

R-CNN
R-CNN은 먼저 Selective Search 를 통해 이미지에서 물체가 있을 법한 약 2천 개의 영역을 제안합니다. 각 영역을 Crop한 후 고정된 사이즈로 변환하여 CNN에 입력할 수 있도록 준비하며, 이를 통해 고정된 길이의 Feature 벡터를 추출합니다. 이렇게 추출된 벡터를 기반으로 SVM을 사용해 Classification을 수행하고, Regression을 통해 박스 위치를 조정합니다. 하지만 제안된 모든 영역에 대해 CNN을 반복 수행해야 하므로 속도가 매우 느리며, 이러한 단점은 이후 Fast R-CNN에서 개선됩니다.

Fast R-CNN
Fast R-CNN은 R-CNN의 단점인 느린 속도를 개선한 모델로, Selective Search로 영역을 제안하는 점은 동일하지만, 주요 차이점은 CNN을 한 번만 수행한다는 것입니다. 기존 R-CNN에서는 제안된 2천 개의 영역을 각각 Crop & Resize하여 CNN에 입력했지만, Fast R-CNN은 원본 이미지에서 Feature Map을 먼저 생성한 뒤, RoI Projection을 통해 제안된 영역을 Feature Map 단에서 추출합니다. 이는 CNN이 Translation equivariant 성질을 가지기 때문에 가능하며, 입력 이미지마다 단 한 번의 CNN 수행으로 속도를 크게 개선합니다. 이렇게 생성된 Feature Map에서 각 영역을 투영한 후, RoI Pooling을 통해 고정 크기의 벡터로 변환합니다.
RoI Pooling은 기존의 Crop & Resize 방식을 대체하여, 가변 크기의 Feature Map 영역을 고정 크기의 벡터로 변환하는 과정입니다. 예를 들어, 5x4, 5x2, 4x3 크기의 영역을 Max Pooling 기법으로 2x2 크기로 변환하여 FC Layer로 입력할 수 있도록 만듭니다. 이를 통해 각 영역에 대해 고정된 길이의 벡터를 생성하고, FC Layer를 통과시켜 Classification과 Regression을 수행합니다. Fast R-CNN은 이러한 방식을 통해 기존 R-CNN 대비 속도와 효율성을 대폭 향상시켰습니다.
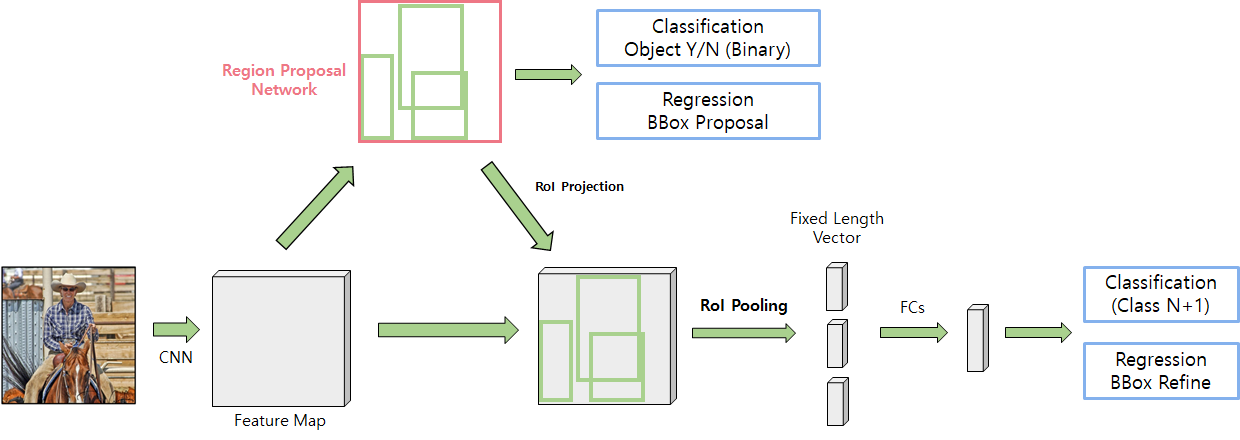
Faster R-CNN
Faster R-CNN은 Fast R-CNN에서 Selective Search로 인한 CPU 병목 문제를 해결하기 위해 Region Proposal도 CNN 내부에서 수행하는 Region Proposal Network(RPN)를 도입한 모델입니다. 입력 이미지를 CNN에 통과시켜 Feature Map을 생성한 후, 해당 Feature Map을 RPN의 입력으로 사용하여 제안된 영역(Anchor Box)을 생성합니다. 이렇게 생성된 영역을 Feature Map에서 추출하여 RoI Pooling을 수행하고, FC Layer를 통해 Classification과 Regression을 수행합니다. RPN은 GPU에서 동작하며 전체 네트워크에 통합된 End-to-End 구조로, 속도와 효율성이 크게 향상되었습니다.
RPN은 입력 Feature Map에 대해 3x3 크기의 Sliding Window 방식을 사용하며, 각 Grid 위치에서 9개의 Anchor Box(다양한 크기와 비율)로 영역을 정의합니다. Feature Map(Channel, Height, Width)을 3x3 Conv로 처리해 (256, Height, Width) 크기로 변환한 뒤, 1x1 Conv를 사용해 물체 존재 여부(2x9=18채널)와 Bounding Box 좌표(4x9=36채널)를 각각 예측합니다. 이를 통해 각 Grid에서 9개의 Anchor에 대한 Class와 좌표를 동시에 예측하며, GT Box와의 차이를 Regression으로 보정하여 최종 영역을 생성합니다. RPN의 CNN 기반 구조는 다양한 크기의 Box를 빠르게 제안할 수 있는 핵심 요소로 작용합니다.
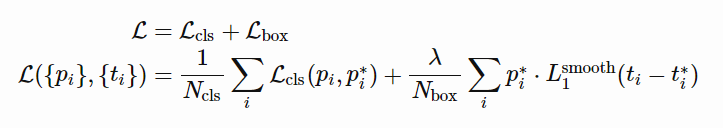
Loss Function
Faster R-CNN의 Loss 함수는 Multi-task Loss를 사용하며, Classification에는 Cross Entropy Loss를, Regression에는 Smooth L1 Loss를 적용합니다. RPN에서는 Anchor Box와 GT Box의 Intersection over Union(IOU) 기준으로 Positive와 Negative Samples를 선정해 학습 데이터셋을 구성합니다. Positive Sample은 IOU가 0.7 이상인 Anchor로 정의하며, Negative Sample은 IOU가 0.3 이하인 Anchor를 선택합니다. Positive Sample에는 Class Label과 BBox Regression 값을 포함하고, Negative Sample은 배경으로만 처리하며 학습에 사용되지 않는 중립 영역(IOU 0.3~0.7)은 제외됩니다.
Anchor Box는 Feature Map의 Grid Cell에서 다양한 크기와 비율의 Box를 생성하여 RPN 입력으로 사용됩니다. Anchor는 GT Box와의 차이를 Regression으로 학습하며, 각 Batch는 Anchor 사용 여부, 객체 여부, BBox Regression 값, Class Label 정보로 구성됩니다. 이를 통해 Faster R-CNN은 GPU 기반의 End-to-End 구조에서 효율적인 학습이 가능합니다.
'CV' 카테고리의 다른 글
| [2024-2] 조환희 - YOLO, SSD (1) | 2024.12.20 |
|---|---|
| [2024-2] 박지원- SENet(Squeeze-and-Excitation Networks) (0) | 2024.12.19 |
| [2024-2] 박서형 - SqueezeNet, ShuffleNet (1) | 2024.12.14 |
| [2024-2] 유경석 - Optimizer의 종류와 특성 (0) | 2024.12.13 |
| [2024 - 2] 김동규 - MobileNet: Efficient Convolutional Neural Networks for Mobile Vision Application (1) | 2024.12.08 |



