일반적으로 테이블 하위 작업에서 사용되지만 결과는 HTML을 포함한 마크업 언어가 6.76% 향상된 성능을 보여준다.
- LLM의 훈련 프로세스가 코드 조정을 포함하고 교육 데이터셋에는 상당한 양의 웹 데이터가 포함되어 있을 것으로 가정하면, LLM은 HTML 및 XML 형식을 해석할 때 더 익숙할 것이다.
- 1-shot vs. 0-shot
- 0-shot 설정일 때 성능이 크게 감소하며, HTML 형식을 사용하여 모든 작업에서 전반적인 정확도가 30.38% 감소한다. 이는 구조적 정보 학습이 맥락 내 학습에 매우 의존적임을 나타낸다. 특히 크기 감지 및 병합 셀 감지와 관련된 작업이 이와 관련되어 있다.
- 테이블 앞에 외부 정보가 나타나야 함
- 입력 디자인의 순서가 미치는 영향을 이해하기 위해 외부 정보를 질문 및 문장과 같이 테이블 뒤로 수동으로 배치했을 때 모든 작업에서 전반적인 6.81%의 성능 감소가 있었다. 테이블 앞에 외부 정보를 배치함으로써 LLM이 더 나은 일반화와 테이블의 구조 정보에 대한 더 많은 컨텍스트를 얻을 수 있기 때문일 수 있다.
- 파티션 마크 및 형식 설명은 검색 및 검색 능력을 저해할 수 있음
- 파티션 마크는 입력 디자인에서 흔히 사용되는데, 파티션 마크에서 영감을 받아 "형식 설명"이라는 다른 선택지를 제안한다. 이것은 채택된 형식에 대한 추가 설명을 제공하는 것이다.
- 예를 들어 HTML 형식의 경우 "각 테이블 셀은 a 및 태그로 정의되며 각 테이블 행은 a 및 태그로 시작하고 a 태그로 끝납니다. th는 테이블 헤더를 나타냅니다."이라고 설명하는 것이다.
- 그러나 Cell Lookup 작업에 대해서는 파티션 마크와 형식 설명을 추가하면 모든 입력 디자인에서 성능이 감소한다. 이는 이러한 추가적인 구조적 정보가 LLM의 탭러 구조를 향해 검색 및 검색 프로세스에 편향을 일으킬 수 있음을 시사한다.
- 그러나 파티션 마크나 형식 설명을 추가하는 것은 병합된 셀 감지와 같은 특정 작업에 대해 어느 정도 이점이 있는 것으로 나타난다.


Conclusion
- 본 논문에서는 테이블에 대한 LLMs(Large Language Models)의 구조적 이해 능력을 연구하기 위해 다양한 입력 디자인을 비교하는 벤치마크를 제안했다.
- LLMs가 테이블의 구조적 정보를 이해하는 데 기본적인 능력을 갖고 있음을 알아냈다.
- 벤치마크의 통찰력을 하위 작업에 어떻게 적용할지에 대한 지침을 제공하고, 자체 지식을 활용하여 추가적인 지식을 생성하는 간단하고 일반적이면서도 효과적인 방법인 self-augmented prompting을 제안한다.
- 이 연구는 향후 테이블 기반 또는 구조화된 데이터 기반 연구에 도움이 되거나, 구조적 관점에서 테이블을 더 잘 이해하는 데 보조 도구로 활용될 수 있을 것으로 기대된다.
윤리적 고려사항
- 구조화된 데이터는 종종 메타데이터를 포함하며, 이는 데이터에 대한 추가 정보를 제공하고 컨텍스트를 제공하는 데 도움이 된다. 구조화된 데이터의 의미와 중요성이 즉각적으로 드러나지 않을 때, 메타데이터 및 다른 문맥적 단서에서 이를 추론해야 하는 것은 어려운 과제이다. 이 능력은 열 유형 예측과 같은 하위 작업에 매우 의존적이다. 이는 더 깊게 탐구해야 할 과제다.
- 더 나아가, 해당 방법론은 주로 영어와 같이 구조가 제한된 언어를 대상으로 한다.



