
해당 논문은 2013년에 Google Deepmind에서 발표한 것으로 심층 강화학습의 시작을 알린 논문으로 여겨집니다.
[Playing Atari with DRL]
https://arxiv.org/abs/1312.5602
Playing Atari with Deep Reinforcement Learning
We present the first deep learning model to successfully learn control policies directly from high-dimensional sensory input using reinforcement learning. The model is a convolutional neural network, trained with a variant of Q-learning, whose input is raw
arxiv.org
<Playing Atari with DRL>
* Abstract
1. 우리는 강화 학습을 사용하여 고차원 감각 입력으로부터 직접 제어 정책을 성공적으로 학습하는 최초의 딥러닝 모델을 제시한다.
2. 이 모델은 합성곱 신경망으로 Q-러닝의 변형을 사용하여 학습되며, 입력은 원시 픽셀이고 출력은 미래 보상을 추정하는 가치 함수이다. 3. 우리는 우리의 방법을 Arcade Learning Environment의 7가지 Atari 2600 게임에 적용하며, 아키텍처나 학습 알고리즘을 조정하지 않았다. 우리는 이 방법이 6개의 게임에서 모든 기존 접근법을 능가하며, 3개의 게임에서 인간 전문가를 초월한다는 것을 발견했다.
* Introduction
* Challenges of DRL
1. 현재까지 성공적인 딥러닝 응용 프로그램들은 대부분 대량의 수작업으로 라벨링된 학습 데이터를 필요로 한다.
→ But, RL 알고리즘은 자주 희소하고, 노이즈가 많으며, 지연된 스칼라 보상 신호로부터 학습할 수 있어야 한다.
2. 대부분의 딥러닝 알고리즘은 데이터 샘플들이 독립적이라고 가정한다.
→ But, 강화 학습에서는 일반적으로 강하게 상관된 상태들의 시퀀스를 다루게 된다는 점이다.
3. 기본적으로 딥러닝 방법들은 고정된 분포를 가정한다.
→ But, RL에서는 알고리즘이 새로운 행동을 학습하면서 데이터 분포가 변화한다.
* Contribution
이 논문은 합성곱 신경망이 이러한 도전 과제를 극복하여 복잡한 RL 환경에서 원시 비디오 데이터로부터 성공적인 제어 정책을 학습할 수 있음을 보여준다.
1. Q-러닝 알고리즘의 변형을 사용하여 학습
2. 확률적 경사 하강법을 사용하여 가중치 업데이트
3. 상관된 데이터와 비정상적인(non-stationary) 분포의 문제를 완화하기 위해 경험 재현 메커니즘을 사용하여 이전 전이 데이터를 무작위로 샘플링함으로써 훈련 데이터 분포를 과거의 다양한 행동에 걸쳐 평활화
* Experimental Results
Arcade Learning Environment (ALE)에서 구현된 다양한 Atari 2600 게임에 적용
→ 시도한 7개의 게임 중 6개에서 이 네트워크는 기존의 모든 RL 알고리즘을 능가했으며, 3개의 게임에서는 인간 전문가를 초월하는 성능을 기록
* 이 네트워크는 어떤 게임에 특화된 정보나 수작업으로 설계된 시각적 특징을 제공받지 않았으며, 에뮬레이터의 내부 상태도 알지 못함
* 인간 플레이어와 마찬가지로, 이 네트워크는 비디오 입력, 보상 및 종료 신호, 그리고 가능한 행동 집합만을 사용하여 학습
* 네트워크 아키텍처와 모든 학습 하이퍼파라미터는 모든 게임에서 일정하게 유지
* Background
* 환경, 행동, 관찰, 보상
* 에이전트가 환경 E (이 경우, Atari 에뮬레이터)와 상호작용하는 작업을 고려
* 각 타임스텝에서 에이전트는 합법적인 게임 행동의 집합 A={1,…,K} 에서 행동 a_t를 선택
* 이 행동은 에뮬레이터로 전달되며, 이는 내부 상태와 게임 점수를 변경
* 에이전트는 에뮬레이터의 내부 상태가 아닌 에뮬레이터에서 현재 화면을 나타내는 원시 픽셀 값 벡터 x_t∈R^d 를 관찰
* 에이전트는 게임 점수의 변화를 나타내는 보상 r_t를 획득
* 행동과 피드백 사이의 타임스텝
* 일반적으로 게임 점수는 이전의 모든 행동 및 관찰 시퀀스에 의존할 수 있으며, 특정 행동에 대한 피드백은 수천 개의 타임스텝이 지난 후에야 받을 수 있음
* 에이전트는 현재 화면 이미지 x_t만 관찰할 수 있기 때문에, 현재 상황을 완전히 이해하는 것이 불가능
* 따라서, 우리는 행동 및 관찰 시퀀스 s_t=(x_1,a_1,x_2,...,a_t−1,x_t) 를 고려하고, 이러한 시퀀스에 의존하는 게임 전략을 학습
* 에뮬레이터 내의 모든 시퀀스는 유한한 타임스텝 내에 종료된다고 가정
* 이 형식은 큰 규모지만 유한한 마르코프 결정 과정(MDP)을 생성하며, 각 시퀀스는 개별적인 상태가 됨 → 단순히 완전한 시퀀스 s_t 를 상태 표현으로 사용함으로써 MDP에 대한 표준 강화 학습 방법을 적용할 수 있음
* 에이전트의 목표는 환경과 상호작용하며 미래 보상을 극대화하는 방식으로 행동을 선택하는 것
* 미래 보상이 타임스텝당 계수 γ 만큼 할인된다고 가정하며, 게임이 종료되는 타임스텝을 T라 할 때 시점 t 의 할인된 미래 보상(return)

* 최적의 행동-가치 함수 Q*(s,a)
* 최적의 행동-가치 함수 Q*(s,a): 어떤 전략을 따를 때 시퀀스 를 관찰하고 행동 를 취한 후 도달할 수 있는 최대 기대 보상
* π: 시퀀스를 행동(또는 행동에 대한 확률 분포)으로 매핑하는 정책
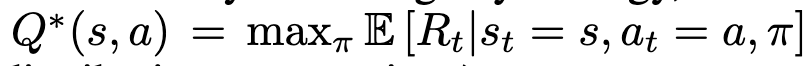
* 벨만 방정식(Bellman equation)
* 만약 다음 타임스텝에서 가능한 모든 행동 에 대한 시퀀스 의 최적 값 Q*(s′,a′)를 알고 있다면, 최적의 전략은 다음 값을 최대화하는 행동 a′ 를 선택하는 것
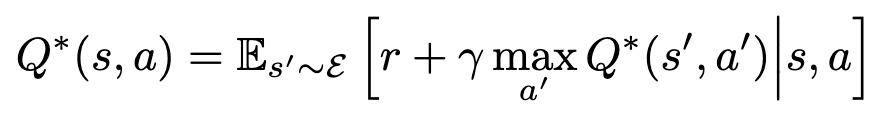
* 강화 학습 알고리즘의 기본 개념
* 벨만 방정식을 반복적인 업데이트(iterative update) 방식으로 사용하여 행동-가치 함수를 추정하는 것
* 가치 반복(value iteration) 알고리즘은 최적의 행동-가치 함수로 수렴

* Q-network
* 위의 기본적인 접근 방식은 실용성이 매우 떨어짐
* 행동-가치 함수가 각 시퀀스마다 별도로 추정되므로 일반화(generalisation) 없이 학습이 진행되기 때문
* 대신, 행동-가치 함수를 추정하는 데 함수 근사(function approximator) 기법을 사용하는 것이 일반적
* Q-network: 가중치 θ를 가진 신경망 함수 근사기

* Loss of Q-network
* Q-network는 매 반복 마다 변경되는 손실 함수 L_i(θ_i) 를 최소화하는 방식으로 학습
* 행동분포(behaviour distribution) 시퀀스 와 행동 에 대한 확률 분포
* 이전 반복에서의 파라미터 θi−1는 손실 함수 Li(θi) 를 최적화하는 동안 고정
* 목표값(target)이 네트워크의 가중치에 의존 → 학습이 시작되기 전에 목표값이 고정되는 지도 학습(supervised learning)과의 차이점
* 아래 그래디언트(gradient) 식의 기대값을 계산하는 대신, 확률적 경사 하강법(stochastic gradient descent, SGD)을 사용하여 손실 함수를 최적화하는 것이 계산적으로 더 효율적
* 가중치가 매 타임스텝마다 업데이트되며 기대값이 행동 분포 ρ와 에뮬레이터 E에서 단일 샘플로 대체되면, Q-러닝 알고리즘에 도달
* 이 알고리즘은 모델-프리(model-free) 방식 → 환경 의 모델을 명시적으로 추정하지 않고 에뮬레이터에서 샘플을 사용하여 직접 강화 학습 문제를 해결
* 이 알고리즘은 오프-폴리시(off-policy) 방식 → 행동 분포를 따르면서도 탐욕적(greedy) 전략을 학습할 수 있음
* 실전에서는 탐색을 위해 ϵ-탐욕적(ϵ-greedy) 전략이 사용: 확률 1−ϵ 로 최적 행동을 선택하고 확률 ϵ 로 무작위 행동을 선택하는 방식

* Deep Reinforcement Learning
* 경험 재현 (Experience Replay)
1. 에이전트의 각 타임스텝에서의 경험 e_t = (s_t, a_t, r_t, s_{t+1})를 데이터셋 D = {e_1, ..., e_N}에 저장
2. 여러 에피소드에 걸쳐 이 경험들을 재현 메모리(replay memory)로 풀링(pooling)
* 경험 재현의 장점
* 경험 재현을 사용하면 행동 분포(behavior distribution)가 여러 이전 상태에서 수집된 샘플을 기반으로 평균화
→ 학습이 평활(smooth)해지고, 파라미터의 진동(oscillations)이나 발산을 방지
* Deep Q-learning
1. 알고리즘의 내부 루프 동안, 저장된 샘플 풀에서 무작위로 샘플링된 경험 e∼D 에 대해 Q-러닝 업데이트 또는 미니배치(minibatch) 업데이트를 적용
2. 경험 재현을 수행한 후, 에이전트는 ϵ-탐욕적(-greedy) 정책에 따라 행동을 선택하고 실행
* 신경망의 입력으로 임의의 길이의 히스토리를 사용하는 것은 어려움 → 함수 ϕ에 의해 생성된 고정 길이의 히스토리 표현 사용

* 표준 온라인 Q-러닝 대비 장점
- 데이터 효율성 증가: 각 경험 샘플이 여러 번 가중치 업데이트에 사용될 수 있어 데이터 활용 효율성 증가
- 샘플 간 상관관계 감소: 경험을 무작위로 샘플링하면 상관관계를 깨뜨려서 업데이트의 분산(variance)을 줄일 수 있다.
- 불안정한 피드백 루프 방지: on-policy 학습에서는 현재의 파라미터가 다음 데이터 샘플을 결정한다. 예를 들어, 최적의 행동이 ‘왼쪽 이동’이라면 훈련 샘플은 대부분 왼쪽 이동과 관련된 샘플로 구성될 것이다. 이후 최적의 행동이 ‘오른쪽 이동’으로 변경되면, 학습 데이터 분포도 급격히 변하게 된다. 이러한 현상은 원치 않는 피드백 루프(feedback loop)를 초래하여 파라미터가 나쁜 국소 최적점(local minimum)에 갇히거나 심한 경우 발산(divergence)할 수도 있다.
* Preprocessing and Model Architecture
* 프레임 전처리
* 원시 Atari 프레임: 210 × 160 픽셀 크기, 128색 팔레트를 사용 → 계산적으로 부담이 클 수 있음
* 원시 프레임은 먼저 RGB 표현을 그레이스케일(gray-scale)로 변환한 후, 110 × 84 크기로 다운샘플링(down-sampling)
* 최종 입력 표현은 게임 플레이 영역을 대략적으로 포함하는 84 × 84 크기의 이미지 영역을 크롭(cropping)
* 매개변수화
* Q-함수는 히스토리(history)-액션(action) 쌍을 받아 해당 Q-값을 스칼라 값으로 출력
* 일부 기존 연구에서는 히스토리와 액션을 신경망의 입력으로 사용하는 방식 적용 → 각 행동(action)의 Q-값을 계산하기 위해 개별적인 순전파(forward pass) 필요 → 행동의 수에 비례하여 연산 비용이 선형적으로 증가
* 우리는 각 가능한 행동(action)마다 개별적인 출력 뉴런(output unit)을 가지는 아키텍처를 사용 → 신경망의 입력으로 상태(state) 표현만 사용 → 출력층의 각 뉴런은 주어진 상태에서 특정 행동의 예측된 Q-값을 나타냄 → 한 번의 순전파만으로 주어진 상태에서 모든 가능한 행동에 대한 Q-값을 계산
* 신경망 아키텍처
* 신경망의 입력은 함수 ϕ 에 의해 생성된 84 × 84 × 4 크기의 이미지로 구성
* 첫 번째 은닉층:
* 입력 이미지에 대해 16개의 8 × 8 필터를 스트라이드(stride) 4로 합성곱(convolve)
* ReLU(Rectifier Nonlinearity) 활성화 함수 적용
* 두 번째 은닉층:
* 32개의 4 × 4 필터를 스트라이드 2로 합성곱
* ReLU 활성화 함수를 적용한다.
* 마지막 은닉층:
* 256개의 ReLU 유닛으로 구성된 완전연결층(fully-connected layer)
* 출력층:
* 완전연결 선형층(fully-connected linear layer)
* 각 유효한 행동(valid action)에 대해 하나의 출력을 생성
* 실험한 게임에서 유효한 행동의 개수는 4개에서 18개 사이
* Experiments Settings
* 보상 구조 변경
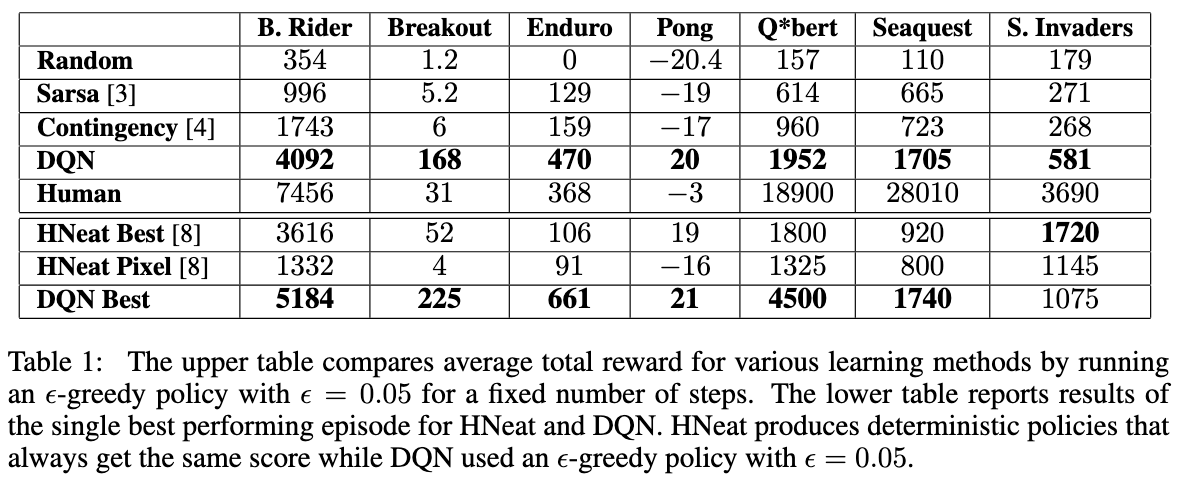
* 7개의 인기 있는 Atari 게임에서 실험: Beam Rider, Breakout, Enduro, Pong, Q*bert, Seaquest, Space Invaders
* 모든 7개 게임에서 동일한 네트워크 아키텍처, 학습 알고리즘 및 하이퍼파라미터 설정 사용
* 평가는 실제 원본 게임에서 수행 but 훈련 과정에서 보상 구조 일부 변경 (clipping)
→ 점수의 크기가 게임마다 크게 다르기 때문에, 오차의 크기를 제한하여 다양한 게임에서 동일한 학습률을 사용할 수 있도록 함
→ But, 보상의 크기를 구별할 수 없기 때문에 에이전트의 성능에 영향을 미칠 가능성 존재
* 모든 양의 보상 → +1로 고정
* 모든 음의 보상 → -1로 고정
* 보상이 없는 경우 → 변경 없이 유지
* 학습 설정
* RMSProp 알고리즘 사용
* 미니배치 크기: 32
* 탐색 정책:
* ϵ-탐욕적(ϵ-greedy) 전략 사용
* 초기 ϵ=1 → ϵ=0.1 (100만 프레임 동안 선형적으로 감소)
* 이후 ϵ=0.1 고정
* 총 학습 프레임 수 = 10M 프레임
* 재현 메모리 크기 = 최근 1M 프레임 저장
* 프레임 스킵 기법
* 프레임 스킵이란?
* 모든 프레임에서 행동 선택 X, k번째 프레임에서만 행동을 선택
* 스킵된 프레임 동안 마지막 행동을 반복
* 에이전트가 매 프레임마다 행동을 선택하는 것보다, 에뮬레이터를 한 스텝 앞으로 진행시키는 것이 연산적으로 훨씬 저렴
→ 이 기법을 적용하면 실행 시간(runtime)을 거의 증가시키지 않으면서, 에이전트가 약 k배 더 많은 게임을 플레이할 수 있음
* 설정값 (k값)
* 모든 게임에서 k = 4 사용
* 예외: Space Invaders에서는 k = 4를 사용할 경우 레이저가 깜빡이는 주기 때문에 보이지 않음
→ Space Invaders에서만 k = 3 사용
* Reward
* 평균 총 보상(Average Total Reward) 지표는 매우 노이즈가 심해, 안정성 ↓
* 보다 안정적인 성능 평가를 위해, 예측된 Q-값(Average Predicted Q)을 추적하는 방법을 제안
1. 훈련 시작 전, 랜덤 정책(Random Policy)으로 고정된 상태 집합(Fixed State Set) 수집
2.이 상태에서 최대 예측 Q-값(max predicted Q)을 계산
3. 훈련이 진행됨에 따라 이 Q-값의 평균을 추적
* DQN은 이론적 수렴 보장이 없지만, 실제 실험에서는 발산 없이 안정적으로 학습됨을 확인
* Evaluation
'Miscellaneous' 카테고리의 다른 글
| [2025-1] 윤선우 - 밑바닥부터 시작하는 딥러닝 리뷰, (CH 3.5) 출력층 설계하기 (0) | 2025.03.05 |
|---|---|
| [2025-1] 윤선우 - 밑바닥부터 시작하는 딥러닝 리뷰, (CH 2.1, 2.2) 퍼셉트론과 단순한 논리 회로 (0) | 2025.03.04 |
| [2025-1] 이재호 - Deep Reinforcement Learning with Double Q-learning (0) | 2025.02.28 |
| [2025-1] 장인영 - 밑바닥부터 시작하는 딥러닝 리뷰, (CH 2.4) 퍼셉트론의 한계 (1) | 2025.02.26 |
| [2025-1] 박경태 - 밑바닥부터 시작하는 딥러닝 리뷰, (CH 2.5)다층 퍼셉트론과 XOR 문제 (1) | 2025.02.25 |



