
원본 논문 링크 : https://arxiv.org/abs/2403.05821
Optimizing LLM Queries in Relational Workloads
Analytical database providers (e.g., Redshift, Databricks, BigQuery) have rapidly added support for invoking Large Language Models (LLMs) through native user-defined functions (UDFs) to help users perform natural language tasks, such as classification, ent
arxiv.org
Abstract
- LLM은 굉장히 범용적으로 사용되고 있지만, LLM inference는 계산 및 경제적 측면 모두에서 비용이 많이 든다.
- 이 논문에서는 relational query들에서 LLM을 호출하는 analytical workload(?)에 대해 LLM inference를 최적화하는 방법을 제시한다.
- relational query가 KV 캐시를 최대로 사용하도록 하기 위해 행을 재정렬 하거나, 행 내에서 열을 재정렬한다. 또한 중복되는 query를 제거하거나 LLM을 불러오는 cost를 최소화 하는 방법을 이용하여 LLM inference를 가속화한다.
- Apache Spark과 vLLM을 사용했을 때, 실제 데이터세트에 대한 다양한 LLM 기반의 query benchmark에서 최대 4.4배의 end-to-end latency가 향상되었다.
1. Introduction
- 여러 분석 데이터베이스 공급업체는 이미 SQL API에 LLM 호출 기능을 추가했다.

- 그러나 위와 같은 방식으로 LLM을 실제 데이터셋에 적용하면 상당한 계산 및 경제적 비용이 발생한다. 실제 데이터셋은 수백만 개의 행을 포함할 수 있기 때문이다.
- LLM 호출 비용을 최소화하는 것이 LLM query 최적화의 주요 목표이다. LLM inference의 비용을 최적화하는 방법은 여러가지가 제시되었다.
- autoregressive 한 특성을 가진 모델은 각 request에 대해 순차적으로 LLM generation이 발생하므로 처리량을 향상시키기 위해 request가 일괄 처리된다.
- 일괄 처리에 포함된 각 request의 모든 계산 상태는 추론 중에 메모리에 저장되어야 하고 결과적으로 메모리 관리는 LLM 추론 성능에 중요한 요소이다.
- 특히 LLM inference 엔진은 과거의 프롬프트와 생성, 또는 request들의 prefix들에 대한 중간 상태(즉, encoding된 벡터 형태)를 메모리에 저장해둔다. 이 중간 상태들은 KV cache라고 불리며 저장이 된다.
- cache 내의 prefix의 재사용은 성능 향상에 큰 영향을 미치는 것으로 나타났다. 이에 따라 기존 inference 시스템은 KV cache의 hit rate를 대화하는 것을 목표로 한다.
- 그러나, 현재의 LLM inference 시스템은 온라인 workload를 제공하도록 디자인되어 있다. 즉, request가 도착했을 때 FIFO(First In, First Out)으로 request를 처리하고 이후의 request에 대해서 어떠한 가정도 하지 않는다. 결과적으로 관계형 분석에 있는 workload 정보를 통해 성능을 향상시킬 수 있는 기회를 놓치게 된다. 따라서 본 논문에서는 LLM query를 위한 inference를 최적화하는 문제를 다루며 end-to-end의 query latency를 줄이는 다양한 방법들을 소개한다.
- 관계형 분석 query를 최적화하기 위해 본 논문에서는 3가지 방법을 소개한다.
- prefix sharing maximization (PSM)
- 동적으로 입력 데이터의 행과 열을 재정렬하여 KV cache hit rate를 상당히 높인다.
- LLM으로 전송될 모든 request에 대한 oracular knowledge(?)을 통해 요청과 각 요청 내의 필드를 재정렬하여 cache hit rate를 늘릴 수 있다는 것이다.
- 예를 들어, 동일한 prefix(FIFO 순서에 따라 비연속적일 수 있음)를 공유하는 두 request는 후자의 request가cache hit가 발생할 수 있도록 동시에 제공되어야 한다.
- 마찬가지로 제품 이름 및 리뷰와 같은 데이터필드를 LLM에 입력하는 request에서는 shared prefix의 수를 최대화하도록 필드를 정렬해야 한다.
- 실제 데이터셋에는 데이터 열과 행 모두에 shared prefix가 많을 수 있으므로 request의 순서와 형식을 변경하여 KV cache hit rate를 크게 높일 수 있다.
- 그러나 쿼리에서 데이터의 열과 행을 정렬하는 방법은 매우 많기 때문에 최적의 request 순서와 형식을 찾는 것은 어렵다. 그래서 논문에는 heuristic한 솔루션을 제시한다.
- 본 논문에서는 열을 정렬하는 방법과 행을 sorting하는 방법을 각각 제시한다.
- 열을 재정렬할 때에는, 예상되는 cache 절감량을 기준으로 하여, 처리된 각 행 내의 필드를 재정렬하는 알고리즘을 제시한다. 여기에서의 알고리즘은 빈도와 사이즈를 기준으로 열 값의 점수를 매겨 전체 열 의 순서 우선순위를 결정한다.
- 행을 sorting할 때에는, cache reuse를 늘리기 위해 shared prefix 가 있는 request를 그룹화하는 최적화 방법을 제시한다.
- deduplication
- 실제 workload는 텍스트 데이터에 존재하는 많은 중복이 여러 번의 LLM 호출을 불러올 수 있다.
- 중복을 제거하면, 전체 쿼리의 정확성에 영향을 주지 않고 LLM 호출 수를 최소화할 수 있다.
- estimate LLM operator costs
- 쿼리 표현식 내에서 LLM operator cost를 추정하여 기존 데이터베이스 query 최적화 프로그램을 강화한다.
- LLM operator와 관련된 상당한 비용을 고려하여 전략적으로 operation을 재정렬하여 최적화할 수 있다.
- prefix sharing maximization (PSM)
- 본 논문에서는 백엔드를 제공하는 모델로 vLLM을 사용하여 Apache Spark에서 기술을 구현한다.
- 이 영역에는 표준 workload(?)가 부족 하다는 점을 고려하여 여러 실제 데이터셋에 대한 다양한 LLM query 벤치마크 제품군을 구축한다.
- 이 논문은 Amazon Product Review, Rotten Tomatoes Movie Dataset, Stanford Question Answering Dataset (SQuAD)을 포함하는 다양한 추천 및 질문 답변 데이터셋에 걸쳐 '동일한 query 내 multi-LLM 호출' 및 'RAG query'와 같은 광범위한 query 유형을 실험하였다.
- 저자들은 자신들의 기술이 1.5~4.4배의 성능 향상을 보였다고 말한다. query의 의미를 유지하면서 end-to-end query latency가 향상됨을 보였다.
- 요약하면 다음과 같다.
- 관계형 분석에서 LLM inference에 대한 KV cache hit rate를 향상시키기 위해 열 재정렬 알고리즘과 행 정렬 최적화를 적용하는 prefix sharing 최대화 접근 방식을 제시한다.
- SQL에서 LLM 호출 비용을 더욱 줄이기 위해 중복 제거 및 비용 추정 기술을 도입합니다.
- 다양한 검색 및 처리 작업을 나타내기 위해 real world 데이터를 사용하는 LLM query 벤치마크 데이터셋를 보여주었다.
- 우리는 vLLM과 Spark를 사용하여 최적화를 평가하고 최대 4.4배의 inference 속도 감소를 관찰했다. 즉, end-to-end query latency가 감소했다.
2. Background and Motivation
- 이 섹션에서는 inference 프로세스와 LLM 아키텍처의 주요 구성 요소, 그 중에서 KV cache에 대한 간략한 개요를 언급한다. 이는 이 논문을 이해하기 위한 사전지식이므로 간략하게만 언급하고 넘어가겠다.
- LLM inference
- autoregressive Transformer model, Byte-Paired Encoding(BPE), vLLM 등을 언급한다.
- KV cache
- 링크 참조
2.1 Optimization Opportunities in Analytics
- 이 논문에서 LLM inference 성능을 높이기 위해 3가지 측면을 개선하려 하였다.
- KV hit rate 높이기
- 온라인 설정을 위해 설계된 기존 LLM inference 엔진은 이후에 도착하는 요청들에 대해서는 가정하지 않고 query가 도착하는 대로 FIFO로 실행한다.
- 결과적으로 관계형 분석에 있는 workload 정보를 활용하여 cache hit rate를 향상시킬 수 있는 기회를 놓치게 된다.
- query 최적화 수준에서 우리는 각 request의 구조(예: 프롬프트 및 input 데이터)와 출력된 응답의 형식 / 길이에 대한 완전한 지식을 보유하고 있다.
- 이 정보는 cache hit rate를 최대화하기 위해 KV cache에 언제 prefix를 로드하고 제거해야 하는지 결정하는 데 사용될 수 있다.
- 예를 들어 FIFO 실행 시 prefix를 공유하는 두 개의 비연속 request는 둘 다 cache miss로 이어질 수 있다.
- 반대로, 이러한 request가 함께 제공되면, 후자가 cache hit를 발생시킬 수 있다.
- batch query에서는 모든 prefix를 알 수 있으므로 shared prefix를 그룹화하여 KV cache hit rate를 높일 수 있다.
- 즉, 토큰 적중률 또는 KV cache에서 제공할 수 있는 토큰의 비율을 최대화 하는 것이 목표이다.
- <본 논문에서의 접근 방식은 다음과 같다 : Data-Aware Caching and Request Scheduling.>
- workload 정보를 활용하여 KV cache hit rate를 향상시킨다.
- 특히, request끼리의 prefix sharing을 최대화하기 위해 요청 및 각 요청의 필드를 재정렬하는 알고리즘을 도입한다.
- cache reuse와 효율적인 메모리 사용을 가능하게 하기 위해 열의 관점에서, 그리고 행의 관점에서 모두재정렬을 해서 LLM에 대한 request의 순서를 변경한다.
- 중복 계산 방지하기
- 텍스트 데이터에 대해 LLM을 순진하게 호출하면 중복된 요청이 많이 발생할 수 있다.
- 구조화된 텍스트 데이터에는 중복된 항목이 포함되는 경우가 많다. query를 단순하게 실행하면 계산이 중복될 수 있다.
- 전체 latency를 줄이려면 동일한 response로 이어지는 이러한 request를 식별하고 필터링하여 LLM에 대한 호출 수를 최소화해야 한다.
- <본 논문에서의 접근 방식은 다음과 같다 : Eliminating Redundant Requests.>
- workload 정보를 활용하여 query 정확성에 영향을 주지 않고 LLM 요청 수를 줄인다.
- 특히 필요한 경우에만 LLM을 호출할 수 있도록 정확한 입력 프롬프트를 중복 제거 합니다.
- LLM operator cost를 계산하기
- SQL query 내의 LLM operator는 이러한 request에서 가장 비용이 많이 드는 부분이다.
- 표준 DB query 최적화 프로그램은 효율적인 query 계획을 생성하기 위해 key operator의 비용을 정확하게 예측하는 데 의존하므로 LLM operator cost를 고려해야 합니다.
- 예를 들어 LLM을 호출하기 전에 predicate pushdown을 적용해야 한다
- <본 논문에서의 접근 방식은 다음과 같다 : Cost Estimation.>
- 우리는 LLM operator cost를 SQL query 최적화 프로그램에 통합하여 필요할 때만 가장 비용이 많이 드는 작업이 호출되도록 한다.
- 특히 query 계획 프로세스 중에 LLM 계산 비용을 모델링한다.
- KV hit rate 높이기
3. Request Formulation
- 이 섹션에서는 KV cache에서 prefix sharing을 최대화하도록 설계된 request 스케줄링 알고리즘을 소개한다.
- batch query의 전체 workload 정보를 활용하여 동일한 prefix를 공유하는 모든 request가 연속적으로 실행되도록 보장하여 전반적인 LLM inference 효율성을 최적화한다.
- 특히 액세스하는 데이터를 기반으로 query를 그룹화하는 열 레벨 및 행 레벨의 재정렬 알고리즘을 제시한다.
3.1 Request Structure
- 구조화된 query의 맥락에서 LLM 함수를 정의한다. 이 함수는 하나 또는 여러 개의 열({a, b, c} 또는 {pr.*})과 같은 구조화된 표현식을 입력으로 받는다. 이를 처리하여 데이터를 추출하고 분석한다.
- UDF 입력 구조의 설계를 통해 이러한 표현식 내에서 필드를 동적으로 재정렬하여 캐시 효율성을 최적화할 수 있다.
3.2 Column Reordering
- cache hit는 request의 prefix에 대해서만 발생하므로 SQL query에서 올바른 열 순서를 결정하면 성능에 상당한 영향을 미칠 수 있다. 예를 들어 다음 query를 고려하자.

- 위 query는 reviewText, reviewerName, description, title과 같은 여러 열을 가지고 있고, summarization을 위해 각 행 데이터는 LLM에 보내진다.
- 만약 기존의 열 순서(reviewText가 첫번째)를 사용한다면 unique한 prefix가 많아서 비효율적이다.
- 따라서 description 열을 먼저 사용한다면, 많은 리뷰가 동일한 제품과 연결되어 있으므로 이러한 prefix를 cache에 넣게 되고 재사용할 수 있다.
- 열 level의 입력 재정렬의 목적은 KV cache의 토큰 hit rate을 최대화하도록 request 내의 필드 순서를 지정하는 것이다. 이 작업은 shared prefix 값과 해당 변수 길이의 다양성으로 인해 복잡해진다.
- 예를 들어 shared prefix가 길면 짧은 prefix보다 빈도가 낮더라도 더 많은 토큰 hit가 발생할 수 있다. 따라서 재정렬 전략에서는 cache reuse를 최대화하기 위해 prefix 빈도와 size 간의 균형이 필요하다
3.2.1 Oracle Algorithm (? LRU 알고리즘인가?)
- 주어진 열 수에 대해 가능한 permutation 수가 기하급수적으로 많기 때문에 최상의 열 순서를 찾는 것은 어렵다.
- 예를 들어, N개의 행과 M개의 열을 가진 데이터셋은 N × M의 열 순서가 존재한다.
- 이를 모두 열거하는 것은 실제로 엄청나게 비용이 많이 들기 때문에 효과적인 순서를 효율적으로 찾을 수 있는 경험적 방법이 필요하다.
3.2.2 Reordering Algorithm
- 재정렬 알고리즘은 열의 통계, 특히 열 값의 Cardinality를 사용하여 효과적인 순서를 빠르게 검색한다.
- Cardinality란 쉽게 말해서, 중복도가 '낮으면' Cardinality 가 '높다'고 표현하고 중복도가 '높으면' Cardinality 가 '낮다'고 표현한다. Cardinality 는 전체 행에 대한 특정 컬럼의 중복 수치를 나타내는 지표이다.
- 데이터베이스는 일반적으로 저장된 데이터에 대한 unique한 entry 개수(예를 들어 Cardinality) 및 각 열의 값 분포와 같은 통계를 유지 관리하며, 이를 활용하여 prefix sharing에 대한 가능성을 추론한다.
- 모든 행에 대해 고정된 열 순서를 설정하여 문제를 단순화한다. 이를 통해 기하급수적인 permutation 수를 고려할 필요가 없다.
- 실제로 많은 데이터셋에는 Cardinality가 높은 열(즉, shared prefix가 거의 없음)이 있으므로 해당 순서는 cache hit rate에 영향을 미치지 않는다.
- 구체적으로, 본문의 알고리즘은 각 열에 대해 평균 문자열 길이(ASL)을 미리 계산하는 것으로 시작된다. 그 알고리즘은 아래와 같다.

- 이러한 지표를 통해 각 열이 토큰 hit rate에 기여할 가능성을 추정할 수 있습니다. 데이터에 SQL query를 실행하여 특정 열에 있는 값의 평균 길이를 얻습니다(AVG(CHAR_LENGTH(col))) . 우리는 대부분의 시스템에 존재하는 기존 데이터베이스 통계에서 Cardinality를 검색한다.
- 위에서 언급한 알고리즘으로 각 열의 점수를 계산한다. 계산식은 다음과 같다.

- 이 방법에서는 점수가 높을수록 공유되는 데이터 값이 더 길고 자주 발생하는 열에 해당한다. 알고리즘은 내림차순으로 열을 배치한다.
- 논문에서 말하는 한계점은 다음과 같다.
- 열 level의 입력 재정렬 알고리즘은 cache의 효율성을 향상시킬 수 있는 잠재력을 보여 주지만, 이 접근 방식의 기 본 가정은 모든 데이터 행에 걸쳐 열의 순서가 고정되어 있다는 것이다.
- 이 가정은 계산 복잡도를 단순화하지만 실제 시나리오에서는 항상 유지되는 것이 아니다.
- 실제로는 포함된 특정 데이터에 따라 서로 다른 순서를 열 순서를 지정하면 여러 행에 대해 이점을 줄 수 있다. 이는 section 8.2.2에서 설명한다.
3.3 Row sorting
- 열 순서를 결정한 후에는 request 전체에서 shared prefix 수를 최대화하도록 데이터 행을 그룹화해야 한다.
- 이를 위해 모든 열 값을 문자열로 concat하고 이러한 문자열을 사전순으로(다른 행에 대해) 정렬하여 행 순서를 결정한다.
- 예시를 통해 쉽게 이해할 수 있다. 아래의 표를 보자.
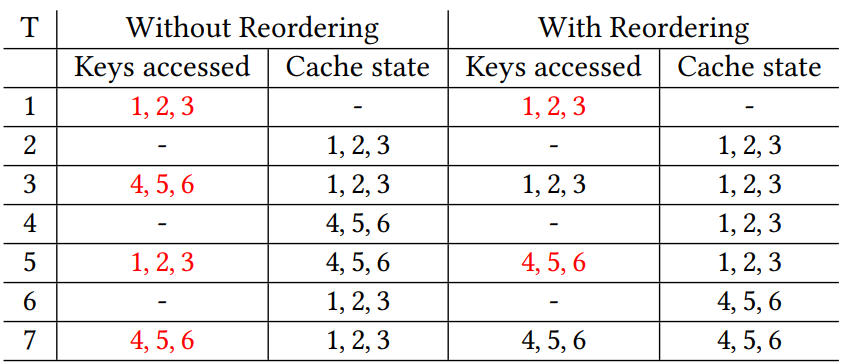
- 위의 표는 batch 크기가 3이고 6개의 prefix가 3번씩 나타나는 경우를 표현했다.
- Default KV cache는 FIFO와 같은 알고리즘에 따라 6개의 prefix를 모두 제거하고 다시 계산하므로 비효율적이다.
- 그러나 shared prefix를 그룹화하기 위해 행을 재정렬하면 더 효율적임을 볼 수 있다.
- SQL query의 구조화된 특성을 통해 요청을 효율적으로 정렬 할 수 있다. GROUP BY 나 ORDER BY와 같은 database operation을 이용하면 된다.
4. Deduplication
- 쓸데 없는 LLM 호출은 대부분의 LLM query에서 병목 현상이 발생한다. 즉, 성능 하락의 주요 원인 중 하나이다.
- 수행 해야 하는 inference 호출 수를 최소화하여 런타임을 더욱 줄일 수 있다. 특히, 동일한 입력 프롬프트가 있는 요청 전체에서 중복을 제거할 수 있다.
- 대규모 텍스트 데이터셋에는 중복 항목이 많이 포함되는 경우가 많다. 예를 들어, Sec 3.2에 예시로 들었던 query에서는 많은 리뷰에서 유사한 제품을 언급할 수 있다. LLM이나 벡터 DB를 통해 모든 리뷰를 처리하게 되면 계산이 중복된다.
- 이러한 중복 항목을 LLM 또는 벡터 DB에 전달하기 전에 식별한다면 계산량을 크게 줄일 수 있다.
- 최신 추천 데이터셋에는 테이블 열에 높은 수준의 중복이 있는 경우가 많다. 예를 들어, 추천 모델에 일반적으로 사용 되는 Rotten Tomatoes Movie 데이터셋에는 리뷰 카테고리에 해당하는 review_type라는 열(예를 들어 'Fresh' 또는 'Rotten'로 이루어짐)이 있다.
- 결과적으로, 선택성 비율, 즉 전체 값 대비 고유한 값의 비율은 0.008에 불과하다. 이는 카테고리가 두 개뿐이기 때문이다.
4.1 Exact Deduplication
- 본 논문에서는 query 결과에 영향을 주지 않고 중복 제거를 적용하였다.
- RDMBS에서 이는 일반적으로 쿼리 입력에 대해 distinct filter(예:DISTINCT in SQL)로 구현할 수 있다.
- 이 접근 방식은 중복 request가 모델에 도달 하기 전에 필터링하여 LLM 호출 수를 줄이는 데 간단하고 효과적이다.
- 그러나 여러 데이터 행에 중복 제거를 적용하면 특히 메모리 및 처리 시간과 관련하여 문제가 발생할 수 있다.
- 또한 방대한 양의 개별 데이터가 있는 시나리오에서는 중복 항목을 식별하는 것이 그다지 도움이 되지 않는다. 이는 실험 결과에서도 관찰되었다.
- sec 7의 sec 8에서는 서로 다른 selectivity 비율의 열을 사용한 중복 제거에 대한 연구를 보여준다.
- 또한 이에 대해 본문에서는 추가적인 연구 주제를 제안한다. 정확한 일치 외에도 semantic deduplication, 즉 의미상 유사한 레코드를 식별하는 중복 제거는 유망한 연구 주제라고 언급한다. 이는 sec 8.4에서 더 자세히 논의한다.
5. SQL Optimizations
- 관계형 데이터베이스는 cost-based query 최적화 프로그램을 사용하여 request 성능을 향상시킨다. 이러한 최적화 프로그램은 query 구조와 operator를 분석하여 데이터 액세스 및 계산 오버헤드를 최소화한니다. LLM 호출을 최소화하는 query plan을 찾을 수 있도록 LLM operator cost를 고려하여 이러한 최적화 프로그램을 확장한다.
5.1 LLM operator costs
- 현재 LLM은 UDF를 통해 가장 일반적으로 액세스된다.
- 예를 들어 Databricks는 ai_query() 함수는 사용자가 모델 endpoint를 호출할 수 있게 해주는 함수이다.
- Amazon Redshift에서는 UDF 기능을 통해 LLM 호출을 사용할 수 있습니다.
- 논문에서는 입력의 토큰 길이와 요청에 대한 예상 decode 길이를 기준으로 LLM 비용을 추정한다.
- 대부분의 경우 LLM 호출은 다른 query operator에 비해 상당히 비용이 많이 들기에 query plan에 표시된다.
- 다음 그림을 통해 LLM operator costs가 어떻게 query plan에 영향을 주는 지 알아볼 수 있다.

- 위 그림은 하나의 LLM filter와 하나의 non-LLM filter가 있는 SQL의 예시이다. 이러한 필터가 적용되는 순서는 end-to-end query 실행 시간에 영향을 미친다.
- 위의 SQL 쿼리는 사용자의 Comments Database에서 부정적인 코멘트를 작성한 사용자 ID를 가져오는 예시이다. 이 쿼리에서 중요한 점은 LLM(Large Language Model)을 이용한 필터링과 일반 SQL 필터링이 혼합되어 있다는 것이다. 이러한 필터가 적용되는 순서는 쿼리의 전체 실행 시간에 큰 영향을 미칠 수 있다.
- 필터 종류는 아래와 같다.
- LLM 필터: 코멘트의 텍스트를 분석하여 부정적인 감정으로 분류하는 필터이다. LLM을 호출하여 Comment 텍스트의 감정 분석을 수행한다.
- non-LLM 필터: Comment의 타임스탬프가 특정 날짜 이후인지를 확인하는 필터입니다. 이는 일반적인 SQL 조건이다.
- 필터 적용 순서의 영향은 아래와 같다.
- LLM 필터가 먼저 적용되는 경우
- 과정: 모든 코멘트 텍스트에 대해 LLM을 호출하여 감정 분석을 수행한다.
- 비용: 모든 코멘트 텍스트에 대해 LLM을 호출하므로 비용이 매우 높다.
- 실행 시간이 매우 길어진다.
- non-LLM 필터가 먼저 적용되는 경우
- 과정: 타임스탬프가 2023-10-01 이후인 코멘트를 먼저 필터링합니다. 그런 다음 필터링된 코멘트에 대해서만 LLM을 호출한다.
- 비용: 타임스탬프 필터링은 상대적으로 비용이 낮습니다. 필터링된 코멘트에 대해서만 LLM을 호출하므로 비용이 절감된다.
- 전체 쿼리의 실행 시간이 크게 단축된다.
- LLM 필터가 먼저 적용되는 경우
- 쿼리의 전체 실행 시간은 LLM 필터와 non-LLM 필터가 적용되는 순서에 크게 영향을 받는다. 일반적으로, 가장 비용이 많이 드는 작업을 나중에 수행하는 것이 효율적이다. 여기서 LLM 필터는 실행 비용이 매우 높기 때문에 이 필터를 나중에 적용하는 것이 좋다.
- 최적화된 쿼리는 아래와 같다
- 비용이 적게 드는 필터를 먼저 적용하여 LLM의 호출 빈도를 줄이는 것이 최적화된 쿼리이다.

- 위와 같이 타임스탬프 필터를 먼저 적용하면, 전체 코멘트 중에서 해당 날짜 이후의 코멘트만 LLM으로 감정 분석을 하게 되어, LLM 호출 횟수가 줄어들고 전체 쿼리 실행 시간이 크게 단축될 것이다.
- 쿼리에서 LLM 필터와 non-LLM 필터의 순서는 쿼리의 전체 실행 시간에 중요한 영향을 미친다. 비용이 적게 드는 non-LLM 필터를 먼저 적용하고, 그 결과에 대해 LLM 필터를 적용하는 것이 효율적이다. 이는 LLM 호출 횟수를 최소화하고, 전체 쿼리 성능을 최적화하는 데 도움을 준다.
6. Implementation
- 이 논문에서 어떤 방식으로 위의 방법론들을 구현했는지 설명하고 있다. 이 부분은 간략히 설명하겠다.
6.1 LLM UDFs and Optimizations
- SQL 쿼리에서 LLM을 호출하기 위해 LLM endpoint와 벡터 DB에 대한 외부 호출을 만드는 PySpark UDF를 구현한다.
- UDF는 LLM에 대한 프롬프트와 열 당 데이터 값을 모델에 전달할 인수로 사용한다.
- LLM output post-processing도 UDF에서 처리된다.
- 다음과 같은 구조를 갖는 데이터셋들을 사용하였다.


- prompt 구조와 output post-processing은 생략(논문 직접 참고)
6.2 Prefix Caching
- 현재 vLLM 구현에서는 request batch의 모든 prefix가 KV cache에 들어갈 수 있다고 가정하지만 batch 분석 workload에 일반적으로 발생하는 다양한 prefix size가 있는 경우에는 그렇지 않다.
- 본 논문은 vLLM 내의 KV cache에 대한 새로운 제거 전략을 구현하여 이러한 제한 사항을 해결한다.
- 새 request가 예약되어 있고 새 request를 수용할 GPU 메모리가 부족한 경우 시스템은 FIFO 순서에 따라 자동으로 prefix를 제거한다. 이전에 제거된 prefix가 향후 request에 필요한 경우 다시 계산되어 cache에 올라간다.
- 이 전략을 통해 시스템은 메모리 제약 조건을 효과적으로 관리하면서 변화하는 workload 패턴에 동적으로 적응할 수 있다.
7. Evaluation
- 이 섹션에서는 구성된 벤치마크 쿼리 제품군 내에서 최적화의 효율성을 평가한다.
- LLM 출력 생성 시간은 query latency를 지배하며, LLM이 수신하는 입력 수를 줄이는 최적화는 성능을 크게 향상시킨다.
- 단일 프롬프트와 프롬프트 배치 내에서 LLM에 제공하는 입력 순서를 변경하면 query latency를 눈에 띄게 줄일 수 있다.
7.1 Evaluation Benchmark
- LLM 쿼리에 대한 표준 벤치마크가 부족하다는 점을 고려하여 실제 데이터 검색 및 처리 작업을 나타내는 벤치마크 제품군을 구성한다.
- 본 논문은 LLM을 관계형 분석에 통합할 때의 영향을 평가하기 위해 다양한 소스의 데이터셋에 대해 다양한 쿼리 유형을 생성한다.
7.1.1 Datasets
- Amazon Product Reviews, Rotten Tomatoes Movie Reviews, Stanford Question Answering Dataset (SQuAD) 3가지를 사용
7.1.2 LLM Queries
- 총 5가지 케이스에 대해 실험함
- Q1: LLM projection
- SELECT statement를 통해 지정된 데이터베이스 열의 정보를 처리하는 명령문. summarization이나 interpretation에서 사용

- Q2: LLM filter
- LLM은 긍정적인 리뷰 식별과 같은 특정 기준을 충족하기 위해 정보를 처리하고 분석한다. 이 유형은 고객 피드백 분석 및 콘텐츠 조정과 같은 애플리케이션 작업에 중요한 감성 분석 및 콘텐츠 필터링의 일반적인 사용 사례를 보여다.

- Q3: Multi-LLM invocation
- 이 유형은 쿼리의 다양한 부분에서 여러 LLM 호출을 포함하며 여러 계층의 데이터 처리 또는 분석이 필요한 시나리오를 다룬다. 다양한 데이터 통찰력을 결합하거나 순차적 데이터 변환을 수행하는 등의 고급 분석 작업을 나타낸다.

- Q4: LLM aggregation
- 이 유형은 LLM 출력을 추가 쿼리 처리에 통합한다. 예를 들어 이러한 쿼리 중 하나는 LLM을 사용하여 개별 리뷰에 감정 점수를 할당한 다음 이러한 점수를 집계하여 전체 고객 피드백에 대한 평균 감정을 계산할 수 있다. 이 쿼리 유형은 복잡한 텍스트 데이터에서 통찰력을 추출해야 하는 작업에 필수적이다.

- Q5: Retrieval-augmented generation (RAG)
- 이 쿼리 유형은 향상된 LLM 처리를 위해 외부 지식 기반을 활용하여 더 광범위한 context로 LLM 쿼리를 강화한다. 포괄적인 답변을 제공하기 위해 쿼리가 문서 데이터베이스 또는 지식 그래프와 같은 외부 소스에서 관련 정보를 가져와야 하는 사례이다.

- 평가 metric은 end-to-end query execution time과. KV cache에서 제공되는 prefix 토큰의 비율 Token Hit Rate(THR)을 사용하였다.
- 실험 결과는 생략. 자세한 것은 논문 직접 참고.
- 말이 길지만, 결론은 본인들 방식이 기존 방식보다 좋다는 것.



8. Discussion
- 이 섹션에서는 relational analytics에서 LLM inference를 더욱 향상시키기 위한 향후 연구 방향을 간략하게 설명한다.
- 이들의 논의는 distributed cache와 request routing , LLM 호출에 대한 비용 추정, semantic한 중복 제거라는 세 가지 주제로 구성된다.
8.1 Column Reordering and Row Sorting
- 이들은 보다 세분화된 접근 방식을 채택하여 향후 작업에서 이러한 알고리즘을 더욱 확장 할 수 있다고 언급한다.
- 예를 들어, 테이블의 모든 행에 대해 고정된 열 순서를 유지하는 대신 행의 하위 집합에 대해 서로 다른 열 순서를 고려하여 토큰 적중률을 더욱 높일 수 있다고 언급한다.
- 이를 위해 가능한 전략 중 하나는 지정된 "pivot" 열의 값을 공유하는 각 행 그룹에 대한 열 순서를 반복적으로 결정하는 것이다.
- 그룹에 대한 순서가 설정되면 이후의 반복에서 해당 행을 제외할 수 있으므로 복잡성이 줄어들고 나머지 행의 순서를 결정하는 데 집중할 수 있다.
- 이 재귀적 접근 방식을 사용하면 계산 효율성을 포기하지 않고 cache hit rate를 향상시키기 위해 열 순서를 점진적으로 개선할 수 있다.
- 또한 prefix sharing에 대한 영향이 미미한 열에 대해 정리하는 메커니즘을 도입할 것이라 한다. 재정렬 프로세스에서 이러한 열을 제외함으로써 계산 오버헤드를 더욱 줄일 수 있습니다.
8.2 Prefix Caching: Opportunities
- 이들은 입력 프롬프트에 대한 메모리 관리에 중점을 두고 있지만 출력 디코딩도 성능에 상당한 영향을 미친다.
- 특히, 분석을 할 때 guided decoding을 사용하면 잠재적인 이점이 있다. guided decoding은 더 추가적인 공부가 필요하다.
- 뿐만 아니라 Batch-Aware Reordering을 고려해야 한다고 언급한다. 일부 시스템에서 LLM 추론 중에 일괄 요청이 병렬로 처리되는 방식을 다루지 않는다. 일부 추론 시스템은 동시 계산으로 인해 동일한 배치 내에서 prefix sharing을 지원하지 않는다.
- 이 문제를 해결하기 위해 요청 순서를 일괄 실행 단계에 맞춰 prefix 활용을 최적화하는 Batch-Aware Reordering 전략을 제안한다. 이 접근 방식에는 cache에 대한 준비 단계가 필요하며, 후속 배치에서 재사용될 것으로 예상되는 다양한 prefix를 사용하여 cache를 미리 로드한다. 우리의 알고리즘은 먼저 발생 빈도에 따라 가능한 모든 prefix를 정렬한 다 음 배치 전체에 걸쳐 정렬하여 각 배치에 고유한 prefix set가 포함되도록 한다. 이 방법을 사용하면 cache를 보다 효과적으로 활용할 수 있다. 일괄 처리가 되면 모든 후속 요청에서 cache된 prefix를 재사용할 수 있으므로 캐시 누락이 크게 줄어든다.
8.3 Distributed Cache and Request Routing
- 대규모 데이터셋에서는 합리적인 시간 내에 쿼리가 완료될 수 있도록 inference workload를 여러 시스템에 분산해야 한다.
- 그러나 분산 KV caching은 어렵다. 유사하거나 동일한 prefix를 가진 요청이 동일한 시스템으로 전달되도록 해야 한다.
- 뿐만 아니라 RAG 쿼리는 추가적인 복잡성을 가져온다. 이 경우에는 KV cache는 LLM prefix뿐만 아니라 노드 전체에 배포될 수 있는 임베딩 및 관련 검색 콘텐츠도 저장해야 하기 때문이다.
- 따라서 cache 내용이 다양한 여러 시스템에 대한 로드 균형을 조정하는 것이 중요한 목표입니다.
8.4 Semantic Deduplication
- 대소문자 구분(예: 'Apple' 과 'apple')과 노이즈(예: '<Apple>' 과 'Apple')를 제거하고 형태소 분석 및 표제어 분석(예: 'running' , 'ran', 'runs'), 철자 수정(예: 'mitake' 과 'mistake'), stop word removal (예: 'a', 'the' 등을 제거)을 적용하는 NLP 전처리 기술을 활용할 수 있다.
- 이는 특정 규칙을 통해 텍스트의 동등성이 인정되므로, 쿼리 정확도에 영향을 주지 않고 LLM 호출 수를 줄이기 위해 하드한 제약 조건(사용자가 선택적으로 지정)으로 구현할 수 있다.
- 또한 의미상 유사한 행을 식별하여 더욱 적극적으로 중복 제거를 수행할 수 있다. 예를 들어, "나는 이 레스토랑을 좋아합니다"와 "나는 이 장소를 좋아합니다"는 동일한 의미를 가지며 LLM 감정 분석 작업에서 동일한 출력을 생성할 가능성이 높다.
- 따라서 처리를 위해 이러한 입력 중 하나만 LLM으로 보내는 것만으로도 대부분의 목적을 달성 할 수 있다.
- 한 가지 가능한 방향은 LLM 내의 토큰 유사성을 평가하여 의미상 동일한 요청을 식별하는 것이다.
- 또한 프로덕션 workload 처리를 위해 SemDeDup과 같은 traing 데이터셋 중복 제거 방법을 도입할 수 있기를 기대한다고 언급한다.
<참고>
https://www.ibm.com/kr-ko/topics/workload
https://velog.io/@doh0106/vLLM-%EB%85%BC%EB%AC%B8-%EC%9A%94%EC%95%BD-%EB%A6%AC%EB%B7%B0
https://artist-developer.tistory.com/7
https://itholic.github.io/database-cardinality/
https://learn.microsoft.com/ko-kr/azure/databricks/udf/
https://guideddecoding.github.io/



