
LeNet의 들어가기에 앞서서 LeNet은 CNN의 개념을 제시하고 현대 CNN 모델들의 기초가 되는 모델입니다.
1. Introduction
해당 논문의 주요 메시지는 " 패턴인식 시스템은 hand-designed heuristics를 줄이고 자동화 학습에 주력해서 만드는 것이 더 좋은 성능을 가진다"
Introduction에서는 두 가지 케이스를 제시합니다.
첫 번째는 character recognition, 두 번째는 document understading입니다.
character recognition의 경우 독립된 하나의 글자를 인식하는 문제입니다. 이러한 문제는 픽셀 이미지에 직접 동작하는 머신을 사용하는 것이 효과적이며 저희가 알고 있는 CNN을 의미합니다.
document understadin은 여러 개의 글자가 모인 문장, 여러 문장이 모인 문서를 이해하는 과정입니다. 이런 문제는 디자인 패러다임을 사용하는 것이 효과적인데 Graph Transformer Networks를 의미합니다.

기존의 패턴 인식 체계는 위 그림과 감이 automatic learning technique과 hand-crafted algorithm의 조합으로 구성됩니다.
- feature extractor: 입력 패턴을 저 차원의 벡터나 변환하는 역할을 합니다. 이러한 변환된 형태는 쉽게 매칭되거나 비교되고, 입력의 패턴의 변화나 왜곡에도 변하지 않는 특징을 갖도록 설계됩니다. 이런 이유로 사람에 의해 인위적으로 설계된(hand crafted) 특징 추출 알고리즘은 사전 지식이 어느 정도 필요하며 task별로 특정됩니다.
- classifier: 분류기는 주로 범용적으로 설계되며 학습 가능한 구조로 이루어집니다. 분류기는 다양한 문제에 적용 가능하고, 데이터를 기반으로 학습하여 성능을 향상시킬 수 있는 모델입니다.
이러한 구조에서 발생할 수 있는 문제접은 인식의 성능이 feature extractor를 설계하는 것에 의해서 성능이 좌우되고, 매번 다른 task에 새로운 feature extracotr를 설계하기 때문에 어렵고 시간이 많이 들게 됩니다.
feature extractor을 굳이 사용해야만 했던 이유는 당시 classifier가 저차원의 공간에만 제한되어 있었기 때문입니다.
하지만, 세 가지 요소의 결합으로 인해 이러한 관점이 변화했습니다.
- 저렴해진 컴퓨터 가격과 성능의 향상으로 알고리즘을 개선시키는 것이 아닌 무작정 계산하는 방법이 가능해졌습니다.
- 빅데이터가 생겨남에 있어서 hand-crafted feature extraction보다는 실제에 가까운 데이터셋을 얻을 수 있습니다.
- 높은 차원을 다룰 수 있는 강력한 머신러닝 알고리즘이 나와 복잡한 결정을 내릴 수 있습니다.
A.Learning from Data
Neural network에서 유명한 접근 방법으로 gradient-based learning이 있습니다.
learning machine은 다음 함수를 계산합니다.

여기서 Z^p는 p번째 입력 패턴이고, W는 파라미터 또는 가중치입니다. 함수의 출력 Y^p는 패턴 Z^p에 대한 예측한 class의 label이거나 각각의 class에 관련된 확률 또는 점수입니다.

위 손실함수에서 D^p는 p번째 패턴의 실제 정답 label을 의미하고 실제 위의 함수로부터 나온 값 Y^p 사이의 오차를 계산합니다. 다음 average loss function은 {(Z^1, D^1),..., (Z^p, D^p)}까지의 평균 오차를 의미합니다.

학습 과정에서 E_train(W)를 가장 작게 만드는 W값을 찾아야 합니다. 하지만 실제로 중요한 것은 train data가 아닌 test data에 대해서 오차를 줄여야 합니다.

다른 연구에 따르면 예상되는 E_test와 E_train의 관계는 위의 식에 근저한다고 합니다. 여기서 P는 train data의 크기를 의미합니다. h는 machine의 복잡도를 의미합니다. α는 0.5와 1.0 사이의 수이고 k는 상수입니다. 즉, train_data의 크기가 커지고 machine이 단순해진다면 train data의 크기가 커지고 machine이 단순해진다면 train data에서의 오차와 test data에서의 오차의 차이가 줄어든다는 의미입니다. 그리고, h가 증가하면 E_train은 감소합니다. 그렇기 때문에 h가 증가하면 E_train은 감소하고 E_test와 E_train 사이의 차이는 증가합니다. 대부분의 학습 알고리즘은 E_test와 E_train의 차이를 보면서 E_train을 최소화시키는 방법을 시도합니다. 이를 structural risk minimization이라고 합니다.
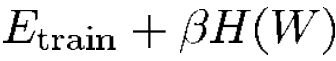
실제로는 위와 같은 방식으로 최소화하는 방향을 학습합니다. 여기서 H(W)는 규제화 함수이고 β는 상수입니다. H(W)는 매개변수 공간에서 고용량의 부분집합을 취하도록 선택됩니다. 그렇기 때문에 H(W)를 최소화하는 것은 매개변수 공간의 접근 가능한 부분집합이 제한되는 것이므로 E_train을 최소화하는 것과 E_test와 E_train 간의 차이를 최소화하는 것 사이의 trade-off를 제한하는 것입니다.
B. Gradient-Based Learning
손실 함수는 손실함수에서 매개 변수 값의 작은 변화의 영향을 측정하는 것으로 쉽게 최소화가 됩니다. 이런 측정은 손실 함수의 현재 매개변수에서의 기울기를 이용합니다. 효율적인 학습 알고리즘은 기울기 벡터가 수적이 아닌 분석적으로 구해질 때 고안될 수 있다고 합니다.
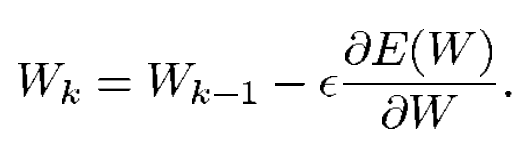
손실 함수의 값을 최소화하기 위해 기울기 ∇θ 이용하는 방법입니다. W는 실수의 매개변수 집합입니다. 손실 함수 E(W)는 연속적이고 미분 가능합니다. ε는 스칼라 상수입니다.
보다 정교한 과정을 위해서 ε를 변수로 두거나, 대각 행렬로 두거나 역행렬을 사용할 수 있습니다.

대중적으로 사용되는 최소화 방법 중하나는 확률적 경사 하강법(stochastic gradient algorithm)으로 online update라고도 불립니다. 이 방법은 평균 기울기의 노이즈가 포함된 버전 또는 근삿값을 사용하여 파라미터 벡터를 업데이트하는 방식으로 이루어집니다. 가장 일반적인 경우에는 단일 샘플을 기반으로 θ를 업데이트합니다. 해당 과정에서 파라미터 벡터가 평균적인 경로 주변에서 변동하지만, 일반적으로 대규모 학습 데이터셋에서 중복된 샘플이 많은 경우에는 일반적인 정규 경사 하강(regular gradient descent ) 보다 훨씬 더 빠르게 수렴합니다.
C. Gradient Back-Propagation
gradient-based learning 과정은 1950년대부터 소개되었지만 선형 시스템에 한정되어 사용되었습니다. 그러나 3가지 사건으로 머신러닝 과정에서도 gradient-based learning이 유용하다고 밝혀지게 됩니다.
- 첫 번째로 초기의 경고와는 달리 손실 함수에서 국소 최솟값(local minima)의 존재가 실제로는 주요 문제가 되지 않는다는 점이 확인되었스빈다. 이는 초기 비선형 기울기 기반 학습 기술이 성공을 거두는 데 국소 최소값이 큰 장애가 되지 않는 다는 점이 관찰되면서 명백해졌습니다.
- 두 번째로 다층 처리 구조를 갖는 비선형 시스템에서 기울기를 간단하고 효율적으로 계산하는 방법 역전파 알고리즘(back-propagation algorithm)이 대중화되었습니다.
- 세 번째로 sigmoid unit을 사용하는 다층 신경망에 역전파 절차를 적용하면 복잡한 학습 작업을 해결할 수 있다는 것 이 입증되었습니다.
역전파 알고리즘의 기본 아이디어는 1960 초반의 제어 이론 문헌에서 처음 기술 되었으나 당시에는 기계 학습에 일반적으로 적용되지 않았습니다. 그러나 역전파 알고리즘의 기본 아이디어를 통해서 출력에서 입력으로 기울기 미분값을 효율적으로 전파함으로써 계산할 수 있게 되었습니다. 역전파는 신경망 학습 알고리즘 중에서 가장 널리 사용되는 알고리즘이며, 아마도 모든 형태의 학습 알고리즘 중 가장 널리 사용되는 알고리즘입니다.
D. Learning in Real Handwriting Recognition Systems
당시 손글씨 인식에서 가장 성공적인 결과를 낸 것이 neural network입니다. 섹션 3에서 다른 방법들과 비교를 하겠지만 gradient-based learning 방법이 다른 모든 방법보다 좋았고 CNN라는 신경망이 이미지 데이터에서부터 바로 특징을 추출했습니다.
손글씨 인식에서 가장 어려운 부분 중 하나는 segmentation이라고 불리는 단어나 문장에서 각각의 글자를 분리하는 것입니다. 논문 작성 당시 표준이라고 불리는 방법은 Heuristic Over-Segmentation입니다. 경험적인 방법을 통한 이미지 처리 기술을 이용하여 가능성 있는 많은 경우의 글자 간 분리를 진행합니다. 그리고 인식 모델에 의해 후보들 중 가장 높은 점수를 내 조합을 채택합니다. 이러한 모델의 경우 경험적인 방법으로 자른 이미지의 품질과 인식 모델의 여러 후보들 중 적절하게 분리된 글자를 얼마나 잘 식별하는가에 따라서 성능이 갈리게 됩니다. 하지만 이는 부적절하게 분류되었다는 label을 갖는 데이터가 없기 때문에 인식 모델을 학습시키기 어렵게 됩니다. 가장 간단한 해결책은 세분화를 거친 이미지에 하나씩 직접 labeling을 하는 것인데 매우 비용이 많이 들고 어려운 작업입니다. 이에 본 논문의 Section V, VII에서는 GTN을 이용한 방법을 사용하긴 하는데 본 포스팅에서 다루지는 않을 예정입니다.
E. Globally Trainable Systems
실제 패턴 인식 시스템은 이전에 언급한 바와 같이 여러 모듈로 구성됩니다. 대개 인식 모델을 따로 학습시킨 다음 전체 모듈을 모아 성능을 향상하는 방식으로 매개변수를 조정하는데 이는 비용이 매우 많이 드는 작업입니다. 전반적인 에러를 최소화시키는 방향으로 시스템 전체를 학습시키게 된다면 보다 나은 방안이 될 수 있습니다.
gradient-based learning을 사용하게 되면 미분 가능한 손실함수 E, 학습 가능한 W에 대한 E의 국소 최솟값을 계산할 수 있게 됩니다. 하지만 모델이 복잡해진다면 gradient-based learning을 적용시키기 어려워 보입니다.
시스템 전체의 손실함수 E^p가 미분가능함을 보장하기 위해 미분 가능한 모듈들의 순방향 네트워크로 전반적인 시스템을 구성했습니다. 각각의 모듈에 의해 구현된 함수들은 연속이고 대부분의 경우에서 미분 가능해야 합니다. 위를 만족할 경우, 역전파 절차의 일반화를 사용하여 시스템 내의 모든 매개변수에 대해 기울기를 효율적으로 계산할 수 있게 됩니다.
시스템이 다음 함수를 구현하는 모듈들로 구성되어 있다고 가정해 봅니다.

X_n은 모듈의 출력을 의미하는 벡터이고, W_n은 학습 가능한 모듈의 매개변수입니다. X_(n-1)은 이전 모듈의 출력입니다. X_0는 모델의 첫 입력이며 입력 패턴인 Z^p와 같습니다. 시스템 전체의 손실함수 E^p를 각각 W_n, X_(n-1)에 대해 편미분 한 것은 다음과 같습니다.
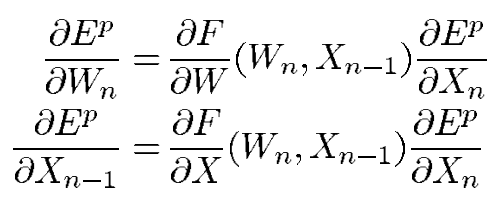
첫 번째 수식은 E^p(W)의 일부 항의 기울기를 계산합니다. 두 번째 수식은 역전파 과정입니다. 위 수식은 편도 함수의 벡터로 구성된 야코 비안의 곱을 사용합니다.
2. CONVOLUTIONAL NEURAL NETWORKS FOR ISOLATED CHARACTER RECOGNITION
전통적인 패턴 인식 시스템은 hand-designed feature extractor와 trainable classifier로 구성됩니다. Trainable classifier를 완전 연결 다층 신경망으로 사용 가능합니다. feature extractor로 완전 연결 다층 신경망을 사용하는 것이 효과적이긴 했으나 다음과 같은 문제점이 발생했습니다.
우선, 보통의 이미지는 크기가 크기 때문에 많은 매개변수들이 필요로 하고, 많은 매개변수를 학습시키기 위해 더 많은 데이터를 요구하게 됩니다. 또한, 메모리를 많이 사용하게 됩니다. 가낭 큰 결점은 입력데이터에 약간의 왜곡만 취해져도 다른 데이터라고 인식하는 것입니다.
다음으로, 다층 신경망은 입력의 네트워크 구조를 무시합니ㅏㄷ. 이미지의 경우 인접한 픽셀이 상당히 깊은 연관성을 갖고 있습니다. 후술 할 CNN은 이러한 문제점을 해결해 줍니다.
A. Convolutional Networks
합성곱 신경망(Convoultional Neural Network)은 약간의 이동, 크기, 왜곡 불변성을 어느 정도 보장하기 위해 세 가지 구조적 아이디어를 결합합니다. 국소 수용 영역(local receptive fields), 공유 가중치( weight replication), 공간적 또는 시간적 샘플링 감소( subsampling) 3가지 아이디어를 조합했습니다.
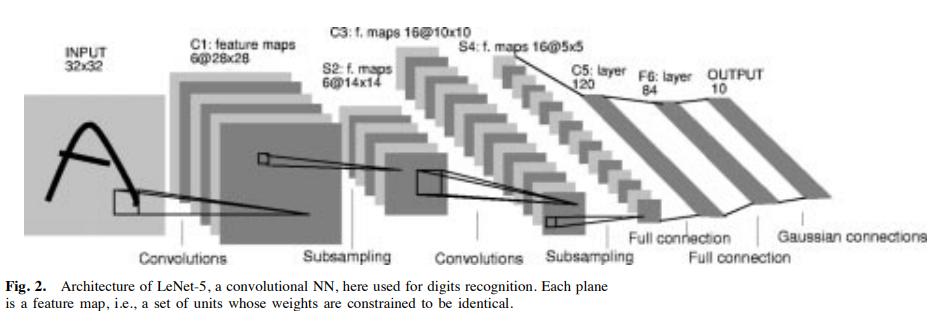
LeNet-5라는 전형적인 문자 인식용 컨볼루션 네트워크는 위의 그림과 같습니다.
입력 크기는 크기 정규화 및 중심화된 문자 이미지를 받습니다. 각 층의 단위는 이전 층에서 이웃 영역에 위치한 단위들로부터 입력을 받습니다. 입력에 대한 국소 수용 영역에 단위들을 연결하는 아이디어는 퍼셉트론으로 거슬러 올라가며, 고양이의 시각 시스템에서 국소적으로 민감한 방향 선택적인 뉴런을 발견한 것과 거의 동시에 이루어졌습니다. 국소 연결(local connections)은 시각 학습에 대한 신경망 모델에서 여러 번 사용되었습니다. 국소 수용 영역을 사용하면 뉴런은 기본적인 시각적 특징을 추출합니다. 이러한 특징들은 이후 층에서 결합되어 더 높은 차원의 특징을 감지하게 됩니다.
입력의 왜곡이나 이동으로 인해 중요한 특징의 위치가 바뀔 수 있습니다. 또한, 이미지의 한 부분에서 유용한 기본적인 특징 탐지기는 이미지 전체에서 유용할 가능성이 높습니다. 이 정보는 각각 다른 위치에 있는 수용 영역을 가진 단위들이 동일한 가중치 벡터를 가지도록 강제하는 방식으로 적용될 수 있습니다. 이 방식은 특징 맵이라는 출력 집합을 만듭니다.
LeNet-5의 첫 번째 숨겨진 층에서는 여섯 개의 특징 맵이 조직되어 있으며, 각 단위는 입력의 5x5 영역에 연결된 25개의 입력을 가집니다. 각 단위는 25개의 학습 가능한 계수와 학습 가능한 바이어스를 가지고 있습니다. 이 단위들은 동일한 가중치와 바이어스를 공유하며 이미지의 모든 위치에서 동일한 특징을 감지합니다. 다른 특징 맵은 다른 가중치와 바이어스를 사용하여 다른 유형의 특징을 추출합니다. LeNet-5의 첫 번째 숨겨진 층에 각 입력 위치에서 6가지 다른 유형의 특징이 추출됩니다.
특징 맵의 순차적 구현은 입력 이미지를 스캔하는 단일 단위로, 각 위치에서 해당 단위의 상태를 특징 맵에 저장하는 방식으로 이루어집니다. 이 연산은 합성곱(convolution), 그 후 가산 바이어스(additive bias)와 비압축 함수(squashing function)를 거치게 되며, 이 때문에 이 네트우커느는 합성곱 신경망이라고 불립니다. 합성곱 층의 흥미로운 속성은 입력 이미지가 이동하면 특징 맵 출력도 동일하게 이동하지만 그렇지 않으면 변하지 않는다는 점입니다. 이 속성 덕분에 컨볼루션 네트워크는 입력의 이동 및 왜곡에 대한 강건성을 가집니다.
특징이 감지된 후, 그 정확한 위치는 덜 중요해집니다. 그 대신 다른 특징들과의 상대적인 위치가 중요합니다. 각 특징의 정확한 위치는 중요하지 않으며, 오히려 위치의 변화는 문자를 인식하는 데 악영향을 끼칠 수 있습니다. 이러한 특징들이 얼마나 정확하게 인코딩 되는지의 정밀도를 줄이기 위한 방법은 특징 맵의 공간적 해상도를 줄이는 것입니다. 이는 샘플링 감소(layer subsampling)를 통해 달성될 수 있으며, 이 방식은 특징 맵의 해상도를 줄이고 이동과 왜곡에 대한 민감도를 감소시킵니다. LeNet-5의 두 번째 숨겨진 층은 샘플링 감소 층입니다. 이 층은 이전 층의 각 특징 맵에 대해 하나씩 6개의 특징 맵을 포함하고 있습니다.
연속적인 합성곱과 샘플링 감소 층이 번갈아 배치되면 모델은 이중 피라미드(bipyramid) 구조를 형성합니다. 각 층에서 특징 맵의 수가 증가하며, 공간적 해상도는 감소합니다. 각 단위는 이전 층의 여러 특징맵으로부터 입력 연결을 받을 수 있습니다. 이러한 점진적인 공간 해상도 감소와 표현의 풍부함은 기하학적 변환에 대한 높은 불변성을 달성하게 합니다.
모든 가중치가 역전파로 학습되기 때문에, 합성곱은 자체적으로 특징 추출기를 합성하는 것으로 볼 수 있습니다. 가중치 공유 기법은 자유 매개변수의 수를 줄여 모델의 용량을 줄이며, 훈련 오차와 테스트 오차간의 차이를 줄이는 효과가 있습니다.
B. LeNet-5
LeNet-5는 CNN으로 입력을 제외한 7개의 층으로 구성되며, 모든 층에는 학습 가능한 가중치가 포함됩니다. 입력은 32x32 픽셀 이미지입니다. 이는 데이터셋에서 가장 큰 문자 크기보다 훨씬 큽니다. 그 이유는 획 끝이나 코너와 같은 특징들이 최고의 성능의 특징 탐지기의 수용 필드 중심에 나타날 수 있도록 하는 것이 바람직하기 때문입니다. LeNet-5에서 마지막 합성곱 층의 수용필드 중심들은 32x32 입력 이미지의 중앙에 20x20 영역을 형성합니다. 입력 픽셀의 값은 흰색은 0으로, 검은색은 1.175로 정규화되어 있습니다. 이는 입력의 평균을 대략 0으로, 분산을 대략 1로 맞춰 학습을 가속화합니다.
LeNet의 C1 층은 6개의 특징 맵을 컨볼루션 층입니다. 각 단위는 5x5 크기의 지역에 연결됩니다. 특징 맵의 크기는 28x28로 입력의 경계에서 연결이 떨어지지 않도록 합니다. 첫 번째 층은 156개의 학습 가능한 파라미터를 가집니다.
LeNet의 S2 층은 6개의 특징 맵을 가지는 샘플링 입니다. 각 단위는 C1의 대응하는 특징 맵에서 2x2 크기의 지역에 연결됩니다. 네 개의 입력을 더한 후 학습 가능한 계수로 곱하고 학습 가능한 바이어스를 더한 후 시그모이드(sigmoid) 활성화 함수를 통과시킵니다. 이 레이너는 12개의 학습가능한 파라미터를 가집니다.
LeNet의 C3 층은 16개의 특징 맵을 가지는 합성곱 층입니다. 각 단위는 S2의 여러 5x5 지역에 연결됩니다. S2의 모든 특징 맵을 C3의 모든 특징 맵에 연결하지 않는 이유는 두 가지입니다. 첫째, 불완전한 연결 방식을 사용하여 연결 수를 합리적인 범위로 제한합니다. 둘째, 대칭성을 깨는 방식으로 서로 다른 특징 맵들이 서로 다른 특징을 추출하도록 강제합니다. C3는 1516개의 학습 가능한 파라미터를 가집니다.

S4 층은 16개의 특징 맵을 가지는 샘플링 층입니다. 각 단위는 C3의 대응하는 특징 맵에서 2x2크기의 지역에 연결됩니다. 이 층은 32개의 학습 가능한 파라미터를 가집니다.
C5 층은 120개의 특징 맵을 가지는 컨볼루션 층입니다. 각 단위는 C3의 모든 16개의 특징 맵에서 5x5 지역에 연결됩니다. 여기서, S4의 크기가 5x5이므로, C5의 특징 맵 크기는 1x1이 됩니다. 이는 S4와 C5의 완전 연결을 의미합니다. C5는 48,120개의 학습 가능한 파라미터를 가집니다.
F6 층은 84개의 단위를 가지는 완전 연결 층입니다. 이 층 C5와 완전 연결되며 10,164개의 학습 가능한 파라미터를 가집니다. F6 층까지의 모든 층은 가중치 벡터와 입력 벡터 간의 내적을 계산하고 바이어스를 더한 후 시그모이드 함수를 적용하여 단위의 상태를 출력합니다. 시그모이드 함수는 스케일 된 하이퍼 볼릭 탄젠트 함수로 다음과 같이 설명됩니다.
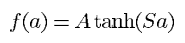
출력 층은 각 클래스에 대해 하나씩 존재하는 유클라디안 RBF 유닛으로 구성됩니다. 각 RBF 유닛은 84개의 입력을 받으며 RBF 출력은 입력 벡터와 해당 유닛의 파라미터 벡터 간의 유클라디안 거리를 계산하여 나옵니다. 아래 식을 이용해 각각의 RBF의 출력 y_i를 구할 수 있게 됩니다.

입력이 파라미터 벡터와 멀어질수록 RBF 출력은 더 커집니다. 이 출력 값은 패턴과 클래스 모델 간의 적합도를 나타내며 확률적 관점에서는 입력 패턴에 대해 클래스의 가우시안 부포의 비정규화된 음의 로그 우도로 해석될 수 있습니다.
RBF 유닛의 파라미터 벡터는 F6 의 타겟 벡터 역할을 하며 그 구성 요소는 1 또는 -1로 설정됩니다. 이는 F6의 시그모이드가 포화되는 것을 방지하는 데 도움이 됩니다. 시그모이드가 포화되면 학습속도가 느려집니다. 1과 -1은 시그모이드의 최대 비선형 범위에 해당하는 값으로 이를 통해 F6 유닛이 가장 비선형적인 상태에서 동작하게 만듭니다.
RBF 유닛의 출력은 해석적 코드로 비슷한 형태의 문자들을 유사한 출력 코드로 매핑하여 문자 인식에서의 혼동을 줄이는 데 유용합니다. 혼동될 수 있는 문자들이 유사한 출력을 가질 수 있습니다. 시스템이 모호한 문자를 적절히 해석하도록 도와줍니다.
C. Loss Function
LeNet-5에 사용하기 좋은 가장 간단한 손실 함수는 MSE에 해당하는 MLE(Maximum Likelihood Estimation)입니다. 식은 아래와 같습니다.
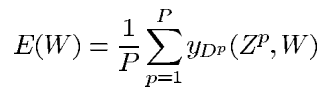
y_(D_p)는 D_p번째 PBF 유닛의 출력입니다. 대부분의 경우에 잘 맞은 손실 함수이지만 결점이 있습니다.
- 첫 번째로 PBF의 매개변수들을 학습시키면 E(W)가 매우 작아지나, RBF의 모든 매개변수 벡터는 동일하기 때문에 결국 모델의 입력은 무시한 채 모든 RBF의 출력이 0이 되게 됩니다. 이는 매우 단순하지만 허용할 수 없는 해입니다. 하지만 RBF 가중치가 학습되지 않으면 이러한 현상은 발생하지 않습니다.
- 두 번째로 클래스 간의 경쟁이 없다는 것입니다. MAP(Maximum a Posteriori)를 사용하면 경쟁을 시킬 수는 있습니다. MAP는 정답 클래스에 대한 사후 확률을 최대화하는 방식입니다. 즉, 틀린 정답에는 큰 패널티를, 맞은 정답엔 낮은 패널티를 적용합니다. 이 추가적인 규제 항은 경쟁 역할을 하며 첫째항보다는 작거나 같아야 합니다. 상수 j는 양수이며 이미 매우 큰 클래스의 패널티가 더 이상 추가되는 것을 방지합니다.
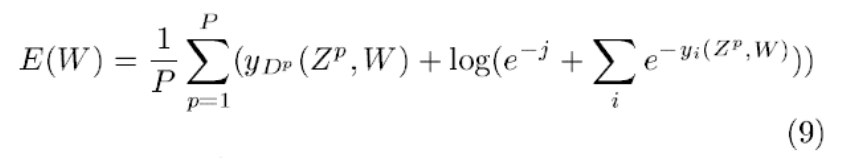
다음 링크는 pytorch로 구현된 LeNet5 코드입니다. Link
pytorch-implementation/1.LeNet5.ipynb at main · JJuOn/pytorch-implementation
Contribute to JJuOn/pytorch-implementation development by creating an account on GitHub.
github.com
다음 링크는 tensorflow로 구현된 LeNet5 코드입니다. Link
[code] LeNet-5
code
chaelin0722.github.io



