
Intro
기존에 LLM모델들을 학습시킬 떄 pretrained된 모델들이 있고 이를 SFT후에 RL finetuning시키는 많은 연구들이 진행되었다. 하지만 이러한 방법은 시간이 오래걸리고 cost가 많이 든다. 최근에는 Supervised data없이 진행되는 많은 연구들이 있는데 아직까지는 O1의 추론 능력만큼 따라잡은 연구는 존재하지 않는다. 이 논문에서는 간단한 RL적용만하여 O1의 추론능력과 거의 유사한 DeepSeek-R1-Zero를 만들었다. 하지만 DeepSeek-R1-Zero는 읽기가 힘들거나 여러 언어들로 출력이 되기도 하는 문제가 생긴다. 이를 해결하기 위해 소량의 cold start data로 사용하여 fine tuning시키고 multi-stage training을 통해 이러한 문제를 해결한 DeepSeek-R1을 만들었다. 또한 distillation기법을 통해 R1을 Qwen과 같은 작은 LLM에도 적용하였더니 추론 능력이 월등히 증가하는 것 또한 확인하였다.
DeepSeek-R1-zero
논문에 따르면 supervised data없이 오직 RL방법을 사용하여 O1의 추론능력을 따라잡았다고 하였다. 이때 복잡한 강화학습 방법이 아닌 PPO에 확장판인 GRPO를 사용하였다고 한다.
PPO를 적용할 경우에는 gpu cost가 많이 들기 때문에 group으로 묶어서 ppo를 적용 이를 식으로 나타내면 다음과 같다.
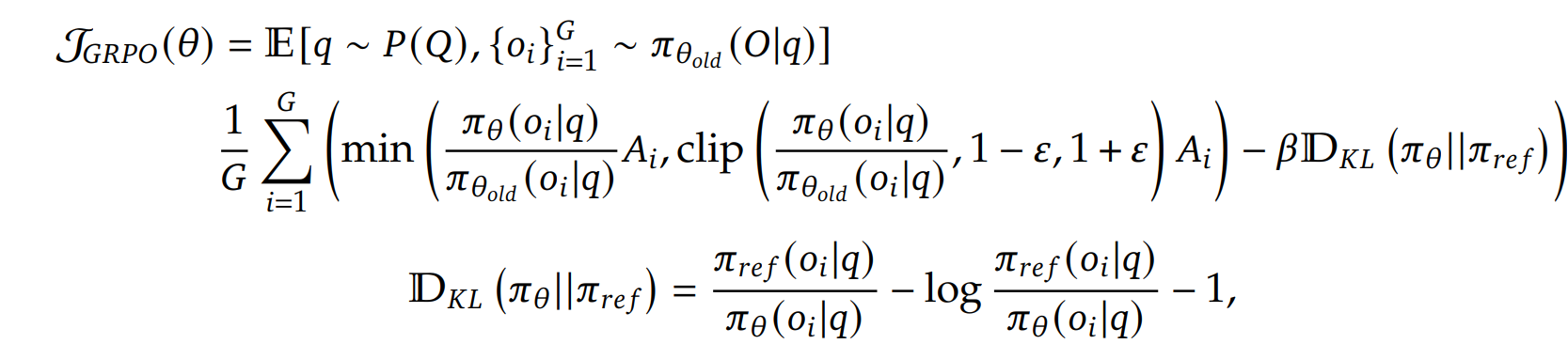
여기서 advantage는 GAE를 사용하지 않고 다음 식을 사용하였다.
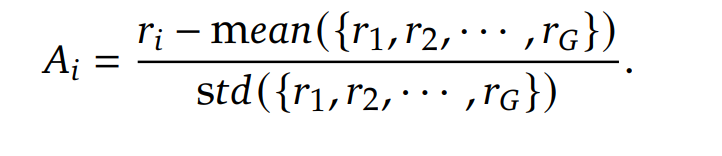
Reward에 경우 두 가지의 리워드를 주게 되었는데 첫번째로 정답이 있는 데이터에 경우에 정답을 말한경우 큰 reward를 틀린 경우에는 작은 reward를 주어서 점점 정답에 근접하도록 한다.
또한 모델이 답을 내기전에 무조건적으로 추론을 시키기 위해서 <think> format을 사용하도록 강제하였다.
이렇게 SFT없이 간단한 RL을 적용하였더니 AIME와 같은 수학 벤치마크에서 엄청난 상승이 있었다.

신기한점은 RL과정을 진행하면할수록 모델이 스스로 더 개선하는 self-evolution효과도 있다고 한다.

또한 AHA 모먼트라고 해서 모델이 추론을 하고 다시 검증하는 과정을 거치는 추론까지 진행한다고 한다.
R1-Zero모델은 추론능력은 뛰어나지만 좀 더 strong generalization을 가지기 위해서 R1 model을 만든다고 한다.
DeepSeek-R1
R1-zero보다 더 좋은 성능을 보이기 위해서 다음 4가지의 테크닉을 사용하였다.
cold start
기본이 되는 DeepSeek-V3 model을 RL로 훈련시키기 전에 소량의 cold data를 이용하여 fine tuning시키게 된다. 이렇게 되면 원래 zero보다 더 좋은 가독성을 가지게 되고 더 좋은 성능을 가지게 된다고 한다.
cold start가 끝난 후에는 R1-zero를 학습했던 거처럼 RL학습을 진행하게 되는데 언어 일관성 보상을 주게 되어 답변을 언어가 혼합된 형태로 주지 않도록 하였다. 근데 이렇게 했을때 약간의 성능저하가 발견되었다.
Supervised tuning and Rejection Sampling
RL학습 이후에 딥시크가 다양한 답변을 내놓게 하고 그 중 올바른 답변들만 선별하는 rejection sampling을 통해서 데이터를 수집 그 후 딥시크가 추론능력외에도 작문과 같은 능력함양을 위한 데이터셋을 합쳐서 총 80만개의 데이터셋을 만들어서 SFT를 시킨다.
Reinforcement Learning for All Scenarios
이제 그 후에는 전체적인 성능 향상을 위해서 강화학습을 도입하여 Helpful 한 응답과 Harmless(해롭지 않은) 응답을 중점적으로 개선하는 것을 목표로 한다.
Qwen 모델과 Llama 모델에 §2.3.3에서 정리한 800k개의 추론 데이터를 사용해 미세 조정을 진행하였더니 RL방법을 쓰지 않아도 추론 능력이 비약적으로 상승함.
결론적으로 R1의 성능은 다음과 같이 나온다.

O1과 비슷하거나 더 좋은 성능을 보인다.

증류만 시켜도 비약적 성능 향상을 보인다.

재밌는 점은 증류시킨게 RL적용한거보다 더 잘나온다.
다음 시리즈에서는 좀 더 딥하게 R1을 이해해보려고 한다.



