
https://arxiv.org/abs/1509.06461
Hado van Hasselt, Arthur Guez, David Silver - Google DeepMind
Deep Reinforcement Learning with Double Q-learning
The popular Q-learning algorithm is known to overestimate action values under certain conditions. It was not previously known whether, in practice, such overestimations are common, whether they harm performance, and whether they can generally be prevented.
arxiv.org
<Abstract>
- Q-learning 알고리즘이 action value를 과대평가(overestimation) 하는 것은 이미 알려져 있었지만 이러한 과대평가가 얼마나 자주 일어나는지, 성능에 얼마나 영향을 미치는지, 예방될 수 있는지에 대한 답은 없었음.
- DQN 알고리즘의 overestimation을 제시.
- Double Q-learning 알고리즘을 제시하고 이것이 large-scale function approximation으로 scaling 되는 것을 보여줌.
- Double Q-learning이 overestimation을 줄이는 것뿐만 아니라 Atari game에서 더 좋은 성능을 보임.
<Background>
1. Reinforcement learning



2. Deep Q-networks

- Action Value function으로 multi-layered neural network를 사용
- Replay buffer을 사용해 online Q-learning의 correlated samples 문제 해결
- Target network를 고정시켜(${\theta}^{-}_t$) moving target 문제 해결
- Exploration을 위해 $\epsilon$의 확률로 random action 선택
<Double Q-learning>
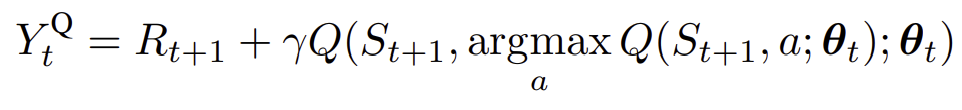
- DQN에서의 target 값을 위처럼 action을 선택하고 평가하는 두 스텝으로 나눌 수 있음.
- Action을 선택하고 평가하는 Q function이 동일 -> overestimation이 발생할 확률이 더 높음.
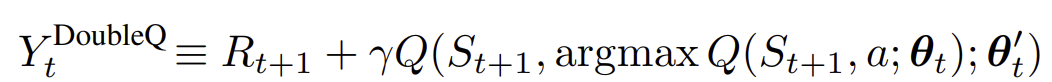
- Action을 선택하는 Q function(${\theta}_t$)과 평가하는 Q function($ {\theta}^{'}_t $)를 나누어 target 값을 정의.
- 하나의 데이터(experience)를 이용하여 두 네트워크 중 하나를 랜덤으로 업데이트 함.
<Overoptimism due to estimation errors>

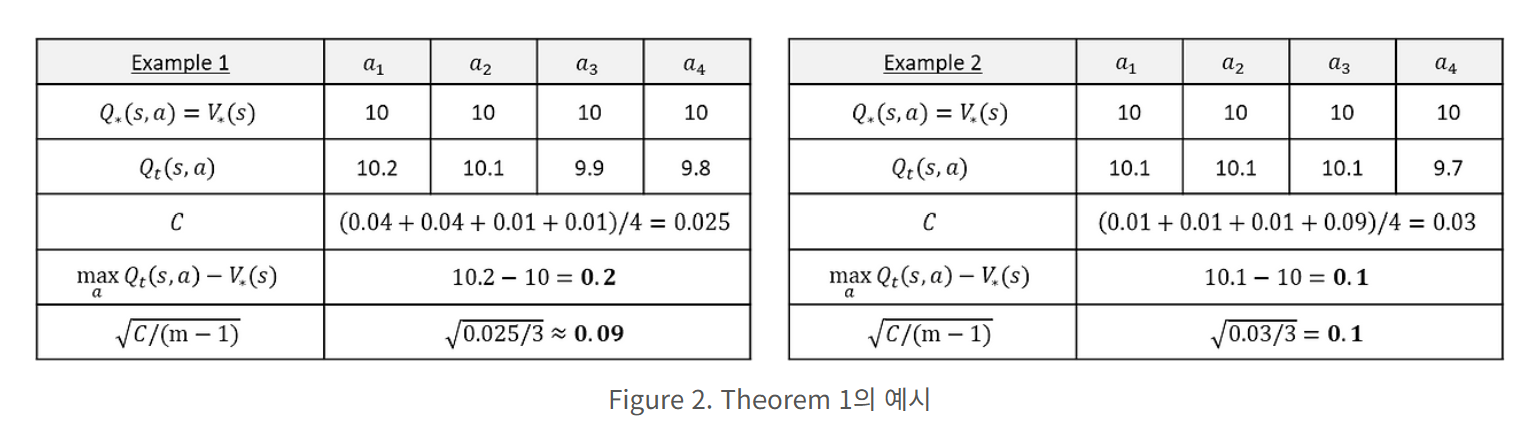
- 위 theorem을 통해 어떤 종류의 estimation error는 upward bias를 일으킴을 증명.
<Function approximation 상황에서의 overestimation 분석>

- 좌측 열 (Left Column):
- 보라색 선은 실제 최적 액션 값(Q∗(s,a)Q_*(s, a))을 나타냄.
- 초록색 선은 학습된 Q-값(Qt(s,a)Q_t(s, a))을 나타내며, 초록색 점은 샘플링된 상태에서의 참값을 의미.
- 상단과 중간 행에서는 학습된 함수가 유연성이 부족하여 일부 샘플링된 점도 제대로 맞추지 못함.
- 하단 행에서는 더 유연한 함수가 사용되었으나, 보지 않은 상태(state)에서 과대추정(overestimation)이 더 크게 발생.
- 중앙 열 (Middle Column):
- 10개의 액션에 대한 Q-값을 초록색 선으로 표현.
- 검은색 점선은 최대 Q-값을 나타내며, 실제 참값보다 더 높은 경향을 보임 → 과대추정(overestimation) 발생.
- 우측 열 (Right Column):
- 주황색 선은 단순한 Q-learning에서 발생하는 과대추정을 나타냄.
- 파란색 선은 Double Q-learning을 적용한 결과로, 전반적으로 과대추정이 줄어든 것을 보여줌.
- 평균 에러(오른쪽 상단 숫자)를 보면 Double Q-learning이 과대추정을 상당히 줄이는 것을 확인 가능.
결론
- 학습된 Q-값이 실제 참값보다 높게 추정되는 **과대추정 문제(overestimation bias)**가 발생.
- Double Q-learning을 사용하면 이 문제를 완화할 수 있음.
- 함수가 너무 유연하면 샘플링되지 않은 상태에서 높은 오차를 보일 수 있음.
<Double DQN>

- Double Q-learning을 DQN에 적용
- Action selection과 Action evaluation을 완벽히 나누지는 않았지만 DQN의 target network가 자연스럽게 evaluation network로 사용
<Experiments>
- DQN의 overestimation을 분석하고 Double DQN이 DQN보다 value accuracy, policy quality 두 가지 측면에서 우수함을 보임.
- Double DQN의 robust 함을 보기 위해 expert human trajectories에서 얻은 random start로 실험을 진행.
- 실험은 DQN에서와 거의 동일하게 진행되었으며 Q function은 3개의 convolution layer와 fully-connected hidden layer로 구성.(대략 1.5M parameters)
# Results on overoptimism

- DQN의 학습 곡선: 실제 최적 정책의 할인된 누적 보상 값(True value)보다 높게 예측하는 경향이 있음.
- Double DQN의 학습 곡선: 실제 정책의 true value에 더 가까운 예측을 수행함.
- 결과 해석: Double DQN은 단순히 Q-value 예측을 정확하게 할 뿐만 아니라, 더 나은 정책을 학습함.
- DQN의 불안정성: Asterix, Wizard of Wor와 같은 게임에서 매우 불안정한 학습 과정을 보임.
- 결과 분석: DQN이 Q-value를 과대평가할수록, 실제 게임 성능(Score)도 낮아짐.
- Double DQN의 안정성: 같은 환경에서 훨씬 더 안정적인 학습을 보여줌.
# Quality of the learned policies
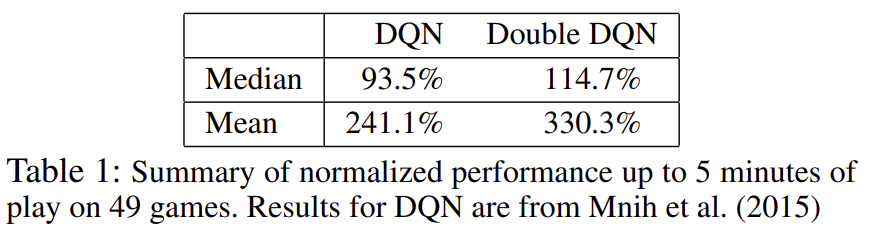
- DQN vs. Double DQN 성능 비교: Double DQN이 49개 게임에서 DQN보다 더 높은 평균 및 중간 점수를 기록.
- 특정 게임에서 큰 개선:
- Road Runner (233% → 617%)
- Asterix (70% → 180%)
- Zaxxon (54% → 111%)
- Double Dunk (17% → 397%)
- 결론: Double DQN은 DQN의 overestimation 문제를 해결하면서도 학습된 정책의 품질을 크게 개선함.
# Robustness to Human starts

- 기존 문제: 게임이 하나의 고정된 시작점에서만 시작되면, 에이전트는 특정 액션 시퀀스를 기억하는 방식으로 학습할 위험이 있음 → 일반화 능력 부족
- 해결책: 인간 전문가의 플레이 데이터를 활용하여 다양한 시작점을 설정한 후 성능을 측정
- 결과: Double DQN이 더 일반화된 해결책을 학습하여, 환경의 결정론적 특성에 덜 의존함.
<Discussion>
- Q-learning이 큰 규모 문제에서 과도한 낙관적 예측(overoptimism)을 보일 수 있으며, 이는 학습 과정의 내재적인 추정 오류(inherent estimation errors) 때문임을 보였다.
- Atari 게임에서의 Q-value 분석을 통해 이러한 과대평가가 이전 연구에서 생각했던 것보다 훨씬 더 일반적이며 심각함을 입증하였다.
- Double Q-learning을 확장 가능하도록 적용하면 과대평가 문제를 해결하고 더 안정적이고 신뢰할 수 있는 학습이 가능함을 보였다.
- DQN의 기존 신경망 구조를 유지하면서도 추가적인 네트워크나 매개변수를 필요로 하지 않는 Double DQN 기법을 제안하였다.
- Double DQN이 더 나은 정책을 학습하여, Atari 2600 도메인에서 최신(state-of-the-art) 성능을 달성하였음을 입증하였다.
참고 블로그



