
https://arxiv.org/abs/2010.00711
Abstract
- 최근 몇 년간 state-of-the-art 모델의 품질이 크게 향상되었지만, 해석 가능성이 감소했다.
- 2020년 기준 자연어 처리(NLP) 분야에서의 설명 가능한 인공지능(Explainable AI, XAI)의 상태를 다룬다.
- 모델 개발자를 위한 NLP 모델 예측에 대한 설명을 생성하는 데 사용할 수 있는 작업과 기술을 자세히 설명한다.
- 마지막으로 현재 부족한 점을 지적하고 향후 연구 방향을 제시한다.
Introduction
- 기존의 NLP 시스템은 규칙(rules), 의사결정 트리(decision trees), 히든 마르코브 모델(hidden Markov models), 로지스틱 회귀(logistic regressions) 등 ‘화이트 박스’ 모델을 기반으로 했다. 하지만 최근 딥러닝 모델과 언어 임베딩을 사용한 ‘블랙 박스’ 모델이 인기를 끌면서 모델의 해석 가능성이 떨어졌다.
- 모델이 결과에 도달하는 과정을 투명하게 알 수 없으면 챗봇, 추천 시스템, 정보 검색 알고리즘 등 매일 사용하는 AI 시스템에 대한 신뢰가 약화되는 문제가 될 수 있다.
- 설명가능성의 중요성에 대한 이해가 높아지면서 XAI 분야가 부상했다. 이 논문은 NLP 분야에서의 XAI 연구를 다룬다. 따라서 지난 7년간 주요 NLP 컨퍼런스에 나타난 NLP 분야의 XAI 작업에 초점을 맞추었다.
3 Categorization of Expalanations
- 설명은 두 가지 측면에서 분류된다:
- 개별 예측에 대한 설명(로컬, Local) 또는 모델의 예측 과정 전체에 대한 설명(글로벌, Global)
- 예측 과정에서 모델 자체가 직접 생성하는 설명(자체 설명, Self-Explaining) 또는 예측 후 추가 처리로 생성하는 설명(사후 설명, Post-Hoc)
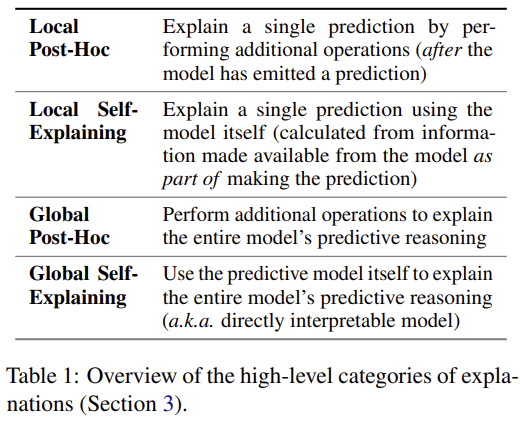
3.1 Local vs Global
- 로컬 설명(Local explanation)
- 특정 입력에 대한 모델의 예측에 대한 정보를 제공한다.
- 이 조사에서 50개의 논문 중 46개가 해당된다.
- 글로벌 설명(Global explanation)
- 특정 입력과 무관하게 모델의 예측이 어떻게 작동하는지 전반적인 과정을 설명함으로써 정당성을 보여준다.
- 이 조사에서 4개의 논문이 해당된다. (이러한 수치 차이는 이 조사가 모델의 일반적인 과정을 이해하는 설명보다는 예측을 정당화하는 설명에 집중한다는 것을 보여준다.)
3.2 Self-Explaining vs Post-Hoc
- 자체 설명(Self-Explaining)
- 예측 과정의 정보를 사용하여 모델의 예측과 동시에 설명을 생성한다. 이 방식은 ‘직접 해석 가능하다’라고도 한다.
- 예: 의사결정 트리, 규칙 기반 모델 등
- 사후 설명(Post-Hoc)
- 예측 이후 추가 연산으로 설명을 생성한다.
- 예: LIME(Local Interpretable Model-agnostic Explanations) - 예측 후 대리 모델을 사용하여 설명을 생성한다.
4 Aspects of Explanations
- 설명 도출 기법과 사용자에게 제공하는 방식에 따라 설명을 나눈다.
- 설명 도출 기법
- AI 과학자, 엔지니어의 영역
- 모델 결과의 수학적 정당성에 초점
- 사용자에게 제공하는 방식 — 시각화
- UX 엔지니어의 영역
- 최종 사용자에게 가장 효과적으로 제시하는 방법에 초점
- 설명 도출 기법

- feature importance 기반 접근법과 대리 모델 기반 접근법이 자주 사용되었다.
4.1 Explainability Techniques
설명 도출 기술
- feature 중요도(Feature Importance)
- 모델이 최종 예측을 출력하기 위해 사용한 다양한 feature들의 중요도를 조사하여 설명을 도출한다.
- feature의 유형:
- feature 엔지니어링에서 얻은 manual features
- 단어/토큰 및 n-gram을 포함한 어휘(lexical) features
- feature importance 기반 설명을 가능하기 위해 널리 사용되는 두 가지 연산:
- Attention mechanism
- first-derivative saliency
- 대리 모델(Surrogate Model)
- 설명 가능한 대리 모델을 학습시켜 원래 모델의 예측을 설명한다.
- 장점: 로컬과 글로벌 설명 모두에 사용할 수 있다.
- 문제점: 학습된 대리 모델과 원본 모델은 예측 매커니즘이 완전히 다를 수 있다는 점에서 대리 모델 기반 접근법의 신뢰도에 우려가 제기될 수 있다.
- 예: LIME(Local Interpretable Model-agnostic Explanations)
- 설명 가능한 대리 모델을 학습시켜 원래 모델의 예측을 설명한다.
- 예제 기반(Example-Driven)
- 레이블이 지정된 데이터에서 입력 instance와 의미적으로 유사한 다른 instance를 제시하며 입력 instance의 예측을 설명한다.
- 사용 예:
- nearest neighbor 기반 접근법
- 텍스트 분류
- 질문 답변 (QA)
- 출처 기반(Provenance-Based)
- 예측 도출 과정의 일부 또는 전부를 단계별로 보여준다.
- 선언적 귀납법(Declarative Induction)
- 규칙, 트리, 프로그램과 같이 사람이 읽을 수 있는 표현으로 설명한다.
4.2 Operations to Enable Explainability
설명을 가능하게 하는 기본 연산(작업)
- 일차 도함수 중요도(First-Derivative Saliency)
- input에 대한 output의 부분 도함수를 계산하여 output에 대한 input의 기여도를 추정한다.
- 단어/토큰 수준의 feature에 대해 feature 중요도를 설명하는 데 사용할 수 있다.
- 레이어별 관련도 전파(Layer-Wise Relevance Propagation)
- NN의 중간 레이어의 feature에 관련도를 부여한다.
- fully connected 레이어, convolution 레이어, recurrent 레이어 등 대부분의 일반적인 NN 레이어에 사용할 수 있다.
- feature 중요도(Feature Importance), 예제 기반(Example-Driven) 설명에 사용되어 왔다.
- 입력 변형(Input Perturbations)
- 입력 데이터를 변형하여 설명 가능한 모델을 학습시키며 입력에 대한 출력을 설명할 수 있다.
- 대리 모델(Surrogate Model) 설명에 사용된다.
- 어텐션 메커니즘(Attention Mechanism)
- NN 모델이 어디에 집중하는지 시각화하여 설명을 도출한다.
- feature 중요도를 설명하기 위해서 attention 레이어를 사용해왔지만, attention 레이어가 제공하는 설명의 정도에 대해서는 아직 논란이 있다.
- LSTM 게이트 신호(LSTM Gating Signals)
- LSTM의 게이트 출력 정보를 사용하여 설명한다.
- 언어의 순차적 특성을 고려하여 recurrent 레이어, 특히 LSTM이 일반적이다. 출력을 설명하기 위해 LSTM 셀의 출력을 마이닝하는 것이 일반적이지만, 셀 내에서 생성되는 게이트의 출력에도 정보가 존재할 수 있다.
- feature 중요도(Feature Importance), 설명에 사용할 수 있다.
- LSTM의 게이트 출력 정보를 사용하여 설명한다.
- 설명 가능성 인지 아키텍처 설계(Explainability-Aware Architecture Design)
- 인간이 인식할 수 있는 구성 요소를 포함한 아키텍처를 설계한다.
- 대리 모델(Surrogate Model) 설명에 사용할 수 있다.
4.3 Visualization Techniques

시각화 기법
+) (e) raw example을 사용하여 예제 기반 접근법 설명
- 중요도(Saliency)
- 중요도 점수를 시각적으로 표시한다.
- (a) 입력-출력 단어 정렬 표시
- (b) 입력 텍스트의 단어 강조 표시
- 이 조사에서 다룬 논문 중 가장 많이 사용된 시각화 기법
- 원시 선언적 표현(Raw Declarative Representations)
- 규칙, 트리, 프로그램과 같은 형태로 설명을 표시한다.
- (c) (d) 논리 규칙, 트리, 프로그램 등 학습된 선언적 표현 (declarative representation)을 직접 제시
- 최종 사용자가 first-order logic rules 및 reasoning trees와 같은 특정 표현을 이해할 수 있다고 가정하므로 암묵적으로 전문 사용자를 대상으로 한다.
- 자연어 설명(Natural Language Explanation)
- 인간이 이해할 수 있는 자연어로 설명을 표현한다.
- 딥러닝 모델을 사용하거나 간단한 템플릿 기반 접근 방식을 사용하여 생성할 수 있다.
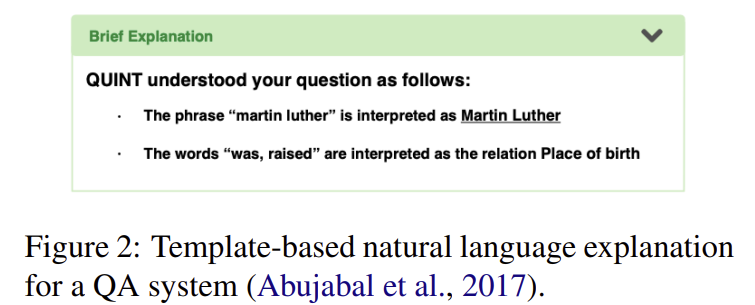
5 Explanation Quality
설명 품질
- XAI의 목표에 따라 모델의 품질은 정확도와 성능뿐만 아니라 예측에 대한 설명을 얼마나 잘 제공하는지에 따라 평가되어야한다.
- 설명 품질을 평가하기 위한 여러 방법이 있는데 주로 인간 평가를 포함한 다양한 평가 기법이 사용되며, 설명이 얼마나 잘 모델의 예측을 설명하는지를 평가한다.
5.1 Evaluation
평가 방법
이 분야의 역사가 짧기 때문에 설명의 평가 방법에 대한 합의가 거의 없다. 50개의 논문 중 32개에는 표준화된 평가가 없거나 비공식적인 평가만 포함되어 있다. 그 외 소수의 논문에서는 근거 데이터 활용(ground truth)과 인적 평가(human evaluation) 등 공식적인 평가 방법을 사용했다.

- 비공식적 평가(Informal Examination)
- 생성된 설명이 인간의 직관과 얼마나 잘 맞는지 평가한다.
- 실제 데이터와의 비교(Comparison to Ground Truth)
- 설명 가능성 기법의 성능을 정량화하기 위해 생성된 설명을 실제 데이터와 비교하여 성능을 평가한다.
- 사용되는 지표는 작업과 설명가능성 기법에 따라 다르지만 일반적으로 사용되는 지표는 다음과 같다:
- Precision/Recall/F1 score
- perplexity
- BLEU
- ground truth의 정확성을 보장하고 다른 유효한 설명이 있을 경우를 고려하며 데이터를 수집해야 한다.
- 인간 평가(Human Evaluation)
- 생성된 설명을 사람이 평가한다.
- 여러 사람이 참여하고 사람들 간에 합의하여 응답의 주관성과 편차를 올바르게 처리하는 것이 중요하다.
5.2 Predictive Process Coverage
예측 프로세스의 적용 범위
- 많은 설명 접근 방식이 예측 과정의 일부만 설명하며, 나머지는 사용자가 이해하도록 남겨둔다.
- 예: MathQA 모델 - 수학 문제 해결 과정은 단계별로 설명하지만, 모든 단계를 다루지는 않는다.
- 제공하는 설명의 최적의 범위는 설명 대상과 용도에 따라 달라질 수 있다.
6 Insights and Future Directions
- 최근 7년간 주요 NLP 학회에서 발표된 XAI 연구를 다루며 XAI 연구는 명화한 용어 정의와 평가 기준의 부족 등 등 여러 가지 과제가 있음을 알 수 있었다.
- 미래의 연구는 설명의 정확도(fidelity)와 원인(causality) 문제를 더 깊이 있게 다뤄야 하며, 인간 평가 기준을 확장하고 표준화된 평가 지표를 개발하는 것이 중요하다.
- 또한, 블랙 박스 모델의 설명에 집중하는 현재의 연구 경향에서 벗어나 화이트 박스 모델도 더 많이 연구할 필요가 있다.



