
원본 논문 링크 : https://arxiv.org/abs/2304.02643
Segment Anything
We introduce the Segment Anything (SA) project: a new task, model, and dataset for image segmentation. Using our efficient model in a data collection loop, we built the largest segmentation dataset to date (by far), with over 1 billion masks on 11M license
arxiv.org
https://github.com/facebookresearch/segment-anything
GitHub - facebookresearch/segment-anything: The repository provides code for running inference with the SegmentAnything Model (S
The repository provides code for running inference with the SegmentAnything Model (SAM), links for downloading the trained model checkpoints, and example notebooks that show how to use the model. -...
github.com
Abstract
1000만 개 이상의 이미지 및 10억 개 이상의 마스크를 가진 현존하는 가장 큰 segmentation 데이터셋(SA-1B)과 해당 데이터셋으로 학습해 인상적인 제로샷 성능을 보여주는 SAM(Segment Anything Model) 제안.
Introduction
웹 규모의 데이터셋에서 학습된 대규모 언어 모델은 강력한 일반화로 NLP를 혁신하고 있다.
본 논문의 목표는 segmentation에서 이러한 foundation model을 구축하는 것이다.

이를 위해 다음과 같은 질문들을 해결해야 한다.
- 제로샷 일반화를 가능하게 하는 작업은 무엇인가?
- 해당 모델의 아키텍처는?
- 어떤 데이터가 이 작업과 모델에 힘을 실어줄 수 있는가?
Segmentation을 위한 웹 규모의 데이터셋과 모델이 없기 때문에 효율적인 모델을 사용하여 데이터 수집을 지원하는 것과 새로 수집된 데이터를 사용하여 모델을 개선하는 것 사이를 반복하는 'data engine'을 구축한다.
Segment Anything Task
프롬프트 엔지니어링을 통해 다양한 다운스트림 작업을 해결하는 NLP에서 영감을 얻었다.
이 챕터에서는 적절한 프롬프트를 엔지니어링하여 광범위한 segmentation 다운스트림 작업에 적응할 수 있는 모델을 생성하는 작업을 정의하는 것을 목표로 한다.
Task
프롬프트의 아이디어를 segmentation으로 가져오는 것으로 시작.
Promptable segmentation task는 프롬프트가 주어지면 유효한 segmentation mask를 반환하는 것이다.

이것은 언어 모델과 비슷하며, 이러한 작업이 다운스트림 작업으로의 제로샷 전송을 위한 일반화로 이어지기 때문에 선택하였다.

▲NLP에서 사용 예시



Pre-training
일련의 프롬프트를 시뮬레이션하고 ground truth(GT)와 비교함.
목표는 프롬프트가 모호한 경우에도 모든 프롬프트에 대해 항상 유효한 마스크를 예측하는 것.
Discussion
Prompting 및 composition은 다양한 확산 모델에서 사용되는 CLIP과 같이 단일 모델을 확장 가능한 방식으로 사용하여 잠재적으로 모델 설계 시 알려지지 않은 작업을 수행할 수 있도록 하는 강력한 도구이다.
연구진은 프롬프트 엔지니어링과 같은 기술로 구동되는 composable system이 다양한 응용 프로그램을 가능하게 할 것으로 예상했다.
Segment Anything Model
SAM은 이미지 인코더, 프롬프트 인코더, 마스크 디코더로 구성되어 있음.

Image encoder
MAE로 사전 학습된 ViT
Prompt encoder
Sparse(points, boxes, text), dense(mask) prompt 고려.
Sparse prompt의 경우 위치 인코딩과 텍스트 인코더(CLIP)를 통한 free-form text로 나타내고
dense prompt의 경우 컨볼루션을 통해 각 이미지 임베딩에 합산됨.
Mask decoder
마스크 디코더는 DETR과 비슷한 구조.
참고-DETR : https://wikidocs.net/145910

SAM Decoder
Output token은 DETR에서의 object query와 같은 역할.
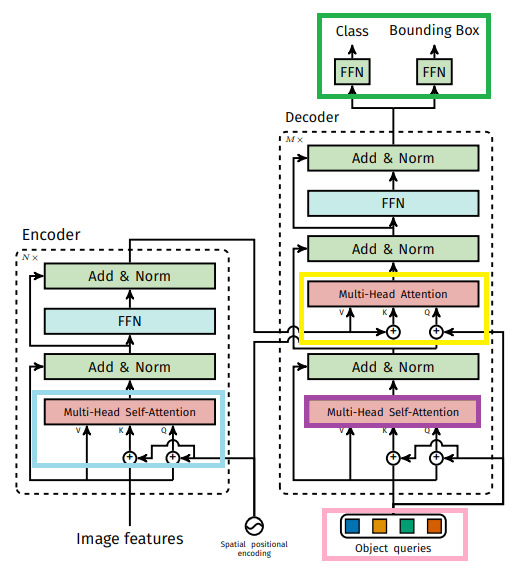
DETR
Resolving ambiguity
모호한 프롬프트에 대해 여러 개의 유효 마스크를 출력하도록 하고(3개), 마스크의 순위를 매기고, 가장 정확한 마스크에 대한 손실만을 역전파한다.

Losses and training
DETR에서 사용된 focal loss와 dice loss 사용.
SAM이 데이터 엔진에 원활하게 통합될 수 있도록 RITM과 같이 마스크 당 11라운드 동안 프롬프트를 무작위로 샘플링하여 interactive setup을 시뮬레이션함.
Segment Anything Data Engine
SA-1B 데이터셋을 수집하기 위한 데이터 엔진 구축
- 모델 지원 수동 주석 단계
- 자동 예측 마스크와 모델 지원 주석이 혼합된 반자동 단계
- 완전 자동 단계
로 구성.
Assisted-manual stage
전문 주석 팀이 직접 SAM이 제공하는 대화형 segmentation 도구를 사용하여 label 지정. Label의 이름이나 설명은 수집 X.
SAM은 공개된 segmentation 데이터셋으로 학습한 뒤 새로 주석이 달린 마스크만으로 재학습됨.
더 많은 마스크가 수집됨에 따라 모델을 확장하고 주석 시간, 마스크 검출률, 디테일이 개선됨.
~ 120k 이미지, 430만 개의 마스크까지
Semi-automatic stage
모델이 먼저 마스크를 자동으로 감지한 후 모델이 감지하지 못한 눈에 잘 띄지 않는 개체를 주석자가 주석을 달도록 함.
마찬가지로 주기적으로 모델을 재교육했으며, 마스크를 더 많이 검출했지만 시간은 다시 늘어남.
~ 300k, 1020만 개까지
Fully automatic stage
충분한 마스크 수집과 모호성 개선, 임계값을 넘는 안정적인 마스크만 선택하고 중복을 제거하는 등의 필터링으로 완전 자동으로 마스크 수집하여 11억 개의 고품질 마스크가 있는 SA-1B 데이터셋 완성.
Segment Anything Dataset
개체 중심의 공간 분포

😲(Meta에서 SA-1B 데이터셋을 직접 만들었다) ->다운 https://ai.meta.com/datasets/segment-anything/
이미지 당 마스크 개수가 압도적으로 많고(왼쪽), 따라서 평균 마스크 크기가 작음(중간).

Zero-Shot Transfer Experiments




그리고 아래는 SAM을 직접 사용해본 후기입니다.
https://blog.naver.com/kgh9080/223387710324
SAM(Segment Anything Model) 알아보기
오늘은 SAM 에 대해서 알아보겠습니다. 1. Meta 에서 발표한 SAM https://segment-anything.com/ ▲...
blog.naver.com



