
https://arxiv.org/abs/1412.3555
Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling
In this paper we compare different types of recurrent units in recurrent neural networks (RNNs). Especially, we focus on more sophisticated units that implement a gating mechanism, such as a long short-term memory (LSTM) unit and a recently proposed gated
arxiv.org
0. Abstract
- tanh RNN과 비교하여, 게이팅 메커니즘을 갖춘 LSTM과 GRU가 더 나은 성능을 보이는지 분석
- 실험을 통해 LSTM과 GRU가 기존 방식보다 우수하다는 결과를 얻었으며, 특히 GRU는 LSTM과 유사한 성능을 보였다. 즉, LSTM과 GRU가 기존 RNN보다 더 효과적인 선택지가 될 수 있음을 시사한다.
1. Introduction
- LSTM이 긴 의존성을 가진 순차적 데이터 처리에 효과적이라는 것은 널리 알려져 있지만, GRU는 비교적 최근에 기계 번역 분야에서 사용되기 시작하였다.
- 이 연구에서는 LSTM, GRU, 그리고 전통적인 tanh 유닛을 시퀀스 모델링 작업에서 평가하였다.
- 실험 결과, 모든 모델에서 동일한 수의 매개변수를 사용한 경우, 일부 데이터셋에서는 GRU가 LSTM보다 더 빠르게 수렴하며, 매개변수 업데이트 및 일반화 면에서도 더 우수한 성능을 보일 수 있음을 확인하였다.
2. Background
2.1. RNN(Recurrent Neural Network)
1. RNN Definition
- 기존의 피드포워드 신경망을 확장한 형태로, 가변 길이의 시퀀스 입력을 처리할 수 있다.
- RNN은 순환(hidden) 상태를 가지며, 특정 시간의 활성 상태는 이전 시간의 활성 상태에 영향을 받는다.
$$h_{t}=ϕ(h_{t-1},x_{t}) \,\,\,\,(if \,\,\,\, t=0\,\,\,\,h_{t}=0)$$
- 생성 모델(generative RNN)은 현재 상태$h_{t}$를 기반으로 다음 시퀀스 요소에 대한 확률 분포를 출력할 수 있다.
- 생성 모델은 시퀀스의 끝을 나타내는 특별한 출력 기호를 사용하여 가변 길이 시퀀스의 분포를 캡처할 수 있다. 마지막 요소는 시퀀스 종료값을 의미한다.
- 시퀀스의 확률 분포
$$p(x_{1},...,x_{T})=p(x_{1})p(x_{2}|x_{1})...p(x_{T}|x_{1},...,x_{T-1}))$$
- 각 조건부 확률 분포는 다음과 같이 모델링된다.
$$p(x_{T}|x_{1},...,x_{T-1})=g(h_{t})$$
- 여기서 $h_{t}$는 앞서 정의한 상태 업데이트 식을 따른다.
2. RNN Problem
1. 기울기 소실(vanishing gradient)
2. 기울기 폭발(exploding gradient)
3. Solution
1. Better Learning algorithm
1. 기울기 클리핑(gradient clipping)
2. 2차 최적화 방법(second-order methods)
2. Better activation function(activation function -> gating unit)
1. LSTM(Long Short-Term Memory)
2. GRU(Gated Recurrent Unit)
3. Gated Recurrent Neural Networks
3.0. RNN
- 기존의 순환 유닛은 입력 신호의 가중합을 계산한 후 비선형 함수를 적용하는 방식
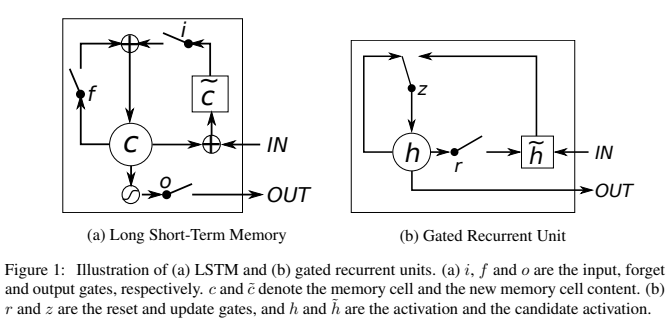
3.1. LSTM
- LSTM은 메모리 셀을 유지
- $c_{t}^{j}$ : LSTM의 j번째 메모리 셀 상태
- 출력 $h_{t}^{j}$
$$h_{t}^{j}=o_{t}^{j}⋅tanh(c_{t}^{j})$$
- 출력 게이트 $o_{t}^{j}$는 메모리의 정보를 얼마나 노출할지를 조절
$$o_{t}^{j} = σ(W_{o}x_{t}+U_{o}h_{t-1}+V_{o}c_{h})$$
- 메모리 셀 $c_{t}^{j}$는 기존 메모리를 부분적으로 잊고 새로운 정보를 추가하여 업데이트
$$c_{t}^{j}=f_{t}^{j}⋅c_{t-1}^{j}+i_{t}^{j}⋅~c_{t-1}^{j}$$
- 새로운 메모리의 내용은
$$~c_{t-1}^{j}=tanh(W_{c}x_{t}+U_{c}h_{t-1})$$
- 기존 메모리를 얼마나 잊을지 결정하는 망각 게이트(forget gate) 와 새로운 정보를 얼마나 추가할지 결정하는 입력 게이트는 다음과 같이 계산
- LSTM 유닛은 게이트를 활용하여 중요한 정보를 오래 유지할 수 있다.
- LSTM은 입력 시퀀스에서 중요한 특징을 감지하면, 이를 장기간 보존하여 장기 의존성을 학습하는 데 효과적
3.2. GRU

- LSTM과 비슷한 게이트 구조를 사용하지만, 더 간결한 형태로 설계된 순환 신경망(RNN) 유닛
- 게이트 메커니즘을 이용해 정보의 흐름을 조절하지만, 별도의 메모리 셀을 사용하지 않는다.
- 현재 상태 $h_{t}^{j}$는 이전 상태 $h_{t-1}^{j}$와 새로운 상태 ~$h_{t}^{j}$ 사이의 선형 보간으로 결정된다.
- 업데이트 게이트(update gate)$z_{t}^{j}$ 가 현재 상태를 얼마나 업데이트할지를 결정
$$h_{t}^{j}=(1-z)h_{t-1}^{j}+z_{t}^{j}~h_{t}^{j}$$
- LSTM과 유사하게 기존 상태와 새로운 상태를 가중합하는 방식
- GRU는 LSTM처럼 별도의 출력 게이트가 없어, 상태를 항상 전체적으로 노출
- 새로운 상태 $\widetilde{ h_{t}^{j} }$는 기존 RNN의 활성화 함수와 유사하게 계산된다.
$$\widetilde{ h_{t}^{j} }=tanh(W_{h}x_{t}+U_{h}(r_{j}^{t}⊙h_{j}^{t-1}))$$
- 리셋 게이트$r_{j}^{t}$가 도입되며, 이는 이전 상태를 얼마나 잊을지를 결정한다.
$$r_{j}^{t}=σ(W_{r}x_{t}+U_{r}h_{t-1}^{j})$$
- 리셋 게이트가 0에 가까울 경우, 이전 상태를 무시하고 새로운 입력을 처음부터 읽는 것처럼 동작
- LSTM과 달리 별도의 메모리 셀이 없어 구조가 단순하며, 계산량이 적다. 업데이트 게이트와 리셋 게이트가 존재하며, 추가적인 출력 게이트가 없다.
3.3. Discussion
1. Replace(RNN) vs Additive nature(LSTM, GRU)
1. Replace(RNN)
- 새로운 입력과 이전 상태를 이용해 계산된 값을 항상 기존 값을 대체
2. Additive nature(LSTM, GRU)
- 기존 상태를 유지하면서 새로운 정보를 추가
- 입력에서 특정 특징(feature)의 존재를 오랫동안 기억할 수 있다.
- 역전파 시 그래디언트 소실(vanishing gradient) 문제를 완화
2. LSTM vs GRU
1. 메모리 노출 방식
1. LSTM : 출력 게이트를 사용해 메모리 내용을 얼마나 노출할지를 조절
2. GRU : 항상 모든 내용을 노출
2. Input gate and Reset gate
1. LSTM: 새로운 메모리 내용이 얼마나 추가될지를 별도로 조절
2. GRU: 기존 상태에서 새로운 활성화 값을 계산할 때, 리셋 게이트를 이용해 흐름을 조절
- GRU에서는 새롭게 추가되는 값이 얼마만큼 반영될지 독립적으로 제어하지 않고, 업데이트 게이트를 통해 직접 결정
- 유사점과 차이점만으로 어떤 방식이 더 우수한지 일반적으로 결론을 내리기는 어렵기에 이 연구를 통해 성능을 비교하는 실험이 수행된다.
4. Experiment
4.1. Task and Dataset
- 순차 모델링 과제(확률 분포를 학습하는 작업)에서 LSTM, GRU 및 tanh 유닛을 비교
- 주어진 학습 데이터셋에서 로그 우도를 최대화(maximizing the log-likelihood) 하는 방식으로 학습을 진행
- 주어진 데이터셋에서 모델이 시퀀스를 올바르게 예측할 확률을 최대화하는 것이 목표
4.2. Models
1. 모델
1. LSTM 유닛을 사용한 모델 (LSTM-RNN)
2. GRU 유닛을 사용한 모델 (GRU-RNN)
3. Tanh 유닛을 사용한 모델 (tanh-RNN)
2. 세부 사항
1. 최적화 방법: RMSProp
2. 정규화: 가중치 노이즈를 표준 편차 0.075로 설정
3. 기울기 폭발 방지: 업데이트마다 기울기의 노름(Norm)을 1로 조정
4. 학습률 : 10개의 로그-균등 분포에서 무작위로 선택한 값 중에서 최적의 학습률을 결정
5. 조기 종료
5. Results and Analysis
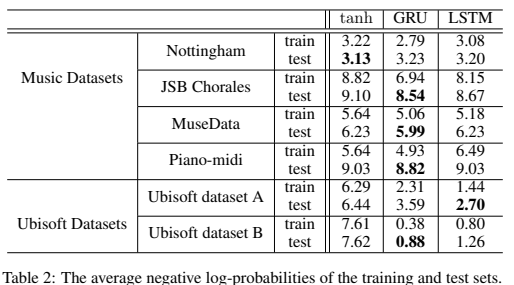
1. Music Datasets
- Nottingham 데이터셋에서는 LSTM-RNN
- 전체적으로 모든 모델이 유사한 성능
2. Ubisoft Datasets
- Ubisoft A 데이터셋: LSTM-RNN이 가장 좋은 성능
- Ubisoft B 데이터셋: GRU-RNN이 가장 좋은 성능
- GRU-RNN과 LSTM-RNN이 tanh-RNN보다 훨씬 뛰어난 성능
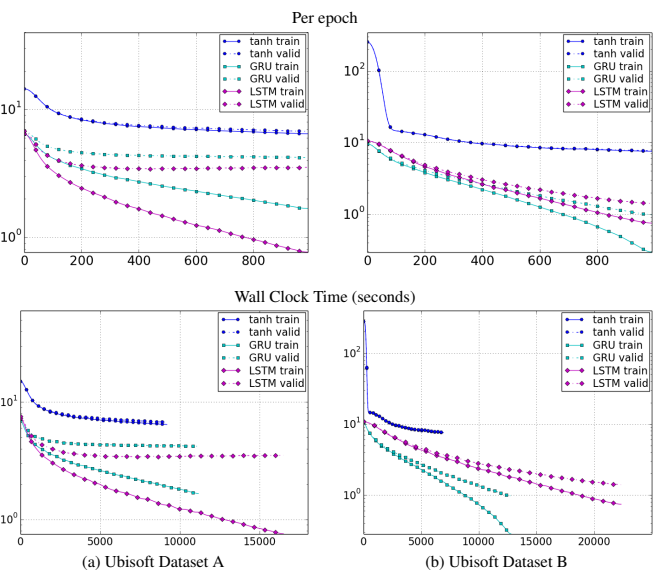
3. Graph
1. Music Datasets
- GRU-RNN이 학습 속도에서 더 빠른 발전
2. Ubisoft Datasets
- tanh-RNN은 연산량이 적지만, 성능 향상이 거의 없었고 조기 수렴
- GRU-RNN과 LSTM-RNN은 지속적으로 성능 향상

6. Conclusion
- 게이팅 유닛(LSTM과 GRU)이 전통적인 tanh 유닛보다 우수한 성능을 보였다.
- 음성 신호 모델링에서 그 우수성이 더욱 뚜렷하게 나타남.
- LSTM과 GRU 중 어느 유닛이 더 나은지에 대한 명확한 결론을 내리기에는 어려움이 있었다.
참고
https://velog.io/@lighthouse97/Gated-Recurrent-UnitGRU%EC%9D%98-%EC%9D%B4%ED%95%B4



