
Very Deep Convolutional Networks for Large-Scale Image Recognition
In this work we investigate the effect of the convolutional network depth on its accuracy in the large-scale image recognition setting. Our main contribution is a thorough evaluation of networks of increasing depth using an architecture with very small (3x
arxiv.org

Astract
- large-scale의 이미지 및 영상 인식에서 Convolution networks(ConvNets)가 큰 성과
- 3 x 3 convolution filter가 있는 모델 구조로 평가함
- Convolution Layer를 더하며 깊이를 16~19개로 늘림
- ImageNet Challenge 2014의 localisation and classification 분야에서 1, 2위를 차지하는 성과를 보임
1. Introduction
- Convolution networks(ConvNets)가 Large-scale의 이미지와 영상 인식 분야에서 큰 성과를 거둠에 따라 컴퓨터 비전 분야에서 Convnet이 보편화되고 더 나은 정확도를 달성하기 위해 모델의 구조를 개선하려는 시도가 많이 이루어짐
- 이전 시도로 첫 번째 Convolution Layer에 stride를 사용하였음
- 다른 시도로 전체 이미지를 multiple scale에 걸쳐 훈련 및 테스트하였음
- 이 논문에서는 모델의 파라미터를 고정시키고 모든 layer에 3x3 convolution filter를 적용시켜 네트워크의 깊이를 증가시킴
- 그 결과 예측에 정확한 Convolution Network를 실현시켰으며, 다른 이미지 인식 데이터 세트에서도 좋은 성능을 보임
2. Convnet Configurations
- 깊이 증가에 따라 Convolution Network의 정확한 성능 측정을 위해 모든 ConvNet layer로 동일하게 설정
- 내용은 구조, 세부적인 설정 사항, 다른 모델과 비교 설명 순으로 설명
Architecture
- 224 x 224 로 고정된 RGB 이미지를 입력으로 함 → 3 x 224 x 224
- 전처리 : train set에 대해 RGB값의 평균을 각 픽셀에 뺌
- stride : 1 (고정)
- padding : 1 (고정)
- max-pooling : 2 x 2
- 모든 hidden layer에서 ReLU activation function 사용
- Conv 이후 세 개의 FC(Fully-Connected) layer가 존재
- FC의 경우 모든 네트워크에서 동일한 설정으로 진행
- FC의 첫 번째와 두 번째는 4096의 channel을 갖고 세번째는 1000개의 채널
- 마지막 계층 softmax activation function 사용
- AlexNet에 적용된 LRN(Local Response Normalisation) 정규화는 VGGNet 성능에 영향이 없는데 메모리 소비와 계산 시간을 증가시켜 적용하지 않았음
Configurations
- 논문에서 Network A부터 E까지 보여줌
- A : 11 layer ~ E: 19 layer
- 채널의 개수는 첫 번째 layer에서 64개부터 시작해 512개에 이를 때 까지 2배씩 증가
Discussion
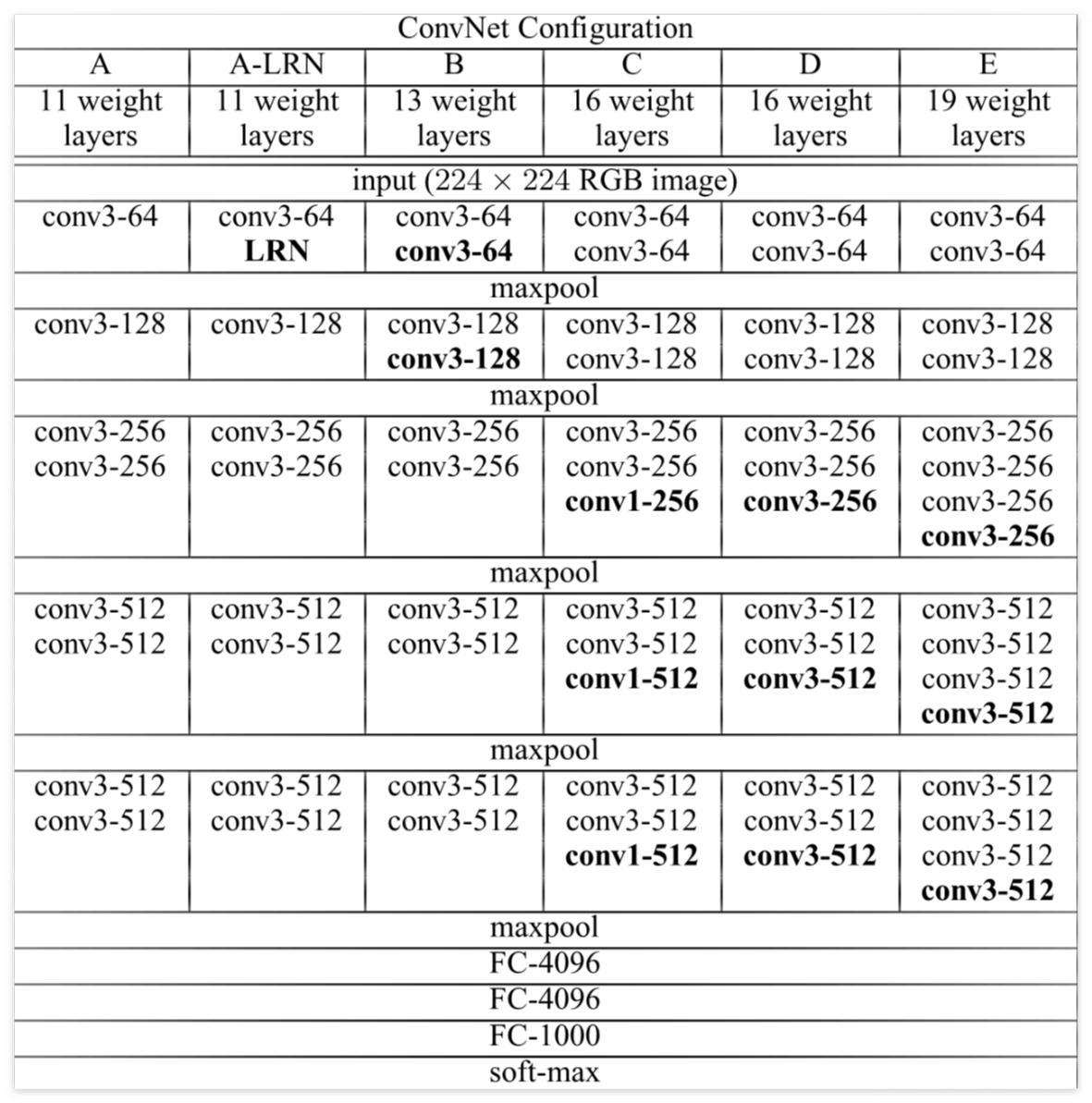

- 모든 네트워크에서 3 x 3 필터(stride 1)를 사용
- 3 x 3 필터 2개가 5 x 5 필터 1개의 성능을 보이고
- 3 x 3 필터 3개가 7 x 7 필터 1개의 성능을 보임
- ReLU을 한 개의 층이 아닌 세 개의 층에 사용하면서 비선형성을 늘리고 파라미터 수를 줄이게 됨

3. Classification framework
Training
- 학습 과정은 입력 이미지 crop을 제외하고는 AlexNet과 동일하게 진행
- batch size = 256
- momentum = 0.9
- weight decay = 0.00005
- 첫번째 두번째 FC layer는 dropout 0.5적용
- learning rate = 0.02 설정 후 정확도 개선 없을 시 0.1씩 곱함
- epoch = 74
- pre-initialisation
- 학습을 해결하기 위해 pre-initialisation을 이용
- 가장 얇은 구조인 network A를 학습시킨 이후에 Conv layer와 3개의 FC layer를 이용하여 다른 깊은 모델을 학습시킴
- 가중치 초기화 값은 평균 0 분산 0.01인 정규 분포에서 무작위로 추출
- data augmentation
- 3가지의 데이터 증강(data augmentation)이 적용하고 rescale을 하여 비교
- crop된 이미지를 무작위로 수평 뒤집기(random horizontal flipping)
- 무작위로 RGB 값 변경하기(random RGB color shift)
- image rescaling
- 3가지의 데이터 증강(data augmentation)이 적용하고 rescale을 하여 비교
Testing

- Q : test scale
- S : rescaled training image의 가장 작은 쪽의 픽셀 수, training scale
- S = 256 or S = 384
- Multi-scale training
- $S_{min}, S_{max}$ 범위 내의 임의의 값 샘플링
- scale jittering
Implementation details
- 2013년 12월에 출시된 C++ Caffe 를 이용해서 구현
- 4-GPU system
- training 이미지의 각 batch가 GPU에서 수행되고 각각의 GPU에서 병렬하게 처리
- 각각의 GPU batch gradient는 계산 후 모든 batch에 대한 gradient를 얻기 위해 평균을 이용
- 학습 시간은 2~3주가 소요
- single GPU보다 속도 3.75배 빠름
4. Classification experiments
- ILSVRC-2012 데이터에 대해 해당 모델이 이뤄낸 분류 결과 제시
- ILSVRC에서 top-1, top-5 error를 이용하며 top-5 error를 주된 평가 항목으로 사용
- 데이터 세트1000개의 class 이미지를 포함 (training : 130만장, validation : 5만장, testing : 10만장)
- 분류 성능은 2가지로 판단, top-1 error와 top-5 error (주된 평가 : top-5 error)
- top-1 error는 예측이 잘못된 이미지의 비율
- top-5 error는 예측된 범주에 정답이 없는 이미지의 비율
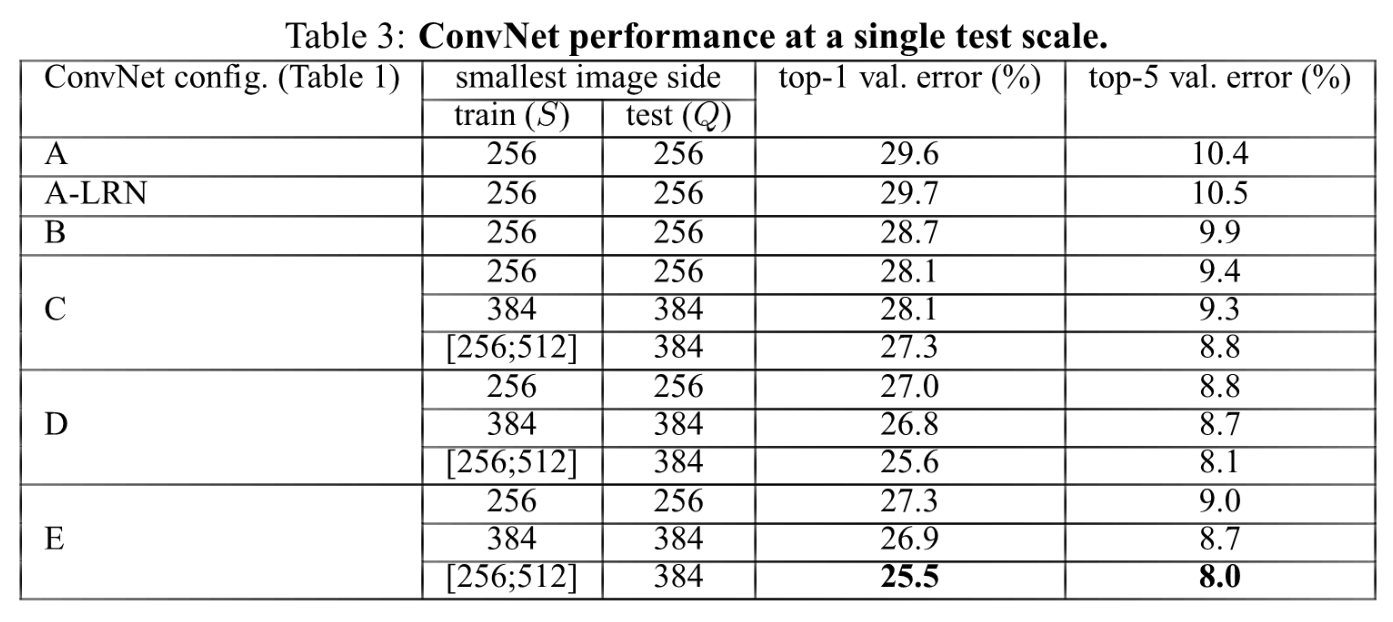
Single scale evaluation
- AlexNet에서 이용되었던 LRN(local response normalisation)을 모델 A에 적용한 결과 큰 성능 향상이 없어 나머지 모델에서는 LRN을 적용 X
- ConvNet depth가 증가할수록 classification error가 감소
- 다양한 scale[256~512]로 resize한 것을 Scale jittering이라고 하는데 고정된 scale의 training image보다 성능이 좋았음
Multi-scale evaluation
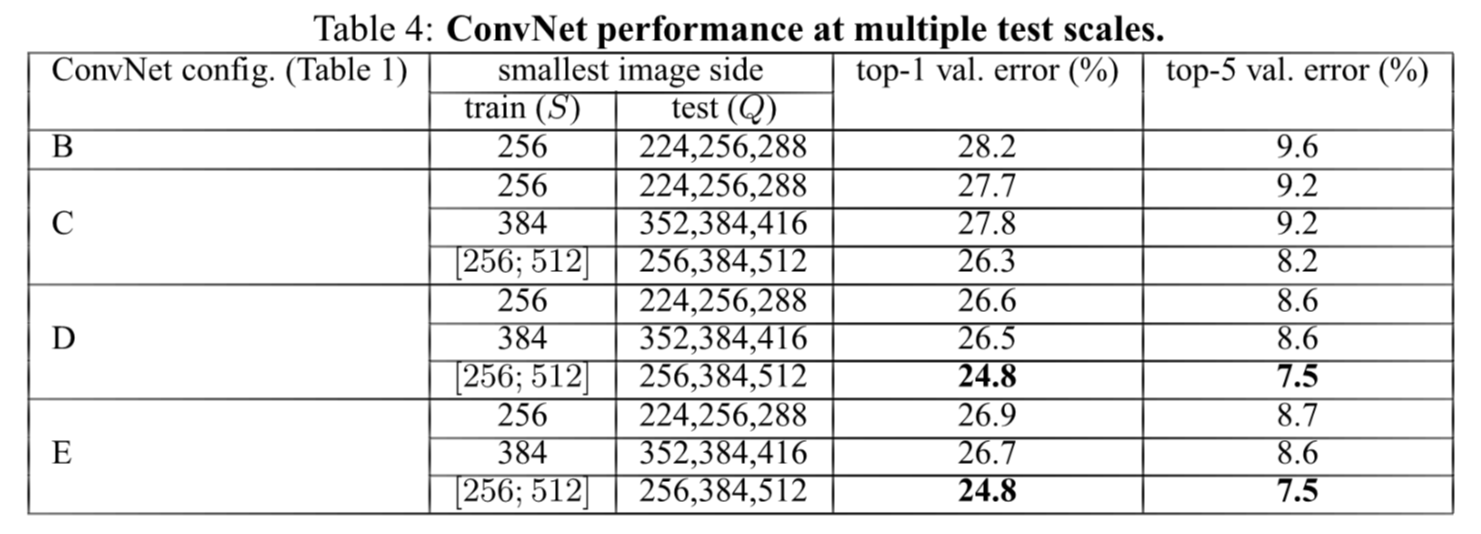
- mutil scale이 single scale보다 더 좋은 결과
- 또 깊이가 더 깊은 네트워크가 더 좋은 결과를 보임
Multi-crop evaluation
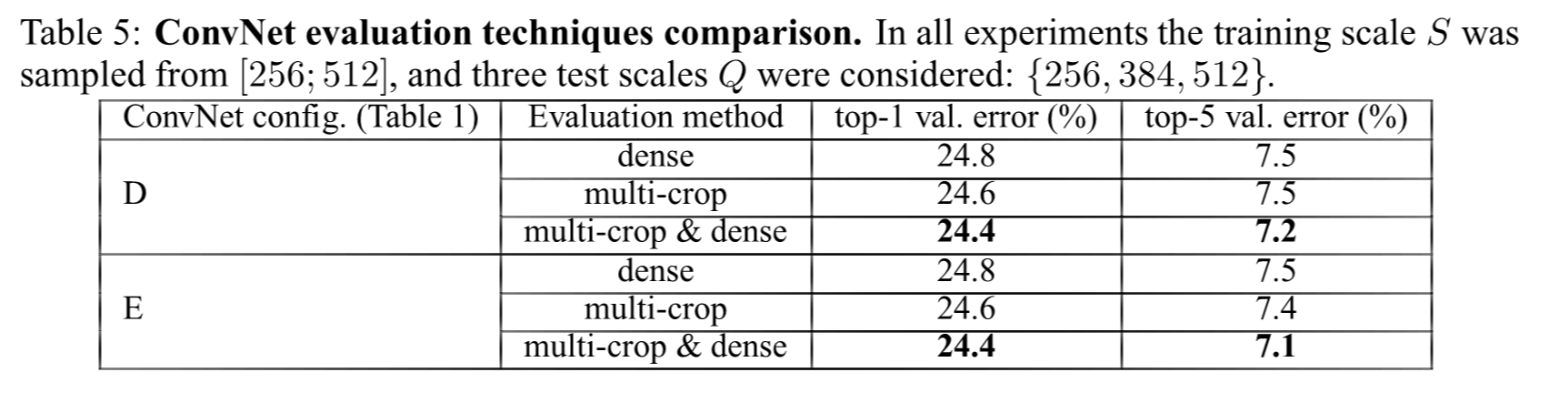
- dense evaluation과 multi-crop evaluaion을 비교
- 둘을 조합하면 더 성능이 좋음
Convnet fusion
- 모델 7개를 결합한 앙상블을 이용
- 앙상블을 이용해 ILSVRC에 제출한 것은 top-5 error가 7.5%
- 추후에 모델 2개를 앙상블하여 top-5 error를 6.8%까지 낮춤
Comparison with the state of the art


- 당시 GoogLeNet는 error 6.7%로 1등, VGG(ILSVRC 제출)는 error 7.3%로 2등
- GoogLeNet보다 VGG가 더 단순하고 효과적
5. Conclusion
- 작은 filter size 사용(3 x 3 filter, stride 1)
- 최대 depth를 19층까지 쌓아서 좋은 성능을 보임



