
원본 논문 링크 : https://ieeexplore.ieee.org/document/6874742
3D image reconstruction from 2D CT slices
In this paper, a 3D reconstruction algorithm using CT slices of human pelvis is presented. We propose the method for 3D image reconstruction that is based on a combination of the SURF (Speeded-Up Robust Features) descriptor and SSD (Sum of Squared Differen
ieeexplore.ieee.org
Abstract
- 이 논문에서는 정확한 인체 골반의 3차원 모델을 얻기 위해 SURF(Speeded-Up Robust Feature) descriptor와 image segmentation을 이용한 SSD(Sum of Squared Differences) 매칭 알고리즘을 결합한 3차원 영상 재구성 방법을 제안한다.
- 첫 번째로, 노이즈를 제거하고 부드럽게 하기 위한 노이즈 필터링을 적용한다. 다음으로, 필터링된 이미지는 Mean-Shift segmentation 알고리즘을 사용하여 segment로 분할한다.
- 두 번째로, Canny edge detector를 이용하여 edge를 추출한다. 그 후 각 segment에 대해 가장 좋은 corresponding point를 얻는다. 특정 픽셀에서 SSD 값이 작을 수록 해당 픽셀 근처의 첫 번째 이미지와 두 번째 이미지 사이에 유사성이 더 많이 존재한다.
- 마지막으로, Mean-Shift segmentation 알고리즘과 SURF-SSD와 통합한다.
- 실험 결과는 SURF-SSD 알고리즘이 image segmentation과 결합되어 인간 골반의 정확한 3D 모델을 제공하는 것을 보여준다.
- Index Terms — MRI, CT, image segmentation, SURF, human pelvis, SSD, 3D image reconstruction, SURF-SSD.
Introduction
- 최근 CT와 MRI는 광법위한 의료 응용 분야에서 현대적이고 가치있는 진단 방법이다.
- 의료 분야에서는 수술 뿐만 아니라 많은 질병의 진단과 치료를 위해 다양한 영상 기술이 사용된다. 2D CT 슬라이스를 활용한 3D volume 재구성은 의사에게 많은 이점을 제공한다. 이 목표를 수행하기 위한 중요한 단계는 최종 3D 모델을 추정하기 위해 입력 CT 슬라이스의 해당 키포인트를 일치시키는 것이다.
- 물체 감지, 자세 추정, 기하학적 특성 및 3D 정보 추출은 많은 Vision 시스템에서 중요한 문제이다. 더 나아가 인간의 뇌, 심장, 전립선 등 인체 장기 표면의 몇 가지 reference key 포인트에 따라 이상 위치를 아는 것도 중요하다.
- 이러한 문제를 해결하기 위해서는 view의 속성과 view 간의 특징점에 대한 지식이 필요하다 그러나 생물학적인 영상, 예를 들어 CT 데이터와 같은 것에서 이러한 특징점을 찾는 것은 매우 어렵다.
- 다음 그림은 이 논문에서 제시하는 알고리즘의 기본 단계이다. 후속 단락에서 자세히 설명한다.

- 3D reconstruction의 장점은 다음과 같다.
- 이를 활용하면 방사선 전문의는 새로운 multi-detector CT 스캐너에서 사용할 수 있는 대규모 데이터 세트를 처리하고 이를 현재 검사와 이전 검사를 보다 쉽게 비교할 수 있다.
- 선택된 3D 이미지를 영상의학 보고서에 첨부할 수 있으므로 참조하는 의사에 대한 서비스가 향상된다.
Image Segmentation
Image Segmentation의 주요 목표는 전체 이미지를 이미지를 포함하는 Segment 집합으로 분할하는 것이다. 이는 이미지 표현을 분석하기 쉬운 형식으로 단순화하는 것이다. 이 연구에서는 Mean-Shift 알고리즘을 사용하였다.
Mean-Shift 알고리즘
- Mean-Shift는 kernel density estimation을 기반으로 한다. 이 알고리즘은 각 포인트를 데이터 세트의 확률 밀도의 peak와 연결하여 n차원 데이터 세트(각 데이터 포인트는 n개의 feature vector로 나타남)를 clustering한다. 각 점에 대해 Mean Shift는 먼저 반경 r의 데이터 포인트에서 구형 window를 정의하고 window 내에 있는 점들의 평균을 계산하여 관련 peak를 계산한다.
- 그 후 알고리즘은 이동하는 정도가 임계값보다 작아질 때까지, 즉 수렴할때 까지 window를 평균으로 이동을 반복한다. 각 iteration에서 window는 peak에 도달할 때까지 데이터 세트의 밀도가 더 높은 부분으로 이동하며 여기서 데이터는 window에 균등하게 분산된다. Mean Shift clusters는 유클리드 거리 측정법을 사용한다.
- Mean-Shift의 과정은 다음과 같다:
- 반경 r의 search window를 선택한다.
- window의 초기 위치를 선택한다.
- mean shift 벡터를 계산하고 그만큼 window를 이동한다.
- 수렴할 때까지 반복한다.
Feature Matching
- Feature Matching 알고리즘은 3D Reconstruction의 정밀도를 향상시킨다.
- 이러한 종류의 알고리즘은 3D 장면에서 객체의 적합한 특징(ex. 입력 이미지의 edge segment 또는 contour segment)을 추출한다.
- 그 후 feature의 해당 핵심 포인트를 찾아 3D 모델을 생성한다. 감지된 feature의 key 포인트들은 일치되어야 한다.
- 다양한 알고리즘을 기반으로 하는 매칭 테크닉은 다음과 같다 : Correlation (C), Normalized Cross Correlation (NCC), Sum of Squared Differences (SSD), Sum of Absolute Differences (SAD)
- 이 논문에서는 SSD가 사용되었다.
- SURF의 주 목표는 viewing condition(ex. 크기, 방향, 대비의 변)이 약간 변경됨에도 불구하고 이미지 간의 일치를 위해 이미지 포인트의 collection에서 고유한 local structure를 인코딩하는 것이다.
- 다음 단계에서 SURF-SSD 알고리즘을 사용하여 해당 지점에서 3D point를 계산한다.
- SURF(Speeded-Up Robust Feature) Descriptor는 감지(detection), 설명(description), 일치(matching)라는 세 가지 feature detection 단계에서 고속을 보장하기 위해 고안되었다.
- approximate SIFT(Scale-Invariant Feature Transform)이라고도 알려진 SURF는 통합 이미지와 효율적인 scale space construction을 사용하여 key point와 Descriptor를 효율적으로 생성한다. SURF Desciptor는 SIFT의 감지 프로세스 속도를 높였다.
- SIFT와 SURF 알고리즘은 feature를 감지하는 데 약간 다른 방법을 사용한다. SIFT는 이미지 피라미드를 구축하여 sigma 값이 증가하는 Gaussian으로 각 layer를 필터링하고 차이를 취한다. 반면 SURF는 피라미드의 더 높은 레벨에 대해 2:1 다운샘플링 없이 "stack"을 형성하여 동일한 해상도의 이미지를 생성한다.
- 첫 번쨰 단계는 관심 해당 포인트 주변의 원형 영역 정보를 기반으로 재현 가능한 방향(?)을 고정하는 것으로 구성된다. 다음으로 선택한 방향으로 정렬된 사각형 영역을 구성하고 여기에서 SURF Descriptor를 추출한다. 마지막으로 feature는 두 이미지 사이에서 매칭된다.
2. SSD(Sum of Squared Differences)
- 영역 기반의 SSD 알고리즘은 SAD 알고리즘과 유사하다. 절대값을 계산하는 대신 SSD는 다음과 같이 intensity의 차이의 제곱을 계산한다.
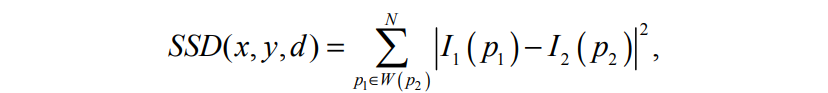
- 여기에서 $I_1$과 $I_2$는 각각 첫 번째 이미지와 두 번째 이미지의 픽셀 Intensity 함수이고 $d$는 disparity(?)이다. $W(x, y)$는 픽셀의 위치 $(x, y)$를 둘러싸는 정사각형 window이다.
- 해당 포인트를 찾는 퀄리티는 정사각형 window 크기에 따라 달라지며 window 크기가 클수록 일치하는 포인트에서 계산된 올바른 3D 포인트를 찾을 확률이 높아지지만 계산 속도는 느려진다.
3. SURF-SSD 알고리즘
- 매칭 알고리즘의 최종 성능은 매칭 cost의 선택에 따라 달라진다. 이 논문의 실험에서는 매칭 cost로 SURF-SSD 매칭 방법을 제안했다.
- SURF Descriptor는 대부분의 local gradient 정보를 제하고 SSD는 local intensity 정보를 제공한다. SURF-SSD는 두 부분으로 구성된다.
- 먼저 첫번째 이미지의 픽셀 $p_1$과 두번째 이미지의 픽셀 $p_2$ 사이에서 SURF의 $L2$ 거리를 얻는다,

- 다음으로 SSD 매칭 cost를 다음과 같이 정의한다.

- $SSD(p)$에 대해서는 더 자세하게 이후에 서술하겠다.
- 논문의 알고리즘은 9 X 9 픽셀의 정사각형에서 window 크지 치수를 갖는 모든 픽셀에 대해 가장 잘 일치하는 항목을 계산한다.
- 마지막으로 매칭 cost를 얻기 위해 1차원 Gaussian weight를 사용한다. 기본적인 가정은 최소값이 실제 surface에 해당하는 경우 이웃 픽셀이 비슷한 depth에서 가까운 값을 가져야 한다는 것이다.
Proposed Method and Experimental results
- 논문의 작성자들은 3.0GHz Intel Core i3 프로세서와 4GB DDR3 메모리를 탑재한 개인용 컴퓨터를 사용하여 실험하였다.
- 실험은 CT 슬라이스 이미지에 대해 수행되었고 MATLAB 환경에서 구현되었다.
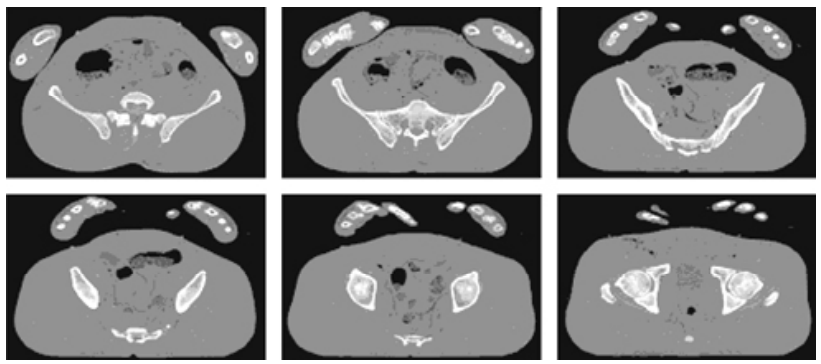
- 아래 그림의 실험에서 사용된 CT 슬라이스 이미지이다. 각각 587 X 341 픽셀이다.
- 다음 그림은 이 논문에서 제안된 아키텍처이다. SSD 매칭 알고리즘과 SURF Desciptor의 조합을 기반으로한 알고리즘은 전체 이미지 픽셀의 작은 부분이 매칭에 사용되기 때문에 더 빠르다.
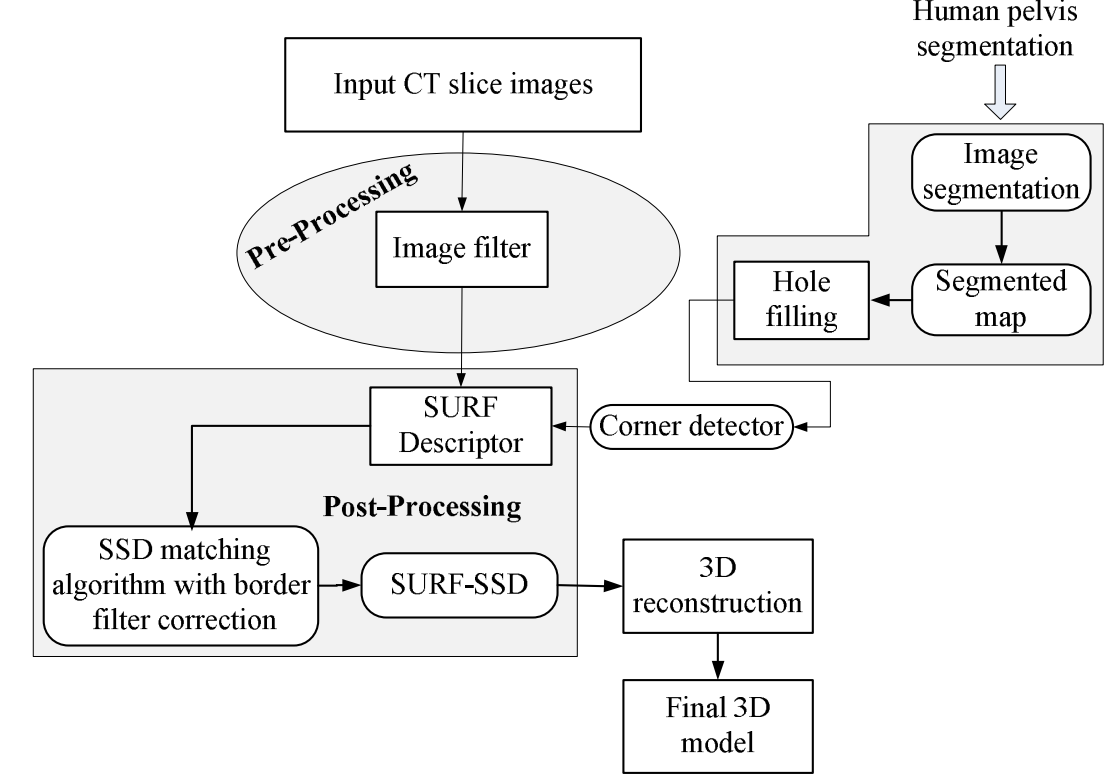
위의 아키텍처를 설명하자면, 다음과 같은 순서로 이루어져 있다.
- Mean-Shift 필터를 통해 이미지 필터링을 적용한다. 필터링은 노이즈가 mode detection(?)에 미치는 영향을 줄여주며 이것은 Mean-Shift Segmentation 프로세스의 첫번째 단계이다. 이 단계는 smoothing과 image segmentation에 매우 유용하다.
- 이미지의 각 픽셀에 대해 인접 픽셀 집합이 결정된다. 이 인접 픽셀 집합에 대해 새로운 spatial center(spatial mean)이 계산된다. 이렇게 계산된 평균값은 다음 iteration의 새로운 center 역할을 한다.
- 1~2의 과정은 spatial 및 grayscale 평균이 바뀌지 않을 때까지 반복된다.
- interation이 끝나면 최종 mean grayscale이 해당 iteration의 시작 위치에 할당된다.
- 필터링이 된 이미지는 Mean-Shift Segmentation 알고리즘을 사용하여 Segment로 분할된다. 작은 Segment는 가장 유사한 인접 Segment로 병합된다. Image Segmentation을 통해 뼈를 쉽고 빠르게 식별하고 표시할 수 있다.

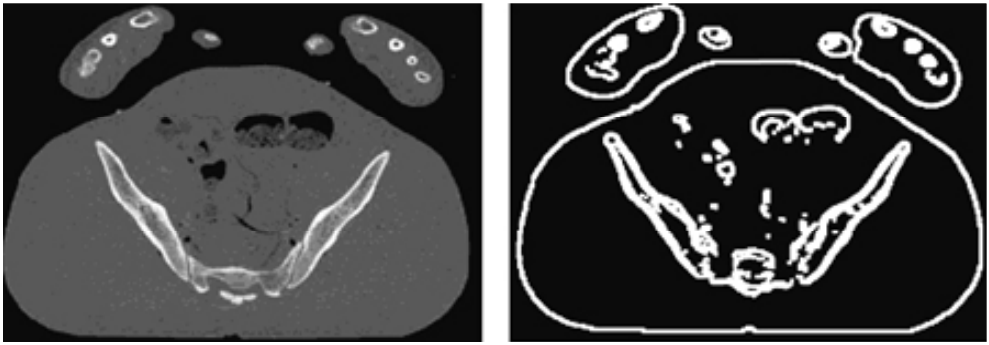
- 그 후 Canny edge detector를 사용하여 edge를 추출한다. (아래 그림 참고) Canny edge detector는 스케일 위치를 계산할 때 적합한 시작점이다.
- 각 세그먼트에 대해 연관된 포인트들을 살펴본다. 매칭이 수행되어 가장 일치하는 항목들을 얻는다. 매치 포인트는 SSD를 사용하여 얻는다. 특정 픽셀에서 SSD 값이 작을수록 해당 픽셀 근처의 첫번째 이미지와 두번째 이미지 사이에 더 많은 유사성이 존재한다.
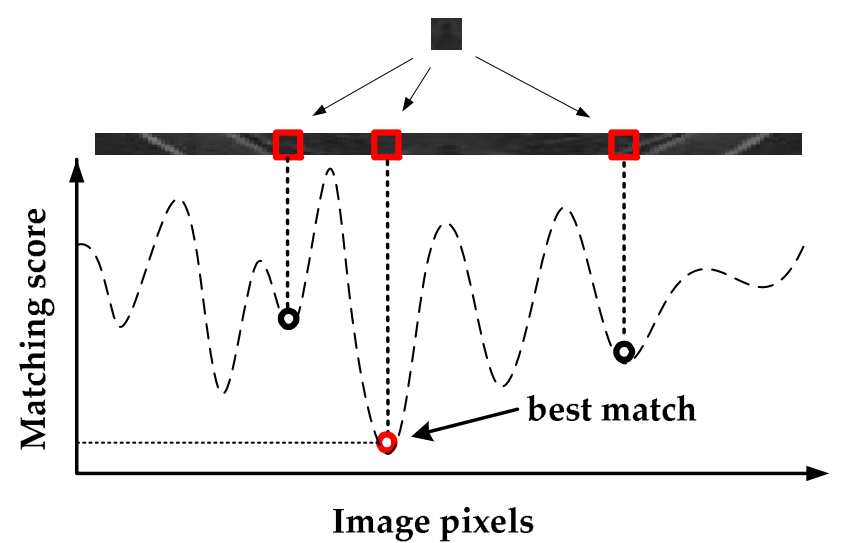
- Mean-Shift Segmentation 알고리즘을 SURF-SSD 방법과 통합한다. 이 방법은 SURF 부분과 SSD 부분으로 구성된다.
- SURF interest 포인트를 추출하고 두 개의 중첩 이미지에 describe 한 후 key-point descriptor를 일치시킨다. 이 단계에서는 전체 key point 공간을 search하여 모든 key point에 대해 가장 가까운 매칭 항목을 찾는다. 각 key point의 feature vector 간의 유클리드 거리 $L2$를 통해 가장 좋은 매칭 항목을 찾을 수 있다.
- 매칭되는 key point 공간적으로 너무 가까우면 잘못된 매칭이 이루어질 수 있으므로 매우 유사한 후보의 매칭은 제거된다. 가장 가까운 neighbor와 두 번째로 가까운 neighbor의 거리 비율이 SSD score 보다 작은 모든 매칭을 제거하는 것이 그 방법이다.
Results for Experiments
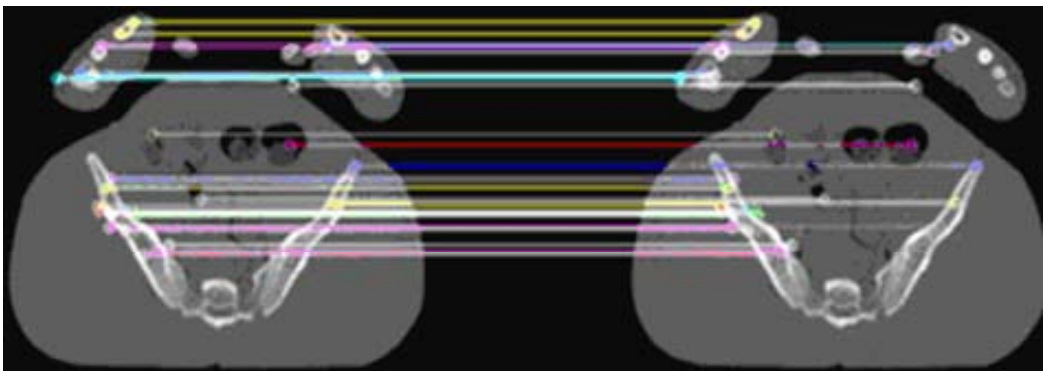
- 아래 그림에서 빨간색으로 표시된 것처럼 SURF-SSD 방법을 사용하여 모든 Segment의 해당 지점을 얻었다.

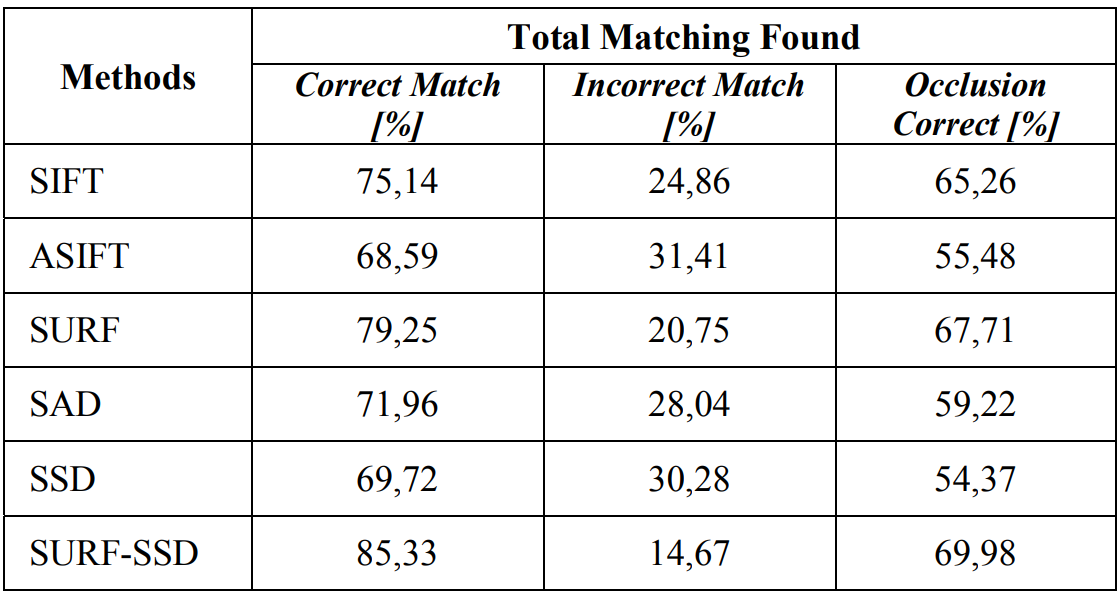
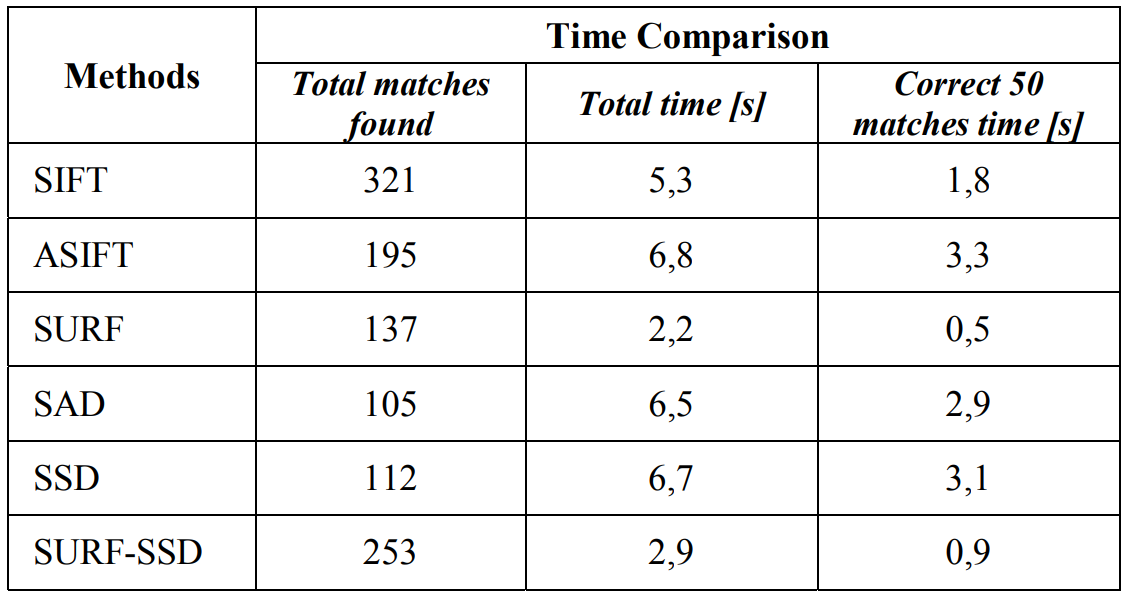
- 아래의 표는 전체 성능의 요약과 처리 시간의 비교를 보여준다. 논문에서 제시한 SURF-SSD 방법과 다른 여러 알고리즘들을 비교한 것이다. SURF-SSD 방법이 제일 효율적임을 볼 수 있다.
SURF-SSD 기반의 feature matching 알고리즘은 homogeneous(동질적인) area에 대해 최적의 매칭을 찾는 데 더 효과적인 알고리즘인 것으로 보였다.
- 아래 사진은 최종적으로 재구성한 3D 모델이다.

- 위 3D 모델의 표면 윤곽은 일반적으로 선택된 관심 영역의 경계에서 파생된 여러 개의 겹치는 다각형으로 모델링된다. 보간 기술을 이용하면 더 나은 결과를 얻을 수 있을 것이다.




