
기존 td learning은 다음 스텝에 보상까지만 본 on-policy알고리즘이었다.
여기서 n-step은 결론적으로 n-step까지에 보상을 본 on-policy알고리즘이라고 할 수 있을 것이다
2-step td learning일때 식을 의미하게 된다.
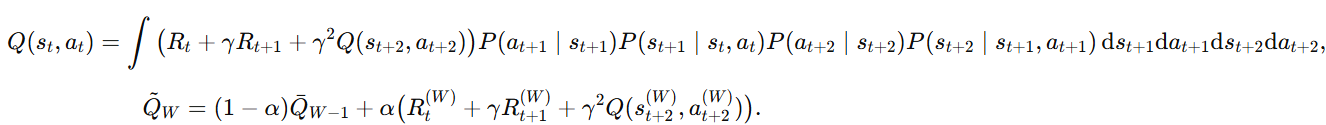
반면에 q-learning은 이와 비슷하지만 off-policy알고리즘이기 때문에 behaivor policy와 target policy가 다르게 된다.
따라서 behavior policy와 target policy를 다르게 생각해서 sampling을 해줘야한다.
behavior policy를 q라고 두고 target policy를 p라고 두고 importance sampling을 해준다면 2-step q learning은 다음과 같이 변하게 된다.

위에 Q-function 식에서 q로 나눠주고 곱해주는 importance sampling을 할시에 다음과 같이 나타나게 된다.
n-step이라고 하면 2-step과 마찬가지로 확장하면 된다.
'Miscellaneous' 카테고리의 다른 글
| [2025-1] 노하림 - PER: Prioritized Experience Replay (0) | 2025.01.19 |
|---|---|
| [2025-1] 정지우 - Q-learning (심화편) [혁펜하임 강화학습 4-2강 정리] (0) | 2025.01.12 |
| [2025-1] 박제우 - Anomaly Detection in IoT Sensor Energy Consumption Using LSTM Neural Networks and Isolation Forest (1) | 2025.01.11 |
| [2025-1] 김학선 - On-policy vs Off-policy (0) | 2025.01.08 |
| [2025-1] 노하림 - 상태 가치 함수 V & 행동 가치 함수 Q & Optimal policy (0) | 2025.01.07 |

