
https://arxiv.org/abs/2407.15356
X-Recon: Learning-based Patient-specific High-Resolution CT Reconstruction from Orthogonal X-Ray Images
Rapid and accurate diagnosis of pneumothorax, utilizing chest X-ray and computed tomography (CT), is crucial for assisted diagnosis. Chest X-ray is commonly used for initial localization of pneumothorax, while CT ensures accurate quantification. However, C
arxiv.org
Abstract
- 흉부 X-ray와 CT는 기흉의 진단 과정에서 필수적이며, 특히 CT는 정확한 정량화를 수행하나 방사선량 및 비용 ↑
- X-Recon : 정측면 흉부 X-ray image 기반 CT ultra-sparse reconstruction network
- GAN : Generator (multi-scale fusion rendering module) / Discriminator (3D coordinate convolutional layer)
- Projective spatial transformer : multi-angle projection loss 통합
- PTX-Seg : 공기 축적 영역 / 폐 구조 segmentation 위해 이미지 처리 기술과 Deep-learning model 결합
- 대규모 dataset을 이용한 실험 결과, 기존 접근 방식보다 우수한 성능
- 높은 reconstruction resolution : 높은 공간적 해상도, 얇은 두께
- Reconstruction metrics : 다양한 지표에서 최첨단 성능
- PTX-Seg : 높은 segmentation 정밀도
- 원본 CT와 비교 시 공간 구성 측면에서 높은 유사도
1. Introduction
- 기흉 (Pneumothorax) : 폐와 흉벽 사이 흉막강에 공기가 축적되는 현상, 흔하지만 심각한 임상적 문제
- 기흉 진단 과정에서 사용되는 X-ray, CT
- X-ray : 방사선량 ↓, 보급률이 높아 1차 의료에서 용이
- CT : 신체 내부의 자세한 이미지를 제공하여 기흉에 대한 자세한 진단 가능 (존재 여부, 크기 및 위치 추정, 긴장성 기흉 여부, 종격동 변위), 하지만 비용 ↑ , 방사선 노출 시간 ↑
→ 방사선 노출을 줄이면서 고품질 CT image를 생성하는 기술 고안
- Low-dose biplane X-ray를 사용해 3D CT image 재성 시도
- 환자가 흡수하는 방사선량 ↓ (1~10mSv → 0.02mSv)
- 추가 장비없이 기존 X-ray machine만 가지고 구현 가능
- 3D geometries를 2D로 바꾸는 과정에서 information loss 발생 → 2D to 3D reconsturction 과정은 challenge
- 광원, 초점, 질감, 동작과 같은 간접 정보를 기반으로 3D object 모양을 재구성해야 함.
- Traditional method는 object의 multiple view를 필요로 하나, 최근 Learning-based view synthesis 기술이 엄청난 결과를 보이며 발전하고 있음 (Nerf : 복잡한 장면에서도 image reconstruction을 수행, data-driven robust reconstruction)
- 기존 multi-view, large number image projection 방식에서 벗어나, Sparse-sampling CT reconstruction을 통해 적은 sample 수에서 CT image reconstruction을 수행하려는 시도, 최근에는 biplane X-ray만으로 CT image를 재구성하려는 ultra-sparse reconstruction에 대해 연구 중.
- Henzler et al. : CNN을 적용하여 2D X-ray로부터 3D 두개골 volume 재구성
- Kasten et al. : end-to-end CNN을 적용하여 biplanar X-ray에서 3D 무릎뼈 재구성
- Shen et al. : Representation, Transformation, Generation module을 이용한 network를 적용하여 Single or multiple 2D X-ray에서 volumetric image 재성

- X-Recon : Orthogonal view biplane X-ray를 사용하여 Ultra-sparse 3D tomographic reconstruction network 제안
- GAN : Generator에서 MFusionRen, Discriminator에서 3D coordinate convolution layer로 구성
- ProST : Supervision을 위해 multi-angle projection loss 도입, 해부학적 사전 지식 통합 및 대규모 dataset를 활용한 mapping relationship 학습
- Higher CT reconstruction resolution : 224 ×`224 × 224 pixel, 1.6mm, 전례없는 해상도 측면에서 SOTA 기준을 재설정
- PTX-Seg : zero-shot segmentation framework, 기존 이미지 처리방식과 deep learning model을 결합하여 공기축적 영역 / 폐 영역을 경계짓고 그 부피 비율을 측정, 실제 CT와 상관계수 0.77 달성, 임상에서 적용될 수 있는 잠재성
- Contribution
- 오직 2개의 projection view를 활용해 ultra-sparse 3D tomographic image reconstruction을 수행하는 X-Recon 2D-3D CT reconstruction network 제안
- MFusionRen module, coordinate convolution, multi-angle projection loss을 도입하여 CT image 해상도 개선
- 영상 처리 기술과 deep learning model을 결합하여 재구성된 CT image 품질 평가에 이용되는 PTX-Seg 제안
2. Related Works
2-A 2D-3D vision reconstruction
- Shape-from-X method : Multi-view stereo vision 분야에서 2D image로부터 3D infromation 추출
- 3D로부터 2D image를 projection하는 수학적 공식을 제공하는 geometrical 관점에서 시작해, Projection invesion algorithm 문제로 접근
- Binocular vision-based : 다양한 viewpoint의 feature matching, 3D coordinate 이용
- Contour-based : 정확히 segmented된 2D contours
- 인간의 지각 패턴에서 영감을 받아, 사전 지식을 기반으로 한쪽 눈만 사용하여 object size와 geometry를 대략적으로 추론 가능하다는 점에서 착안
- Deep learning view synthesis (NeRF 등) : 복잡한 카메라 보정 프로세스 없이 1개 이상의 RGB image에서 3D geometry를 직접 복구 가능
- 3D reconstruction 문제를 generative 문제로 변환, 사전지식을 통합, variant는 computer Vision, Graphics에 유망한 결과
- Reflection-based light imaging과 transmission-based X-ray imaging 사이에는 상당한 imaging principle 차이가 존재. 현 연구에 직접 원리를 적용하는 것은 불가하나 사전 지식을 deep learning에 통합하는 아이디어는 큰 영향
2-B Reconstruction of volumetric images from X-rays
- CT image는 다양한 각도에서 projection한 image를 수학적으로 invertion시켜 얻음.
- Filtered back projection (FBP) 등 기존 방법론에서는 streak artifact를 피하기 위해 일정 sampling 이상의 데이터를 수집해야함, 방사선 노출 시간이 길어져 방사선량 ↑
- Sparsely sampled CT reconstruction : Compressed perception, maximum posterioiri method를 기반으로 sample 수를 줄이도록 시도, regularization 항목을 통합하여 artifact를 줄였지만 품질 보장을 위해 여전히 몇 개의 viewpoints를 필요로 함.
- Sample 수를 줄이기 위해 다양한 시도를 하였으나, Biplane X-ray만으로 CT reconstruction을 수행하는 ultra-sparse sampling은 여전히 갈 길이 먼 상황
3. Methodology
X-Recon : X-ray image에 대한 일반화된 CT reconstruction network, 성능 향상을 위해 몇 개의 loss function 제안
PTX-Seg : 기존 이미지 처리 기술과 deep learning model 결합, Segmentation 작업 수행
3-A X-Recon: Dual View CT Reconstruction Network
- X-Recon은 DRR branch가 포함된 GAN paradigm을 따름.
- 정측면 X-ray 영상을 사전 조건으로 동시에 generator에 넣어 reconstructed CT 도출, reconstruction loss 계산
- ProST를 통해 reconstructed CT 출력, multi-angle projection loss을 supervision으로 사용하여 reconstructed image 품질 향상
- X-ray가 Discriminator에 prior condition으로 제공, 접근 가능한 정보가 향상되고 성능 개선, GAN 학습 절차가 용이해져 image 품질 향상

3-A1 Generator
- 3개의 독립적인 module로 구성 : 2개의 encoder-decoder module, 1개의 MFusionRend module
- 2개의 encoder-decoder : 서로 다른 viewpoint의 image를 처리하기 위해 동일한 network 구조를 사용
- 각 이미지를 분리된 pathway에서 처리 : Dual view image를 input으로 사용하여 featrue extraction 진행
- MFusionRend (multi-scale fusion rendering) module : reconstructed image의 최종 예측
- Decoder main branch : Dual viewpoint의 정보를 통합
- Output branch : multiple spatial level에서 feature 생성
- Encoder 기본 단위로 Dense connection module 사용
- Down-sampling module : Step size = 2
- Densely connected convolution block
- Compression block : output channel을 절반으로 줄임
- 다양한 spatial level에서 input image 정보를 보존하는 동시에 compressed / 추출된 feature 표현 생성
- Densely connected module을 cascading하고 skip connection을 통해 decoder로 전송하는 과정에서 달성

3-A2 Discriminator
- 전통적 GAN과 달리 X-Recon은 fully convolutional form으로 구성
- 기존 GAN은 input sample이 실제일 가능성을 나타내는 단일 숫자 출력
- Fully convolutional discriminator network에서는 행렬로 변환, 원본 이미지의 해당 영역이 실제일 확률 출력
- 고해상도 이미지 generation domain에서 강력한 generalization 기능
- Translation invariance : classification 등의 task에서 robust feature의 향상된 학습에 도움, 하지만 image object가 고정된 경우 위치 정보를 감지하는 능력을 제한
- CoordConv (Coordinate Convolution) : 좌표 정보를 feature map의 일부로 통합하여 translational dependency를 학습동안 유지
- 장기 위치는 비교적 고정된 상태로 유지하여 network가 위치 정보를 유지할 수 있도록
- CoordConv layer를 3D 형식으로 확장, 기존 conventional convolution layer 대체, 3D 형식으로 discriminator 유지
- feature extraction과 위치 정보의 fusion이 3D CoordConv을 통해 수행
- 3개의 cascaded convolutional down-sampling module 통과 : 2단계의 3D convolutional layer (step = 2), normalization layer, corrected linear unit with leakage로 구성
- Output convolutional layer : Compression, 최종 output matrix
3-A3 MFusionRend Module
- 2D - 3D block : 2D - 3D 간 차원 변환을 위해 feature map transformation 필요
- Channel dimension 방향을 따라 2D image 복제 및 stack하여 3D로 확장
- Encoder-decoder 사이에서 FCN을 통한 neuron 수 변환, 3D dimension 조정
- MFusionRend Module : final CT reconstruction 결과 생성
- 각 encoder view에서 추출한 feature map은 이후 Fusion 및 decoding module 내에서 통합, 이후 average feature map을 계산하여 각 decoder branch로 전송되어 Dual view information fusion을 용이하게 함
- Rendering module이 다양한 scale의 feature map에 대한 CT 값 예측에 사용, Normalization, up-sampling을 거쳐 생성된 다양한 scale의 CT value가 output branch에서 생성

3-B PTX-Seg: Zero-shot Peumothorax Segmentation Framework
- 기흉 segmentation을 위해, anatomical prior에 기반한 전통적 이미지 처리 기술과 learning-based method를 결합한 framework 도입, Two-branch segmentation framework
- Learning-based branch : U-Net을 사용하여 폐 실질 분할
- LOLA11 Challenge의 winning solution pre-trained weights 사용
- Robust segmentation을 위해 union model ensemble 적용
- Auxiliary branch : anatomical prior을 통합하는 기흉 영역 분리
- CT sequence를 환자 신체와 공기를 포함하는 영역으로 binarize : Threshold 적용, Coarse body mask 획득
- Body mask 세부 조정 : 폐 내부, 기도 영역의 공기 부분 제거
- Non-body mask : seed-point-based region-growing operation을 두 꼭지점에서 적용, Fine body mask 획득
- 폐 실질 부위와 Body mask의 intersection 수행 후 binarize하여 coarse segmentation 획득
- 추출된 영역에서 CT values가 매우 작은 곳 식별, final air accumulation region 획득

3-C Loss functions of X-Recon
3-C1 Reconstruction loss
- Reconstructed CT와 real CT 사이 높은 수준의 구조적 일관성 보장 목표
- 높은 수준의 구조적 정확성을 요구하므로 L2 loss 사용

3-C2 Digitally Reconstructed Radiograph loss (DRR loss)
- 2D projection space에서도 전반적인 구조에 제약 조건
- ProST (Projective-Spatial-Transformer) : Sparial transformer를 projection geometry로 일반화, 미분가능한 projection rendering 가능케 하여 end-to-end image 처리 및 gradient 기반 optimization
- 다양한 image view에서 real CT projection과 reconstructed CT projection의 일관성 보장
- 3가지 직교 뷰에서 projection 수행, robustness 향상을 위해 training 중 stochastiv viewpoint 회전 및 변환
- L1 loss 사용하여 output 결과가 input 조건을 맞춤
- multi-angle projected image에 적용되어 가장자리 선명도 강화
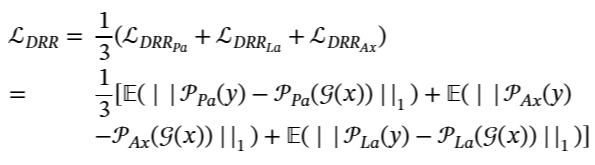
3-C3 Generative adversarial loss (GAN loss)
- GAN은 실제 데이터 분포를 formulate, cGAN은 data generation process supervision 및 향상 - conditional input
- 2D X-ray image를 사전 정보로 training process에 도입
- 원본 X-ray와 동일한 의미 정보 보존을 위해 generator 내에서 2D X-ray 이미지를 사전 지식으로 통합
- 사전 조건은 Discriminator에도 통합, 학습 기능을 높여 CT image 품질을 향상시키도록 동기 부여
- LSGAN loss 사용

4. Experiments
4-A Dataset collection
255명의 기흉 환자 vs 279 건강한 환자의 CT - 환자당 1개, Segmentation labeled by specialist
DRR 이용하여 X-ray 이미지 생성
4-B Implementation Details
훈련 파이프라인 설명
4-C Segmentation Performance of PTX-Seg
의사가 표시한 label 사용해 segmentation 성능을 정량적으로 평가
4개의 지표 사용, 훌륭한 segmentation 정확도를 보임.

4-D Reconstruction results of X-Recon
4-D1 Qualitative analysis
- 건강한 환자 : 폐 실질이 명확, 기관 위치와 형태가 실제와 일치
- 기흉 환자 : 균열을 따라 올라갈 수 있는 폐 가장자리 주변 가스 테두리, 압박된 폐 가장자리 관찰 가능, 기도 방향 실제와 일치, 기흉 영역과 폐 경계 뚜렷하게 구분, 부피와 위치도 일치

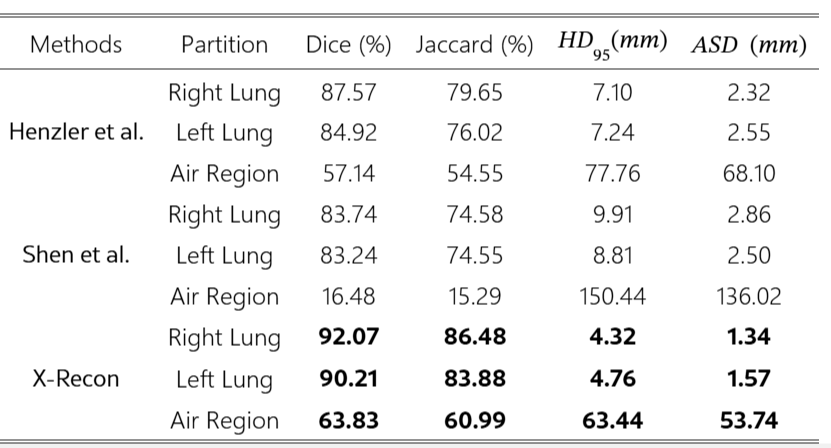
4-D2 Comparison with reconstruction methods
X-Recon과 SOTA 방법 비교, 2가지 learning-based single-view reconstruction method
- 정성적 평가
- Shen et al., Henzelr et al. : single view X-ray 이미지에 맞게 설계, 다른 viewpoint에 대한 흔적 흐릿, Shen은 심장 흉벽과 같은 대형 장기는 폐의 세부 정보를 잃어버림. Henzler는 폐 실질을 잘 구현하나 공기 축적 영역 재구성에 어려움
- X-Recon : 폐 미세 구조적 변화 포착, 공기 영역 우수한 재구성, 3D 렌더링 상 실제 CT와 높은 유사성, 공기 영역에서도 유사

- 정량적 평가 : 전반적으로 뛰어난 성능으로 평가됨
- Reconstruction quality : 3가지 지표에 대해 평가 (CS, PSNR, SSIM)
- Diagnostic performance : 공기 축적 영역의 용적, 흉막강 점유율, 실제 CT와의 상관계수
- Image segmentation metrics : Segmentation 관련 지표 (Dice, Jaccard, HD95, ASD)

4-E Ablation Experiments
4-E1 Ablation experiments on the network structure
CoordConv, Skip Connection, Multiscale Fusion module 여부에 따라 성능 평가

4-E2 Ablation experiments with loss function
- Reconstruction loss, multi-angle projection loss, adversarial loss 등 loss function의 영향
- 정성적 평가 : GAN loss 제거 시 폐 실질 흐릿, Reconstruction loss나 multi-angle projection loss 제거 시 폐 실질 부분이 개선되나 공기축적 영역과 폐 사이 경계 불분명, 3가지 loss 모두 학습 시 좋은 결과 - 폐실질 명확, 경계 정의

- 정량적 평가 : 모든 손실 함수 사용 시 높은 성능, 임상적 진단 잠재력

5. Discussion
- X-Recon과 PTX-Seg는 정성적, 정량적 실험을 통해 우수한 segmentation 정확도
- 폐 실질의 상세한 정보를 유지하는 데 있어 고해상도 ultra-sparse reconstruction 성능 실현
- 실제 CT와 비교했을 때 기흉 공기 축적 영역 백분율의 상관계수가 높음
- 한계점
- 비용 및 윤리적 문제로 DRR로 시뮬레이션한 X-ray 사용, 미세 조직 구조 포착에 한계, 앙와위 촬영으로 목표 임상 시나리오와 다름
- 해상도 개선 여지, 고해상도 CT scan의 분해능에 미치지 못함
- DRR의 실제 X-ray와의 불일치 문제 해결, style migration 연구로 보완 : 데이터 수집 제한 극복, 실제 데이터를 쌍으로 생성하는 솔루션
- 높은 해상도 달성을 위해 Vision community의 새로운 방법론과 이론을 도입
6. Conclusion
- X-Recon network를 제안하여 정측면 흉부 X-ray를 기반으로 고해상도 CT image reconstruction
- PTX-Seg : 환자별 연관성 분석을 수행하는 기흉 Segmentation algorithm
- Experiment를 통해 높은 정확도의 CT sequence 생성, 기흉 관련 정량적 지표 평가
- 다른 흉부 질환 진단으로 영역 확장 가능, 정밀 의학 발전의 토대
'CV' 카테고리의 다른 글
| [2025-1] 이재호 - 3D Gaussian Splatting for Real-Time Radiance Field Rendering (0) | 2025.03.29 |
|---|---|
| [2025-1] 김유현 - Improved Training of Wasserstein GANs (0) | 2025.03.22 |
| [2025-1] 전연주 - NeuralRecon: Real-Time Coherent 3D Reconstruction from Monocular Video (0) | 2025.03.22 |
| [2025-1] 임수연 - PIFuHD (0) | 2025.03.19 |
| [2025-1] 정성윤 - Inception-Net 논문 리뷰 (0) | 2025.03.15 |



