
https://arxiv.org/abs/2007.16100
Searching Efficient 3D Architectures with Sparse Point-Voxel Convolution
Self-driving cars need to understand 3D scenes efficiently and accurately in order to drive safely. Given the limited hardware resources, existing 3D perception models are not able to recognize small instances (e.g., pedestrians, cyclists) very well due to
arxiv.org
요약
이 리뷰는 SPVNAS (Sparse Point-Voxel Neural Architecture Search)에 관한 논문을 다룹니다. SPVNAS는 자율 주행 차량을 위한 효율적인 3D 인식 모델을 설계하고자 하는 목적을 가지고 있습니다. 이 논문에서는 고해상도 점 기반 분기를 포함한 경량 3D 모듈인 Sparse Point-Voxel Convolution (SPVConv)을 도입하며, 이를 통해 큰 야외 장면에서도 세밀한 디테일을 보존할 수 있습니다. 또한, 3D Neural Architecture Search (3D-NAS)를 사용하여 다양한 설계 공간에서 최적의 네트워크 아키텍처를 효율적으로 탐색합니다. 실험 결과, SPVNAS는 기존 최첨단 모델인 MinkowskiNet을 능가하며, SemanticKITTI 리더보드에서 1위를 차지했습니다.
1. 서론
자율 주행 자동차는 3D 장면을 효율적이고 정확하게 이해해야 안전하게 주행할 수 있습니다. 그러나 제한된 하드웨어 자원으로 인해 기존 3D 인식 모델은 낮은 해상도의 폭셀화와 공격적인 다운샘플링 때문에 작은 객체(예: 보행자, 자전거 이용자)를 잘 인식하지 못합니다. 이를 해결하기 위해 SPVConv를 제안합니다. 이 모듈은 높은 해상도의 점 기반 분기를 통해 세밀한 디테일을 보존하면서도 최소한의 오버헤드로 작동합니다. 또한, 3D-NAS를 사용하여 다양한 설계 공간에서 최적의 네트워크 아키텍처를 탐색합니다.
2. 관련 연구
- 3D 인식 모델: 초기 연구는 3D 데이터를 처리하기 위해 볼류메트릭 표현과 기본 3D 컨볼루션을 사용했습니다. 그러나 이러한 방법은 본질적으로 비효율적이며 정보 손실을 초래합니다. 이를 개선하기 위해 점 기반 컨볼루션과 대칭 함수를 사용하는 방법이 제안되었습니다.
- 신경망 아키텍처 탐색 (NAS): NAS는 강화 학습과 진화적 탐색을 사용하여 높은 정확도의 신경망을 자동으로 설계합니다. 최근 연구는 2D 시각 인식을 위해 효율적인 모델을 설계하는 데 중점을 두었지만, 3D 장면 이해를 위한 NAS는 아직 초기 단계에 있습니다.
3. SPVConv: 효과적인 3D 모듈 설계
SPVConv는 Sparse Convolution과 Point-Voxel Convolution의 단점을 극복하고자 설계되었습니다.
- Sparse Convolution의 문제점: 메모리 제약으로 인해 네트워크가 깊어질 수 없으며, 큰 수용 영역을 달성하기 위해 공격적인 다운샘플링이 필요합니다. 이는 정보 손실을 초래합니다.
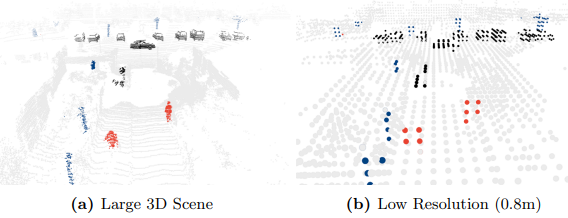
- Point-Voxel Convolution의 문제점: 큰 3D 장면을 처리할 때 작은 인스턴스(예: 보행자)는 몇 개의 폭셀 그리드에만 해당되어 유용한 정보를 학습하기 어렵습니다.
이를 해결하기 위해 SPVConv는 고해상도 점 기반 분기와 Sparse Voxel 기반 분기를 결합하여 큰 3D 장면에서도 세밀한 디테일을 캡처합니다.

4. 3D Neural Architecture Search (3D-NAS)
3D-NAS는 효율적인 3D 모델을 자동으로 설계하기 위해 다음과 같은 방법을 사용합니다.
- 디자인 공간: 세밀한 채널 수와 탄력적인 네트워크 깊이를 지원하여 다양한 아키텍처 후보를 탐색합니다.
- 학습 패러다임: 모든 후보 네트워크를 단일 슈퍼 네트워크에 포함시키고, 이를 한 번 학습한 후 각 후보 네트워크를 추출합니다. 이로 인해 학습 비용이 크게 줄어듭니다.
- 탐색 알고리즘: 진화적 아키텍처 탐색을 사용하여 주어진 자원 제약 하에서 최적의 아키텍처를 찾습니다.

5. 실험 결과
SPVNAS는 다양한 실험을 통해 우수한 성능을 입증했습니다.
- SemanticKITTI: SPVNAS는 mIoU 기준으로 MinkowskiNet보다 3.3% 높은 성능을 보였으며, 모델 크기와 계산 비용도 크게 줄였습니다.
- KITTI 객체 탐지: 자전거 이용자와 보행자 등 작은 객체에 대해 높은 정확도를 기록했습니다.
6. 분석
SPVNAS의 성공 요인은 다음과 같습니다.
- SPVConv: 작은 객체에 대한 높은 인식률을 보이며, 점 기반 분기가 작은 인스턴스에 더 많은 주의를 기울입니다.
- 3D-NAS: 효율적인 3D 모듈과 잘 설계된 네트워크 아키텍처가 결합되어 성능이 크게 향상되었습니다.
결론
SPVNAS는 자율 주행을 위한 3D 심층 학습 모델의 효율성과 성능을 크게 향상시킵니다. SPVConv와 3D-NAS를 통해 작은 객체 인식에서 뛰어난 성능을 발휘하며, 효율적인 3D 장면 이해를 위한 새로운 표준을 제시합니다.
논문 리뷰 정리 PPT :
https://blog.naver.com/kgh9080/223453470863
[논문리뷰] SPVNAS : Searching Efficient 3D Architectures with Sparse Point-Voxel Convolution
이렇게 3D 비교를 할 수 있습니다. Sparse Voxel Based Branch 는 위와 같습니다. 진행방식은 위와 같...
blog.naver.com



