https://arxiv.org/abs/2309.02706
HAE-RAE Bench: Evaluation of Korean Knowledge in Language Models
Large Language Models (LLMs) trained on massive corpora demonstrate impressive capabilities in a wide range of tasks. While there are ongoing efforts to adapt these models to languages beyond English, the attention given to their evaluation methodologies r
arxiv.org
Abstract
- LLM 모델을 비영어권에 적용하려는 시도가 많음에도 불구하고, 비영어권 언어 이해 평가 방법론은 아직 제한적임.
- 현재 평가 방법론은 영어 기반 test를 번역하는 정도에서 그치고 있고, 이것은 언어적, 문화적 뉘앙스를 반영하지 못함.
- HAE-RAE Bench는 한국어에 담긴 한국 문화적, 맥락적인 깊이를 평가하기 위해 개발되었음.
- Dataset은 단어/역사/일반 상식/독해 영역에서 여러개의 task로 구성되어 있음.
- HAE-RAE Bench는 한국어로 기반하지 않은 모델들에 많은 도전과제를 제공함.
Introduction
- 현존 한국어 기반 LLM 평가 데이터셋은 Korean-NLI & STS, KLUE, KoBEST 정도가 있음. Korean-NLI는 단순히 기존 영어 기반 데이터셋을 번역한 것이며, KLUE는 GLUE Benchmark의 한국어 버전인데, task가 너무 간단함. KoBEST는 한국어 기반으로 인과추론이나 시간에 대한 추론을 묻고 있는데, 문화 맥락적인 내용을 묻고 있지 않음.

- HAE-RAE Bench는 한국 문화 맥락적인 이해를 평가하기 위한 데이터셋을 제공함.
HAE-RAE Bench
1. Loan Words (외래어)
- 제시된 외래어와 알맞은 한국어 단어 (순화어)를 선택하는 오지선다형 문제
- 네이버/다음 지식 백과를 사용함.
- Levenshtein distance를 사용해 incorrect option을 선정하고 제거함.
Q. 다음 질문을 읽고 정답으로 가장 알맞은 것을 고르시요. ### 질문: 체크 리스트의 순화어 알맞은 것은? ### 선택지: (A) 붙임표 (B) 줄임표 (C) 점밝기 (D) 그림표 (E) 점검표 ### 정답:
A. E
2. Standard Nomenclature (표준 전문 용어)
- 주어진 표준 전문 용어와 가장 알맞은 한국어 단어를 선택하는 오지선다형 문제
- 국립국어원 데이터셋을 사용함.
- 1과 같은 방식으로 오답 보기 생성함.
Q. 다음 질문을 읽고 정답으로 가장 알맞은 것을 고르시요. ### 질문: 커리어 하이의 올바른 표준 전문 용어로 알맞은 것은? ### 선택지: (A) 구간 기록 (B) 두번 기록 (C) 토지 기록 (D) 최고 기록 (E) 추가 기록 ### 정답:
A. D
3. Rare Words (희귀 단어)
- 주어진 설명에 가장 알맞은 한국어 희귀 단어를 선택하는 오지선다형 문제
- "우리말 겨루기"에 나온 문제 데이터를 사용함.
- 1과 같은 방식으로 오답 보기 생성 및 제거함.
Q. 다음 질문을 읽고 정답으로 가장 알맞은 것을 고르시요. ### 질문: 떼를 지어 행동하는 무리의 의미를 가진 단어로 알맞은 것은? ### 선택지: (A) 큰항아리 (B) 동아리 (C) 작동거리 (D) 한동아리 (E) 송아리 ### 정답:
A. D
4. General Knowledge (일반 상식)
- 법, 전통, 지리, K-Pop, K-Drama와 관련한 오지선다형 문제
- Question Only (질문만 있음), Context Only (맥락만 주어짐) setting과 질문 및 맥락을 모두 주는 full setting과 비교하여 해당 카테고리의 질문-맥락 유효성을 검증함.
Q. 다음 질문을 읽고 정답으로 가장 알맞은 것을 고르시요. ### 질문: 다음 중 중 대화가 이루어지는 장소로 가장 적절한 것을 고르시오 ### 참고: 가: 이수진! 일어나서 13번 답 말해볼래? 나: 아, 죄송해요 선생님. 잘 모르겠어요. 가: 그럼 옆에 있는 짝꿍 일어나서 말해보자. ### 선택지: (A) 식당 (B) 병원 (C) 학교 (D) 도서관 (E) 백화점 ### 정답:
A. C
Q. 다음 질문을 읽고 정답으로 가장 알맞은 것을 고르시요. ### 질문: 다음 중 한국의 정치에 대한 설명으로 옳지 않은 것을 고르시오. ### 참고:nan ### 선택지: (A) 법에 의해 통치한다. (B) 국민의 자유와 평등을 강조한다. (C) 선거를 통해 국민의 대표를 선출한다. (D) 국가의 정책에 국민의 의사를 반영한다. (E) 국가의 모든 일은 국민 투표를 통해 결정한다. ### 정답:
A. E
Q. 다음 질문을 읽고 정답으로 가장 알맞은 것을 고르시요. ### 질문: 서울과 인접해 있는 도시는? ### 참고:nan ### 선택지: (A) 광주 (B) 부산 (C) 대전 (D) 인천 (E) 제주시 ### 정답:
A. D
Q. 다음 질문을 읽고 정답으로 가장 알맞은 것을 고르시요. ### 질문: 보기 중 빈칸에 들어갈 말로 알맞은 것을 고르시오. ### 참고:ITZY의 리더는 [BLANK]입니다. ### 선택지: (A) 유나 (B) 지효 (C) 채연 (D) 예지 (E) 채령 ### 정답:
A. D
Q. 다음 질문을 읽고 정답으로 가장 알맞은 것을 고르시요. ### 질문: 다음 대사가 나온 영화를 고르시오. ### 참고:"가장 완벽한 계획이 뭔지 알아? 무계획이야. 계획을 하면 모든 계획이 다 계획대로 되지 않는 게 인생이거든." ### 선택지: (A) 헤어질 결심 (B) 극한직업 (C) 완벽한 타인 (D) 독전 (E) 기생충 ### 정답:
A. E
5. History
- 역사와 관한 오지선다형 문제
- 나무위키의 한국사 태그 문서를 참조하여 문제를 직접 제작함.
- 필터링 과정을 통해 너무 간단한 문제나 편향이 있다면 제거하려고 했음.
Q. 다음 질문을 읽고 정답으로 가장 알맞은 것을 고르시요. ### 질문: ‘널리 인간을 이롭게 한다.’는 고조선의 건국 이념은? ### 선택지: (A) 제왕운기 (B) 공동번영 (C) 인류공영 (D) 만민보 (E) 홍익인간 ### 정답:
A. E
6. Reading Comprehension
- 한국어 능력 평가 (KLAT)에서 제공되는 독해 문제를 사용함.
- 난도에 따라서 A,B,C,A미만으로 구분되는 문제
Q. 다음 지문을 읽고 질문에 대답으로 가장 적절한 것을 고르시요. ### 지문: 다음은 토론의 일부를 들려 드립니다. 잘 듣고 4번과 5번의 두 물음에 답하십시오. 사회자(남): 네, 알겠습니다. 지금까지 수돗물 정책을 담당하시는 박 과장님의 말씀을들 었는데요. 그럼 이번에는 시민 단체의 의견을 들어 보겠습니다. 김 박사님~. 김 박사(여) : 네, 사실 굉장히 답답합니다. 공단 폐수 방류 사건 이후에 17년간 네 번에 걸친 종합 대책이 마련됐고, 상당히 많은 예산이 투입된 것으로 알고 있습니다. 그런데도 이번에 상수도 사업을 민영화하겠다는 것은 결국 수돗물 정책이 실패했다는 걸 스스로 인정하는 게 아닌가 싶습니다. 그리고 민영화만 되면 모든 문제가 해결되는 것처 럼 말씀하시는데요, 현실을 너무 안이하게 보고 있다는 생각이 듭니다. 사회자(남): 말씀 중에 죄송합니다만, 수돗물 사업이 민영화되면 좀 더 효율적이고 전문적 으로 운영된다는 생각에 동의할 분도 많을 것 같은데요. 김 박사(여) : 전 동의할 수 없습니다. 우선 정부도 수돗물 사업과 관련하여 충분히 전문성 을 갖추고 있다고 봅니다. 현장에서 근무하는 분들의 기술 수준도 세계적이고요. 그리 고 효율성 문제는요, 저희가 알아본 바에 의하면 시설 가동률이 50% 정도에 그치고 있 고, 누수율도 15%나 된다는데, 이런 것들은 시설 보수나 철저한 관리를 통해 정부가 충분히 해결할 수 있다고 봅니다. 게다가 현재 상태로 민영화가 된다면 또 다른 문제 가 생길 수 있습니다. 수듯물 가격의 인상을 피할 수 없다고 보는데요. 물 산업 강국이 라는 프랑스도 민영화 이후에 물 값이 150%나 인상되었다고 하는데, 우리에게도 같은 일이 일어나지 않을까 걱정됩니다. 사회자(남) : 박 과장님, 김 박사님의 의견에 대해 어떻게 생각하십니까? 박 과장(남) : 민영화할 경우 아무래도 어느 정도 가격 인상 요인이 있겠습니다만 정부와 잘 협조하면 인상 폭을 최소화할 수 있으리라고 봅니다. 무엇보다도 수돗물 사업을 민 간 기업이 운영하게 된다면, 수질도 개선될 것이고, 여러 가지 면에서 더욱 질 좋은 서 비스를 받을 수 있을 겁니다. 또 시설 가동률과 누수율의 문제도 조속히 해결될 수 있 을 겁니다. ### 질문: 여성 토론자의 발언으로 볼 때, 정책 담당자가 이전에 말했을 내용으로 가장 적절한 것은? ### 선택지: (A) 민영화를 통해 수돗물의 가격을 안정시킬 수 있다. (B) 수돗물 사업의 전문성을 위해 기술 교육을 강화해야 한다. (C) 종합적인 대책 마련으로 수돗물을 효율적으로 공급하고 있다. (D) 효율성을 높이기 위해 수돗물 사업을 민간 기업에 맡겨야 한다. (E) 거대한 규모의 사업을 민간 기업이 맡는 것은 쉬운 일이 아니다. ### 정답:
A. D
Evaluation Settings
- Language Models
- Korean-focused models: Polyglot-ko (1.3B/3.8B/5.8B/12.8B)
- Multilingual models: UMT5-XL/XXL
- English-centric models: Llama (2.7B/13B)
- GPT (GPT-3.5-Turbo, GPT-4)
- Methodology
- LM-Eval-Harness 논문에서 사용되었던 log-likelihood 방법론을 적용함. (각각의 옵션에 따른 log-likelihood를 계산하고 그것이 제일 높은 것을 채택하는 방식)
- Results
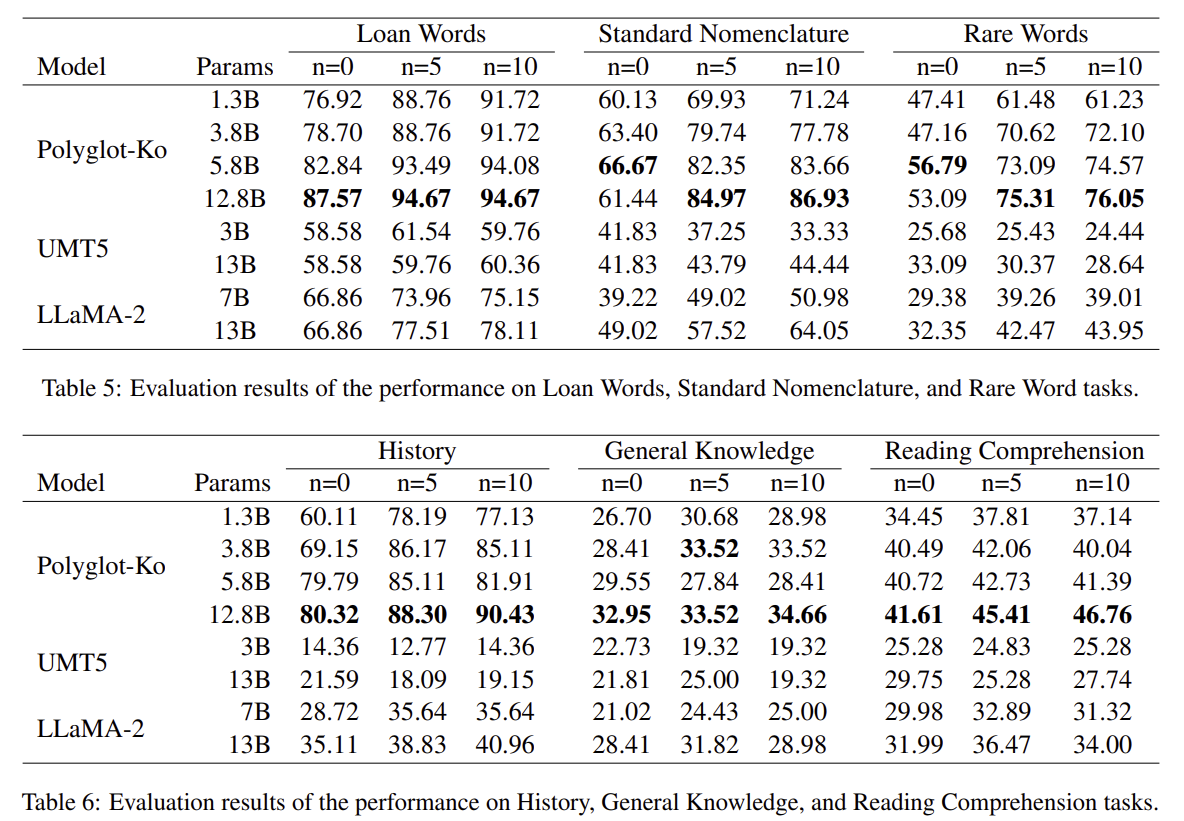
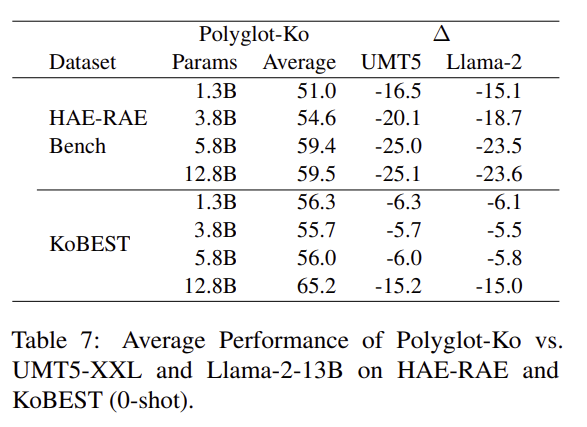
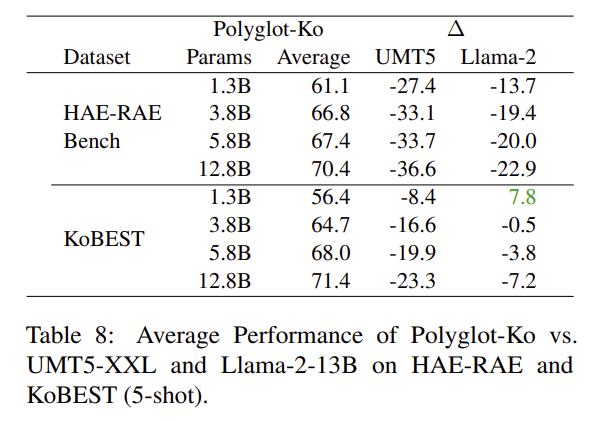
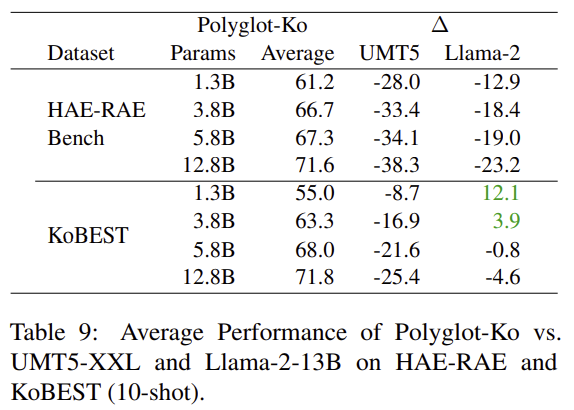
Discussion
- Training Corpora에 사용된 Language Frequency가 중요한가?
- UMT5가 꽤 높은 한국어 빈도를 보임에도 불구하고 성능이 좋지 못했음.
- 따라서, 빈도만으로는 In-Context Learning에서의 성능 향상을 보장하기에는 어려움.
- HAE-RAE Bench에서 model size는 얼마나 중요한가?
- ANOVA 분석을 통해 분석했고, KoBEST는 model size의 증가에 따라서 단순 성능 향상이 되지만, HAE-RAE Bench는 단순 model size 증가만으로는 해결되지 않음을 확인할 수 있음.
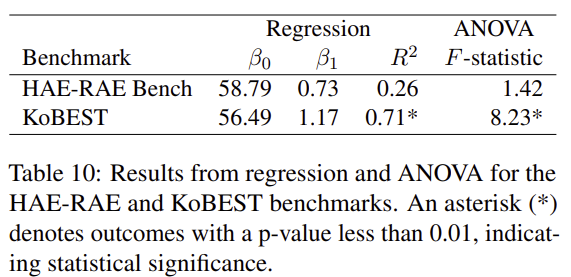
Figure 7. HAE-RAE Bench와 KoBEST의 model size에 따른 ANOVA 분석
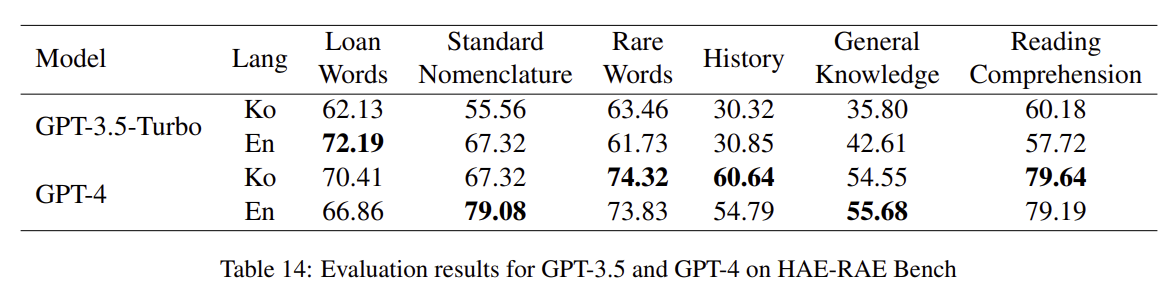
- GPT가 HAE-RAE Bench에서도 최고 성능을 기록할 수 있는가?
- Log-Likelihood를 제공하지 않기에 정당한 비교는 되지 못하지만, 몇개의 분야 (General Knowledge, Reading Comprehension, Rare Words)에서는 최고 성능을 기록한 것으로 확인됨.
- 영어에서의 Knowledge Transfer가 확인 되는가?
- Cross-Lingual Thought Prompting (XLT) 방식을 적용해 평가했음.
- 전반적으로, GPT3.5보다 GPT4가 Knowledge Transfer가 잘 이루어졌음을 확인할 수 있음.
- 한편, HAE-RAE Bench에서는 전반적으로 XLT를 적용하더라도 성능 차이가 많이 나지 않음. 즉, 영어로 학습한 내용으로는 한국 문화 맥락적인 이해에는 도달하기 힘들다고 볼 수 있음.

Error Analysis
- 응답에 대한 통계적인 분석을 하였음.