
논문 링크: 1612.04402
코드 링크: https://www.cs.cmu.edu/~peiyunh/tiny
Peiyun Hu, Deva Ramanan
Robotics Institute, Carnegie Mellon University
(arXiv:1612.04402v2, 2017년 4월 15일)
1. Introduction
small object detection는 풀리지 않은 중요한 문제이다.
본 논문은 small faces를 탐지하는 context에서 다음 세 가지 문제를 다룬다:
- Scale Invariance
- Image Resolution
- Contextual Reasoning
Scale Invariance 한계
대부분의 최신 object detection 시스템은 scale-invariant한 특성을 지향한다. 하지만 실제 환경에서는 센서의 해상도 한계 때문에 완전한 scale-invariance를 보장하기 어렵다. 예를 들어, 300px 크기의 얼굴을 인식할 때 필요한 단서와 3px 크기의 얼굴을 인식할 때 필요한 단서는 전혀 다르다. 이처럼, 객체의 크기에 따라 요구되는 정보의 본질이 달라지므로, 단순한 scale normalization만으로는 small object를 정확히 인식하기 어렵다.
Multi-task Modeling of Scales
기존 연구들은 일반적으로 고정된 크기의 canonical template으로 region을 resize하여, scale-normalized classifier를 학습하는 방식을 채택해 왔다. 하지만 하나의 template 크기로 모든 객체 scale을 다룰 수는 없다. 작은 template은 작은 얼굴을 잘 잡지만, 큰 template은 세밀한 facial feature를 더 잘 포착할 수 있기 때문이다.
이에 따라 본 논문은 scale과 aspect ratio에 따라 서로 다른 detector를 따로 학습하는 방식을 제안한다. 그러나 이 방식은 다음과 같은 한계를 갖는다:
- 각 scale에 대한 학습 데이터 부족
- 테스트 시 detector를 여러 번 실행해야 하므로 비효율적
이를 해결하기 위해, 본 논문은 deep feature hierarchy의 다양한 layer에서 feature를 추출하고, 이를 기반으로 한 multi-task detection 방식을 도입한다. 이렇게 하면 다양한 scale의 객체에 효과적으로 대응할 수 있으며, 특히 큰 객체에 대해서는 높은 정확도를 달성할 수 있다. 하지만 여전히 해상도가 낮은 작은 객체는 탐지가 어렵다는 문제가 남아 있다.
How to Generalize Pre-trained Networks?
대부분의 pre-trained deep networks는 ImageNet과 같은 데이터셋에 기반하여, 고정된 객체 크기(예: 224×224)에 최적화되어 있다. 따라서 다양한 크기의 객체에 대응하기 위해서는 이러한 한계를 극복할 수단이 필요하다.
본 논문은 test-time image resizing(interpolation 및 decimation)을 통해 이를 해결한다. 일반적으로 multi-resolution 처리를 위해 image pyramid를 활용하지만, 특히 pyramid의 가장 낮은 해상도 층을 upsample(interpolate) 하는 것이 작은 객체 탐지에 핵심적으로 중요함을 실험적으로 보여준다.
이러한 전략을 통해, 본 논문은 scale-specific detector를 scale-invariant하게 사용할 수 있도록 구성하였다. 즉, 다양한 해상도를 갖는 image pyramid를 기반으로 각 scale에 적절한 detector를 적용하여, 극단적인 scale variation도 다룰 수 있다.

- (a) 전통적인 단일 template + 촘촘한 pyramid
- (b) scale 별 개별 detector (하지만 extreme scale에는 약함)
- (c) coarse pyramid를 활용하여 extreme scale 대응
- (d) 고정 크기 receptive field로 context 통합
- (e) 다양한 layer의 feature를 사용하는 foveal descriptor 기반 template
이러한 접근을 조합(c, d, e)하여, 다양한 해상도와 객체 크기에 걸쳐 효과적인 탐지가 가능한 구조를 구현한다.
How Best to Encode Context?
작은 객체는 자체의 시각적 정보만으로는 탐지하기 어렵기 때문에, context 정보를 적극 활용해야 한다. 이를 검증하기 위해, 본 논문은 사람이 실제로 detector의 출력(정/오 탐지 얼굴)을 보고 분류하는 human study를 실시하였다.

- 큰 얼굴은 context 없이도 인식이 가능하지만,
- 작은 얼굴은 context 없이는 거의 인식이 불가능하였다.
또한 단순히 bounding box를 3배 키우는 proportional context는 큰 개선을 주지 못했다. 반면, 고정된 크기(300px)의 context window를 추가할 경우, 작은 얼굴의 탐지 오류가 20% 감소하였다. 이는 context가 scale-variant하게 설계되어야 함을 의미한다.
이러한 통찰을 바탕으로, 본 논문은 약 300x300 크기의 receptive field를 갖는 foveal templates를 제안한다. 이 template는 다양한 convolutional layer에서 추출한 feature를 통합한 것으로, 고해상도 디테일(하위 layer)과 저해상도 전역 정보(상위 layer)를 동시에 포함할 수 있다. 특히, 고해상도 feature는 정확한 위치 예측(localization)에 핵심적인 역할을 한다.
2. Related Work
Scale-invariance
기존의 object recognition pipeline 대부분은 scale-invariant한 표현 학습을 목표로 한다. 대표적으로 SIFT와 같은 전통적인 feature descriptor부터, 최근의 Faster R-CNN과 같은 detection 시스템은 ROI pooling 또는 image pyramid를 통해 scale-invariant한 feature를 추출한다.
그러나 일부 연구에서는 특정 scale에 맞춘 scale-variant template의 가능성을 탐색해 왔다. 예를 들어 pedestrian detection 분야에서는 탐지 속도를 높이기 위해 scale-specific detector가 사용된 바 있으며, SSD 또한 deep feature 기반으로 다양한 scale에서 작동하는 template을 사용하는 방법론이다.
본 논문에서는:
small object detection, 특히 작은 얼굴을 탐지할 때의 context 활용 방식과 scale-variant template의 적용 방식을 보다 정교하게 탐구한다.
Context
작은 객체를 탐지할 때는 해당 객체만의 시각적 정보(signal)가 부족하기 때문에, context가 핵심적인 역할을 한다는 사실은 여러 recognition task에서 입증되어 왔다.
- Spatial RNN(IRNN)을 활용하여 ROI 외부의 context를 모델링한 연구는 작은 객체에 대한 탐지 성능 향상을 보여주었다.
- Pedestrian detection에서는 ground plane 추정 정보를 context로 활용해 탐지 성능을 높인 바 있다.
- Face detection에서도 얼굴 주변의 body ROI까지 함께 pooling하여 detection 성능을 크게 개선한 사례가 있다.
본 논문에서는:
global context descriptor 대신, 객체 주변의 local context를 넓은 receptive field로 모델링하였다. 특히, 낮은 해상도의 얼굴일수록 context의 중요도가 훨씬 크다는 점을 실험적으로 증명하였다.
Multi-scale Representation
다양한 scale에서의 표현(multiscale representation)은 semantic segmentation과 object detection 모두에서 중요한 역할을 한다. 예를 들어:
- Hypercolumn feature를 활용한 연구들은 여러 convolution layer에서 추출한 feature를 결합함으로써, fine-to-coarse 정보를 통합할 수 있다는 점을 보여주었다.
- SSD, R-FCN 등의 detection 방법도 multiscale feature 사용을 통해 성능 향상을 달성하였다.
- 최근 face detection에서는 ROI feature를 여러 scale에서 pooling하여 정밀한 판단을 내리는 방식이 채택되기도 했다.
본 논문에서는:
hypercolumn 구조를 기반으로 한 foveal descriptor를 사용한다. 특히, 하위 convolution layer에서 추출한 fine-scale feature가 작은 객체의 정확한 위치를 결정하는 데 결정적인 기여를 한다는 점을 정량적으로 분석하였다.

RPN (Region Proposal Network)
제안된 모델은 표면적으로는 특정 클래스에 특화된 RPN과 유사해 보인다. 하지만 다음과 같은 구조적 차이점이 존재한다.
본 논문에서는:
- objectness proposal이 아닌, 특정 object class에 대해 학습된 detector를 사용한다.
- Foveal descriptor를 통해 여러 scale에서 feature를 결합하며,
- Cross-validation을 통해 객체의 크기와 aspect ratio에 최적인 detector를 선택하고,
- 극단적인 scale 처리를 위해 image pyramid를 적극 활용한다.
특히, interpolated image에 최적화된 scale-specific detector를 사용하는 접근은 small face 탐지 성능에 결정적인 영향을 준다. 만약 이러한 방식이 생략되면, 탐지 정확도가 10% 이상 감소하는 현상이 발생한다.

3. Exploring Context and Resolution
25x20 크기의 작은 얼굴을 가장 잘 찾는 방법은 무엇인가?
이 질문은 작은 객체 탐지에서 scale-invariant한 접근을 잠시 제쳐두고, 고정된 크기의 객체 탐지 문제로 단순화함으로써, context와 canonical template 크기가 탐지 성능에 어떤 영향을 주는지 분석하는 데 집중한다. 추가로, 비교 실험을 위해 큰 얼굴(250x200)에 대해서도 동일한 질문을 던진다.
Setup
- 탐지할 객체는 고정된 크기(예: 25x20)이며, scanning-window 방식의 detector를 fully convolutional network (FCN) 구조로 학습한다.
- 네트워크는 ResNet-50 기반이며, 다양한 해상도의 feature map (res2, res3, res4, res5)을 이용한다.
- 각 위치별로 binary heatmap을 예측하는 방식으로 detector를 구성한다.
3.1 Context
Receptive Field(RF) 크기를 조절하여 context 정보를 얼마나 포함할지 실험한다.
- 상위(deeper) 레이어일수록 RF가 커지고, 하위(초기) 레이어는 RF가 작지만 더 높은 해상도 정보를 보존한다.
- 작은 얼굴에 대해 context를 추가하면 성능이 크게 향상되며, 특히 객체 범위를 넘는 loose RF를 사용할 때 탐지 정확도가 증가한다.

Results:
- 작은 얼굴 탐지 정확도: +18.9% 향상
- 큰 얼굴 탐지 정확도: +1.5% 향상
- 너무 큰 context(> 300x300)는 오히려 overfitting을 유발할 수 있다.
- 작은 얼굴의 경우,하위 layer feature(res2, res3)에서 나오는 고해상도 local feature가 핵심적임을 발견하였다.
이 결과를 바탕으로, 모든 scale-specific detector에 대해 공통된 large receptive field(291x291)를 적용하는 multi-task 구조가 가능함을 시사한다.
→ context의 sclae-variant 접근의 중요성을 계속해서 언급하지만 실제 구현시에는 291x291로 고정
3.2 Resolution
template 크기와 실제 객체 크기를 다르게 설정하면 어떤 일이 벌어지는지를 실험한다. 예를 들어:
- 작은 얼굴(25x20)을 탐지할 때,
- 해당 크기에 맞춘 template을 쓰는 대신,
- 2배 큰 template(50x40)을 학습한 후, 입력 이미지를 2배로 upsample하여 적용하면 성능이 더 좋아진다.
→ 정확도 69% → 75% (+6%)
- 큰 얼굴(250x200)을 탐지할 때도,
- 2배 작은 template(125x100)을 사용하고 입력 이미지를 downsample하면 성능이 증가한다.
→ 정확도 89% → 94% (+5%)
- 2배 작은 template(125x100)을 사용하고 입력 이미지를 downsample하면 성능이 증가한다.
이유:
- WIDER FACE와 같은 real-world 데이터셋에서는 작은 객체가 큰 객체보다 수적으로 훨씬 많다.

작은 객체는 하나의 이미지에 많이 labeling될 수 있다. - 그러나 이는 단지 데이터 수 때문이 아니라, pre-trained network의 최적화 범위 때문이기도 하다.

ImageNet 기준으로, 객체 크기가 40~140px 사이에 대부분 분포하며, 해당 범위에서 pre-trained 모델이 가장 잘 동작함을 확인했다.
따라서 작은 얼굴 탐지를 위해서는 실제 크기에 맞는 template보다 2배 큰 해상도에서 template을 적용하는 것이 더 효과적이며, 큰 얼굴의 경우는 반대로 해상도를 낮춰서 중간 크기 template을 사용하는 것이 효율적이다.
즉,
- Context: 작은 객체일수록 더 넓은 context가 필요하며, 300x300 정도의 receptive field가 효과적이다.
- Resolution: pre-trained 모델의 성능은 특정 scale 범위(40~140px)에 최적화되어 있으며, 이를 벗어나는 객체는 입력 해상도 조절을 통해 해당 범위로 맞춰야 성능이 극대화된다.
- 탐지 전략: 각 scale에 맞는 template을 직접 훈련하기보다는, 적절한 해상도로 이미지를 변환하고, medium-scale에 맞춘 template을 사용하는 방식이 더 효율적이다.
4. Approach: Scale-specific Detection
효율적이고 강력한 scale-specific detector를 실제로 어떻게 구성할 것인가?
- $t(h, w, \sigma)$ :
- 크기 $(h/\sigma, w/\sigma)$의 객체를 해상도 $\sigma$에서 탐지하도록 학습된 template

- t(250, 200, 1): 해상도 1x에서 250x200 크기 탐지
- t(125, 100, 0.5): 해상도 0.5x에서 250x200 크기를 간접적으로 탐지
최적 template Resolution 선택 전략
각 target object size $s_i = (h_i, w_i)$에 대해, 어떤 resolution $\sigma_i$가 $t(h_i, w_i, \sigma_i)$의 성능을 최대화 시키는가?
- 여러 fixed resolution set에 대해 multi-task model을 각각 학습한다.
- object size별로 가장 좋은 resolution을 선택한다.
- 이 방식은 brute force + greedy optimization에 가깝지만, 다양한 크기의 객체에 대해 일반적인 전략을 도출할 수 있다.
실험을 통해 도출한 최적 해상도 선택 전략은 다음과 같다:
- 큰 객체 (높이 > 140px):
→ 0.5x 해상도에서 template을 학습 (즉, 입력 이미지를 downsample) - 작은 객체 (높이 < 40px):
→ 2x 해상도에서 template을 학습 (즉, 입력 이미지를 upsample) - 중간 크기 객체 (40~140px):
→ 1x 해상도에서 template을 그대로 사용
이 전략은 ImageNet의 객체 크기 분포와도 일치하는데, ImageNet의 대부분 객체가 40~140px 크기 내에 있기 때문이다.
Template Pruning: 중복 제거
앞선 방식으로 학습된 다양한 template 중 일부는 중복되거나 불필요할 수 있다. 예를 들어:
- t(62, 50, 2): 31x25 객체용
- t(64, 50, 1): 64x50 객체용
→ 이 두 template은 유사한 객체를 탐지하므로, 하나를 제거해도 성능 손실 없이 효율화 가능하다.
결과적으로 다음과 같은 두 그룹만 남기는 것으로 간결한 모델 구성이 가능하다:
- A-type: 40~140px 높이의 얼굴을 위한 template → coarse image pyramid에서 실행
- B-type: 20px 이하의 작은 얼굴을 위한 template → 2x upsample된 이미지에서만 실행
Canonical Bounding Box Shapes
Training dataset에 포함된 이미지의 bounding box 정보를 분석하여, 객체의 크기와 비율이 다양한 bounding box들을 유사한 형태끼리 그룹화한다. 이 과정을 통해 bounding box shape space를 요약할 수 있는 대표적인 크기들, 즉 canonical bounding box shapes를 정의한다.
이러한 대표 크기들은 모델이 모든 객체 크기를 일일이 학습하지 않아도 되도록 도와준다.
→ 효율적이고, 실제 분포를 반영한 anchor(template) 설계
클러스터링은 Jaccard distance를 사용하여 수행되며, 두 bounding box shape 간의 거리는 다음과 같이 정의된다:
$$d(s_i, s_j) = 1 - J(s_i, s_j)$$
- $s_i = (h_i, w_i)$, $s_j = (h_j, w_j)$: 각각의 bounding box shape (높이, 너비)
- $J(s_i, s_j)$: 두 shape 간의 IoU (Intersection over Union)
4.1 Architecture

최종 detector 구조는 다음과 같다:
- 입력 이미지 생성:
- coarse image pyramid 생성 (0.5x, 1x, 2x 포함)
- CNN 처리:
- 각각의 해상도에서 CNN을 통과시켜 binary heatmap 예측
- Template 적용:
- A-type은 모든 해상도에서 적용
- B-type은 오직 2x upsample된 해상도에서만 적용
- Post-processing:
- heatmap을 기반으로 non-maximum suppression (NMS) 적용하여 최종 탐지 결과 생성
전체 모델은 end-to-end 학습이 가능하며, 학습 시 각 위치별 IOU 기준으로 positive/negative를 정의하고 hard-example mining도 함께 수행한다.
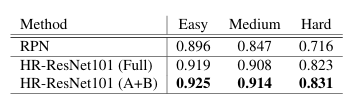
- ResNet-101을 기반으로 한 모델이 가장 좋은 성능을 보인다.
- 모든 모델이 기존 SOTA(CMS-RCNN)보다 "Hard(작은 얼굴)" subset에서 현저한 성능 향상을 보였다.
- 특히 본 방법은 proportional context modeling 대신 scale-variant local context modeling을 적용했다.
즉,
- 해상도 조절을 통해 scale-specific template을 적절한 크기로 매핑하는 전략이 효과적이다.
- 작은 객체는 upsampling, 큰 객체는 downsampling을 통해 medium-size로 정규화하여 탐지 성능 향상 가능
- 전체 모델은 소수의 template만으로도 다양한 객체 scale을 커버할 수 있다.
Training Details
- Positive/Negative location 정의:
- Positive: IoU overlap > 70%
- Negative: IoU overlap < 30%
- 나머지 위치는 gradient zeroing 처리.
- 문제:
- 큰 객체는 positive 예제를 많이 생성하나,
- 작은 객체는 적게 생성함 → 심각한 class imbalance.
- 해결:
- Balanced sampling
- Hard-example mining
- Post-processing:
- Linear regressor를 적용해 bounding box location을 미세 조정.
- Train-time Data Augmentation:
- Random resize (0.5x, 1x, 2x)
- Fixed-size crop (500×500)
- Fine-tuning:
- Pre-trained ImageNet models 사용
- WIDER FACE training set에서 fine-tune
- Learning rate: $10^{-4}$
- Evaluation:
- Validation set (diagnostics용)
- Held-out test set
- Final detection:
- Detected heatmap에 대해 NMS (Non-Maximum Suppression) 적용
- Overlap threshold: 30%
5. Experiments
WIDER FACE
- 총 25개의 template을 학습함.
- 최종 모델은 HR-ResNet101 (A+B) 구조로 구성됨.
- 각 template은 다양한 scale과 resolution에 대응하도록 설계됨.
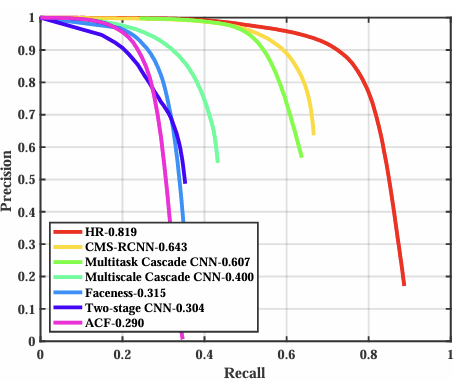

특히 Hard set에서 기존 방법 대비 오류율을 절반으로 감소시킴.
"Hard" set은 10px 이상의 작은 얼굴을 포함하므로, small object detection 성능을 직접적으로 반영함.

다양한 조건(표정, 흐림, 조명 등)에 대해 강건하게 얼굴을 탐지함.
매우 작은 얼굴까지도 성공적으로 탐지함.
FDDB
- WIDER FACE로 학습한 모델을 그대로 적용 (zero-shot).
- bounding box → ellipse 변환을 위한 post-hoc regressor 학습하여 FDDB에 대응.

Discrete score와 Continuous score 모두에서 SOTA 성능 달성.
HR-ER 모델이 기존 모든 방법을 능가함.
Run-time
- 속도(ResNet-101 기반):
- 1080p 해상도: 1.4 FPS
- 720p 해상도: 3.1 FPS
탐지할 얼굴 수에 무관하게 일정한 속도 유지 (Fully-convolutional 구조 덕분)
Faster R-CNN과 같은 proposal-based 방식과 달리, 탐지 대상 수에 따라 속도가 느려지지 않음
Conclusion
이 논문은 small face를 잘 탐지하기 위한 간단하고 효과적인 방법을 제안한다.
Contributions
- context를 활용해 작은 객체 탐지 성능을 크게 향상시켰다.
→ foveal descriptor를 사용해 고해상도 디테일과 전역 문맥을 동시에 반영 - resolution를 조절해 사전 학습된 네트워크의 scale 편향 문제를 해결했다.
→ 작은 얼굴은 이미지를 2배 upsample해서 탐지, 큰 얼굴은 downsample해서 탐지 - 효율적인 detector 구조를 만들었다.
→ 꼭 필요한 scale-specific template만 사용해 빠르고 정확한 탐지가 가능 - WIDER FACE와 FDDB에서 기존보다 최대 2배 낮은 오류율을 기록하며 SOTA 성능을 달성했다.



