
https://arxiv.org/pdf/2212.08013
https://github.com/google-research/big_vision
GitHub - google-research/big_vision: Official codebase used to develop Vision Transformer, SigLIP, MLP-Mixer, LiT and more.
Official codebase used to develop Vision Transformer, SigLIP, MLP-Mixer, LiT and more. - google-research/big_vision
github.com
Abstract
- ViT의 patch size는 speed와 accuracy를 결정하는 인자이지만, patch size를 변경하는 것은 model retraining을 요구
- Training 과정에서 patch size를 ramdomization시켜 single weights set을 얻고, computation에 맞춰 적절한 model 맞춤화
- FlexiViT는 다양한 Vision task에서 standard ViT model과 동일하거나 우수한 성능
→ ViT backbone model에 computed-adaptive 기능을 추가한 격
1. Introduction
- ViT (Vision Transformers) : Patchfication - 이미지를 겹치지 않는 patch로 나눈 후 token화시키는 전략
- Patch size는 parametrization없이 compute (speed)와 predictive performance (accuracy)를 결정하는 효과적인 요소이지만, standard ViT model은 patch size를 변경할 경우 retraining해야 한다는 문제점
- FlexiViT : 추가 비용 없이 다양한 범위의 patch size를 사용하는 flexible ViT
- Standard fixed-patch ViT와 동일하거나 우수한 성능
- Patch size를 randomization하고, positional & patch embedding을 각 patch size에 맞게 조정
- 추가로 최적화된 Resizing operaion과 Knowledge distillation에 기반한 training 절차까지 제안

- 다양한 downstream task에서 효율성을 확인하고 기존 ViT 기반 모델의 Training 설정을 바꾸기 위한 일반적 방법 제시
- Fine tuning 후에도 성능을 유지할 수 있는 backbone flexibility 확인
→ Resource-efficient 전이학습 수행 : 큰 patch 크기로 fine-tuning 후 작은 patch 크기로 sampling하여 성능을 높임 - Pre-training 속도 향상에 이용 : 모든 patch size mode에 대해 비슷한 표현을 가짐
- Model representation 분석 결과 다양한 patch size 간에 비슷한 양상 발견
- 다른 구조적 방법과 비교했을 때 FlexiViT가 뛰어난 성능
2. Related work
- Patchification을 조정 : Token 제거 (random, structed, less important), Token을 이용해 transformer cascade 훈련
↔ FlexiViT는 모든 token을 유지하여 정보 손실 없이 이미지 구현 - Input resolution 변경 : speed 향상 혹은 data augmentation 목적
↔ FlexiViT는 data augmentation에 대해서는 다루지 않음, 여러 patch size에서 잘 작동하는 model을 만드는 데 집중 - Neural Architecture Search 분야 : supernet 1개를 훈련시켜 다양한 형태의 subnets를 추출, 복잡한 구조적 변경을 요구하는 단점
- SuperViT : 다양한 scale에서 patch를 추출한 후 token을 제거하면서 sequence length를 조절.
↔ FlexiViT는 patch size에만 집중 : pre-trained ViT model을 그대로 활용, 미래 ViT 발전, 기존 pipeline에 쉽게 통합 - Matryoshka representation learning : output vector가 의미있는 sub-vector를 포함, FlexiViT의 보완적 접근
3. Making ViT flexible
3.1 Background and notation
Input $x\in \mathbb{R} ^{h \times w \times c}$에 대해 $x_i \in \mathbb {R} ^{p \times p \times c}$ patch로 나눔.
$s = [h/p] \cdot [w/p]$ 개의 sequence를 tokenization, $s$는 compute 양을 나타내는 지표 (Patchification)
각 $x_i$에 대해 embedding $e_{i}^{k} = \left< x_i, \omega_k \right>$를 구하고, learned positional embedding $\pi_i$를 더하여 token $t_i = e_i + \pi_i$를 산출, transformer encoder에 대입
Patch size $p$는 sequence size $s$를 결정 : $p$가 작아지면 $s$가 길어져 느리고 표현이 풍부한 model이 만들어지며, 이에 의존하는 인자는 $\omega_k$와 $\pi$뿐
$\textrm {ViT-}\mathcal{S} \textrm {/} p$ : $\mathcal {S} \in \left\{ \textrm{S, M, B, L, ...} \right\}$은 model scale, $p$는 patch size
3.2 Standard ViTs are not flexible
Standard pre-trained ViT를 다른 patch size에 적용할 경우 성능이 저하됨
단순히 $\omega$와 $\pi$를 bilinear interpolation으로 resize할 경우 학습 시 사용된 patch 크기에서 멀어질수록 낮은 preformance를 보임
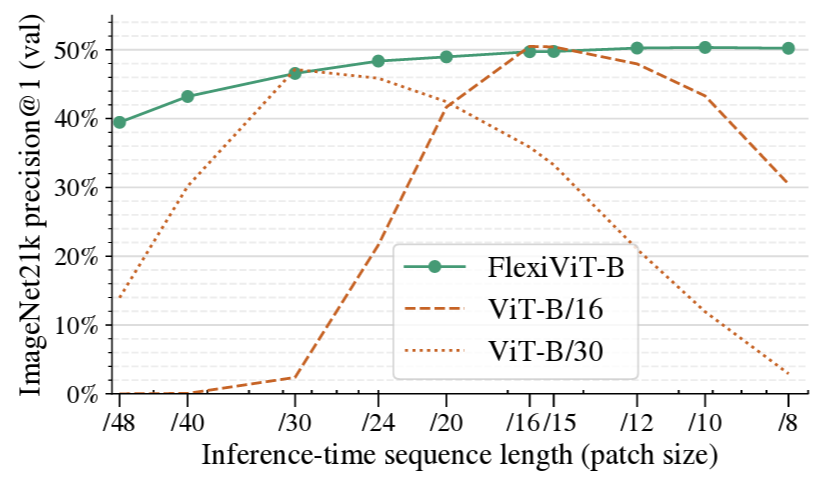
3.3 Training flexible ViTs
ViT-B/16 및 ViT-B/30에 비해 FlexiViT-B의 우수한 성능 : Trained patch에서 동일한 성능 + 다른 patch size에서 성능 우수
→ Training 단계마다 random하게 patch size를 선택했다는 점에서 차이
- 기본 parameter shape 정의 : $\omega$와 $\pi$에 대해 기본적인 shape를 결정하고, forward pass 중 resize되어 training에 적용, $\omega$는 $32 \times 32$, $\pi$는 $7 \times 7$ 크기로 결정했으며, 기본 parameter shape이 최종 결과에는 영향 X
- Image resolution $240 \times 240$ 사용 : 나누어떨어지는 다양한 패치 크기 사용 가능, 각 iteration마다 $p$를 random sampling

Patch size 변경은 Image size와 관련되어 있으나, 동일하진 않음 : 전자는 model과, 후자는 information 접근성과 관련
ViT를 유연화하는 방법이 추가로 2개가 있으나 (Section 7), patch size 조정 방식이 가장 효과적
3.4 How to resize patch embeddings
Patch $x$, weight $\omega$에 대해 bilinear interpolation resize 시 token의 크기가 달라짐
→ ViT의 경직성, 혹은 FlexiViT 학습을 방해하는 inductive bias로 볼 수 있음 (resize 후에도 embedding $e_i = \left< x, \omega \right>$이 달라져서는 안 됨)
Embedding 후 token normalization하거나 LayerNorm module을 사용해야 함. 하지만 model 구조 변경이 필요하며 pre-trained ViT와 호환되지 않는데다, patch embedding을 온전히 보존 불가
Interpolation 연산을 linear transformation으로 정의
Patch embedding weight $\hat{\omega} = P \omega$로 정의 : Resized patch token을 원래 patch token과 일치시키기 위함
→ PI-resize : bilinear interpolation의 inverse transformation을 수행하는 matrix




PI-resize의 효과 검증 및 대체 휴리스틱과 비교 목적
ViT-B/8 model을 로드하고 각 이미지와 모델을 resized하여 $s=784$를 유지
Upsampling 시 일정 성능 유지, Downsampling 시 점진적으로 성능 감소
다른 기법과 비교했을 때 PI-resize가 가장 잘 작동

3.5 Connection to knowledge distillation
Knowledge distillation : student model을 teacher model을 모방하도록 설계, 하지만 최적화 문제에서 어려움
FlexiViT 사용 시 ViT teacher의 가중치로 student FlexiViT를 초기화하고 distillation 성능을 향상 가능
ex) ViT-B/8 model로부터 patch embedding을 $32 \times 32$로 PI-resize 조정, position embedding을 $7 \times 7$으로 bilinear resampling
이후 training에서 FunMatch 방식으로 distillation, KL-divergence 최소화

Teacher model을 이용한 Distillation 초기화를 random 초기화, 레이블을 사용한 supervised 학습과 비교
고유한 초기화 능력의 이점 : 추가 epoch 수행 시 작은 patch에서 일치된 효과, 큰 patch에서 성능 향상

3.6 FlexiViT's internal representation
패치 크기가 다른 입력을 처리하는 각 방식을 알아보기 위해, 신경망 사이 표현을 비교하는 데 사용하는 CKA 적용
내부 표현은 그리드 크기에 따라 다르지만 출력 표현은 일반적으로 정렬됨

4. Using pre-trained FlexiViTs
Pre-trained ViT가 다른 task로 전이학습 시에도 성능을 유지하는지 확인
: Classification, Locked-image Tuning, Open-vocabulary detection, Panoptic segmentation, Semantic segmentation
4.1 Results

고정된 ViT-B/30, ViT-B/16와 비교하였을 때, FlexiViT-B는 본질적인 단점이 없음.
4.2 Resource-efficient transfer via flexibility
전이학습을 resourse-efficient하게 수행할 수 있는 새로운 방법 제시
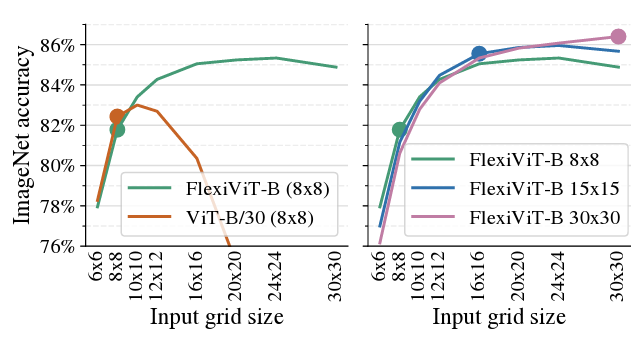
고정된 patch size에서 전이학습 이후에도 model flexibility가 유지되므로, 큰 patch에서 high speed로 training한 후, Deploy 과정을 작은 patch에서 수행하여 높은 성능의 이미지 추출
ViT-B/30과 비교했을 때, pretrained FlexiViT는 고정된 patch size에서 전이 학습을 수행하여도 작은 patch size에서 좋은 성능을 보임
5. Flexifying existing training setups
기존 pre-trained model을 전이 학습 후 유연하게 만드는 학습 설정에 대한 설명
5.1 Transfer learning
Section 4와 동일한 전이 학습 수행, 이번에는 전이 학습 중에도 randomized patch size 사용
Flexible transfer, Fixed model을 전이학습 중 유연하게 만든 경우조차 좋은 성능을 보임

5.2 Multimodal image-text training
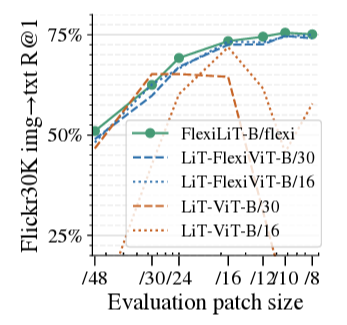
Multimodal training을 FlexiLiT (다양한 visual patch 크기에서도 잘 작동하는 text embedding 생성), FlexiCLIP(image-text pair를 처음부터 훈련) 2가지 방식으로 유연화
FlexiLiT-B/flexi 모델이 가장 좋은 성능을 보이며, 다른 sequence 길이에서 성능이 저하하는 LiT-ViT baseline과 달리 성능을 유지
5.3 Open-vocabulary detection

OWL-ViT의 학습 방식에서, 어떤 patch size에서도 ViT-B에 비해 동등하거나 더 나은 성능
Detection 단계보다 Inference 단계에서 patch size 조절 시 성능이 나아짐
5.4 Training times and flexification

고정된 ViT model의 학습도 FlexiViT 기법을 활용하여 효율적으로 진행
학습 단계마다 다른 patch size 분포를 사용하는 커리큘럼 → 같은 자원으로 더 나은 성능
6. Analyzing FlexiViTs
Attention relevance patterns across scales
Patch size를 줄이면 attention relevance가 이미지 전체에서 작고 세밀한 영역에 집

Relation of token representations across scales
Feature map 중심부 seed token (16)과 다른 patch size에서 token 표현 사이 코사인 유사도 측정, token 간 대응관계 존재 확인

Ensembling
여러 scale로 실행하여 ensemble 시 성능 확인, 동일한 연산량으로 하나의 FlexiViT를 실행하는 것이 항상 더 효율적
Shape or texture bias
형태 (Shape)과 질감 (Texture) 중 어느 쪽을 선호하는지에 대한 bias가 있으며, 이는 patch size에 의존함.
동일한 Patch size로 평가된 일반 ViT와 유사한 bias를 보임
Model and dataset size

Model scale 변화에 따라 모든 S, B, L model이 기존 모델을 능가
Patch size 조절보다 model scale을 조정하는 것이 더 효과적인 시점 발생
7. Discussion of alternatives
Patch size 조정 외에도 sequence length와 compute 균형을 조절하는 다른 방안 탐색

Varying patch embedding stride
Sampling stride 변경 : Overlapping patches하여 sequence 길이 증가, patch size 변화에 따른 조정 과정을 생략하며, 꽤 효과적인 성능을 보임
Varying model depth
Deep layer 수에 유연성 부여 (NLP 분야, ViT의 dept pruning) : 깊이에 따라 선형적으로 연산량이 증가하며, 전체 parameter의 일부분만 사용, 예측은 점진적으로 refine한다는 특징
공유된, 혹은 개별 head를 두는 방법으로 접근하였으나 FlexiViT보다 열등한 효율성
8. Conclusion
- FlexiViT는 단일 모델로 연산량과 성능 간의 균형을 효과적으로 조절하는 간단한 방법
- Pre-training cost 크게 절감, 다양한 Downstream task에서도 뛰어난 성능
- 향후 많은 확장 기대, Patchification의 활용을 탐색하는 연구자들에게 영감



