
https://arxiv.org/abs/1406.2661
Generative Adversarial Networks
We propose a new framework for estimating generative models via an adversarial process, in which we simultaneously train two models: a generative model G that captures the data distribution, and a discriminative model D that estimates the probability that
arxiv.org
Abstract
- 적대적(adversarial) 프로세스를 통해 생성 모델을 추정하는 프레임워크 제안함
- 이 프레임워크는 'minimax two-player game'
- G의 training 목표: D가 실수할 확률을 최대화하는 것
- 이 프레임워크에서는 두 가지 모델을 동시에 학습시킴
① Generative model G: 데이터 분포를 포착하는 생성 모델
② Discriminative model D: 샘플이 G가 아닌 training data에서 왔을 확률을 추정하는 판별 모델 - G와 D가 multilayer perceptrons로 정의되는 경우, 전체 시스템이 backpropagation 방식으로 학습될 수 있음
- Markov chains이나 unrolled approximate inference networks가 필요하지 않음
- 실험은 생성된 샘플의 정성적·정량적 평가를 통해 프레임워크의 잠재력을 보여줌
1 Introduction
- 딥러닝의 약속은 풍부한 계층적(hierarchical) 모델을 발견하는 것
- 인공지능 애플리케이션에서 마주치는 데이터 종류에 대한 확률 분포를 나타내는 모델
- 인공지능 애플리케이션: 자연 이미지, 음성을 포함하는 오디오 파형, 자연어 말뭉치의 기호 등
- 지금까지 딥러닝에서 가장 놀라운 성공은 차별적 모델(discriminative models), 일반적으로 고차원적이고(high-dimensional) 풍부한 sensory input을 class label에에 매핑하는 모델과 관련 있음
- 이러한 놀라운 성공은 주로 backpropagation과 dropout 알고리즘에 기반함
- 특히 well-behaved gradient를 가진 piecewise linear units를 사용하는 것
- deep generative models는 제어하기 어려운 요소들이 많아 이러한 연구 결과에 해당 사항이 적었음
- 이러한 어려움을 피하는 새로운 생성형 모델(generative models) 추정 절차를 제안함
3 Adversarial nets

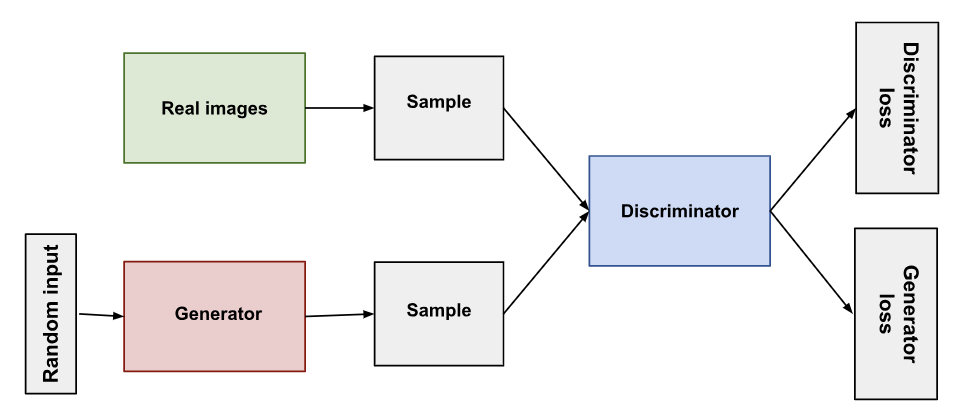
- 적대적 모델링 프레임워크는 모델이 모두 multilayer perceptrons일 때 가장 간단하게 적용할 수 있음





- D, blue, 점선: discriminative distribution → 실제 데이터와 생성한 데이터 판별
- black, 점: samples from the data generating distribution px (실제 데이터)
- G, green, 실선: generative distribution (생성한 데이터)
- 아래 수평선: z가 샘플되는 영역
학습 초기 (a)에서는 real/fake의 분포가 크게 다르고, discriminator도 부분적인 판별을 하여 성능이 좋지 않음
학습 과정 반복 결과 (d)에서는 real/fake 분포가 거의 비슷해지고, discriminator는 1/2의 확률로 판별함
4 Theoretical Results

(즉, 이 실험에서는 discriminator와 generator를 한 번씩 업데이트함.)

- Update the discriminator by ascending its stochastic gradient (최대화) (k steps)
- Update the generator by descending its stochastic gradient (최소화) (1 step)


5 Experiments

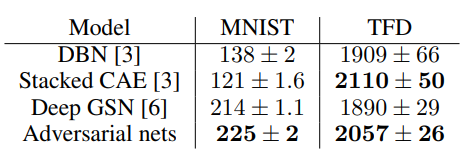







6 Advantages and disadvantages

7 Conclusions and future work
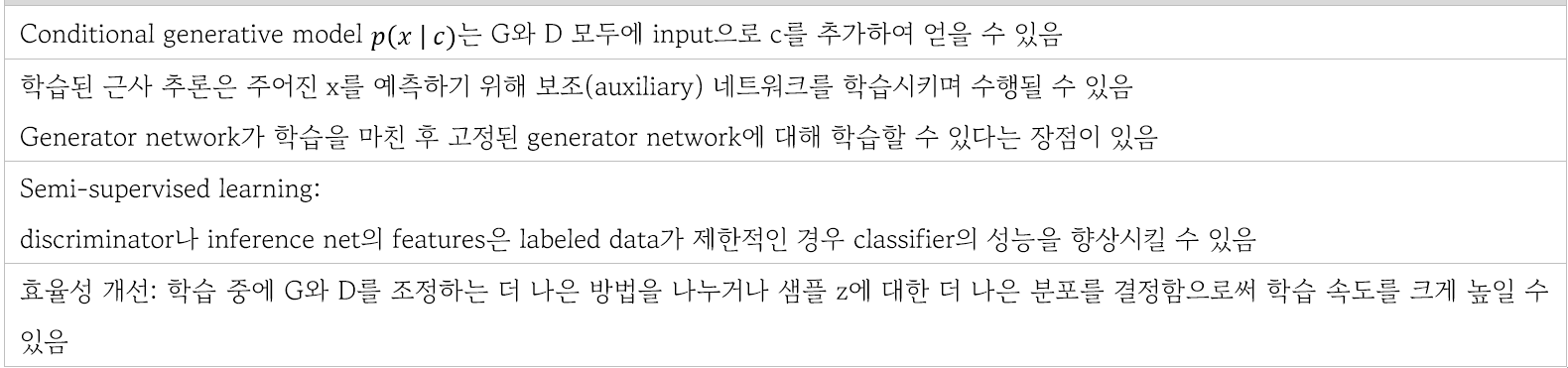
https://developers.google.com/machine-learning/gan/gan_structure?hl=ko



