
AA-LCR (Artificial Analysis Long Context Reasoning)
ArtificialAnalysis/AA-LCR · Datasets at Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
오늘 다룰 벤치마크는 AA-LCR이라는 벤치마크로, 언어 모델이 매우 긴 문서를 여러개 읽고 정보를 추출하고, 추론하고, 종합적으로 사고하는 등의 Reasoning 능력을 측정하는 벤치마크이다. Artificial Analysis Intelligence Index v2.2에 포함되었다.
본 글에서는 벤치마크 데이터셋에 관한 내용과 여러 AI 모델들의 최신 성능, Long Context Reasoning 측정의 기반이 되는 기술 소개, AA-LCR을 평가지표로 활용한 논문 등을 소개하고자 한다.
AA-LCR 벤치마크 데이터셋 소개
1. 데이터셋 의의
AA-LCR의 핵심 목적은 실제 지식노동과 유사한 추론 과제을 재현하는 데 있다. 이를 통해 여러 긴 문서를 읽고 정보를 종합해 여러 단계의 추론을 수행하는 등의 AI의 중요한 능력을 평가한다.
2. 데이터셋 관련 통계
AA-LCR 벤치마크는 크게 질문의 바탕이 되는 문서 세트와 문서 세트에 대한 질문 및 정답들로 구성된다. 아래의 표는 벤치마크를 구성하는 요소들을 정리한 표이다. 문서의 카테고리와 카테고리별 질문 수, 총 문서의 수, 문서 세트의 수, 총 토큰량, 문서 세트 별 평균 토큰량을 확인할 수 있다.
카테고리를 살펴보면 기업 보고서, 산업 보고서, 정부 자문 문서, 학술 자료, 법률 문서, 마케팅 자료, 설문 보고서에서 문서를 선정했음을 알 수 있다. 예시로 회사 문서를 살펴보면, 총 문서의 수는 92개이며, 이를 바탕으로 16개의 문서 세트들이 만들어졌고, 이 세트들에 대해 63개의 질문과 답이 구성되었음을 알 수 있다.

전체 벤치마크를 구성하는 질문은 총 100개이다. 질문의 바탕이 되는 문서 세트들은 평균적으로 약 10만 개의 token으로 구성되며, 질문의 문맥(context) 으로 제공된다. 각 질문들은 질문의 정답을 문서에서 바로 찾아낼 수 없도록 설계되었으며, 문서 세트에서 여러 문서들로부터 정보를 찾고 여기에 일반적인 추론과 수학적 추론을 적용해야 답을 찾을 수 있도록 질문을 구성하였다.
다음의 예시 문제를 통해 AA-LCR의 문제 구성을 자세히 살펴보자.
[ 예시 문제 ]
● document_category : Company_Documents
● document_set_id : co_dc_press_b
● question : For the company and quarter where the company reported a 13.5% decline on the prior quarters operating income. What was their adjusted EBITDA? List the company name and adjusted EBITDA
( 직전 분기 대비 영업이익이 13.5% 감소했다고 보고한 회사와 해당 분기 에 대해, 그 회사의 조정 EBITDA(adjusted EBITDA)는 얼마였는가? 회사명과 조정 EBITDA를 함께 쓰시오. )
● answer : Equinix, $901 million
● data_source_filenames :
- Copy of Digital-Realty-s-1Q23-Earnings-Press-Release.txt;
- Copy of Equinix Q3 2023 Press Release and Financials.txt;
- Copy of Equinix Q1 2023 Press Release and Financials.txt;
- Copy of Digital-Realty-2Q23-Earnings-Press-Release-FINAL.txt;
- Copy of Digital-Realty-3Q23-Earnings-Press-Release.txt;
- Copy of Equinix Q2 2023 Press Release and Financials.txt
● data_source_urls : (생략)
● input_tokens : 95,247
위 문제는 회사 문서 분류의 문서 세트에 대해 만들어진 문제이다. data_source_filenames을 살펴보면 이 파일들은 Digital Realty라는 기업과 Equinix라는 기업의 2023년도 1~3분기 실적 자료로 추정된다. AA-LCR에서는 여러 분기 자료를 함께 묶어 놓고 이전 분기 대비 영업이익의 변화율과 adjusted EBITDA 등의 재무지표를 추론하게 하고자 한 것으로 보인다.
[ 다른 유형들의 예시 문제 ]
● 재무 분석 및 비교 지표(Financial Analysis and Comparative Metrics): 재무 데이터를 추출하고 성과 지표를 계산한다.
● 법률 및 규제 해석(Legal and Regulatory Interpretation): 제외 규정에 따라 해당 사례나 정책을 식별하고, 그 결과와 적용 가능성을 해석하며, 인용된 조항이나 정의를 찾아낸다.
● 다문서 정보 종합(Multi-Document Information Synthesis): 여러 문서에 흩어져 있는 정보를 찾아 연결하여, 주제를 파악하고 데이터 포인트 간의 상관관계를 도출한다.
● 시간적·조건적 논리 분석(Temporal and Conditional Logic Analysis): 시계열 추세를 추적하고, 조건부 의사결정 규칙을 적용하며, 임계값 기반의 경고나 조치를 판단한다.
● 연구 및 분류(Research and Classification): 패턴을 분석하고, 관련 문서를 분류·식별하여 특정 정보를 찾아낸다.
3. 데이터셋 구축 방법
AA-LCR은 Artificial Analysis 연구팀과 10여 명의 학부생들이 함께 참여해 질문 작성 및 엄격한 검증 과정을 거쳐 제작하였다.
데이터셋 크게 문서 선정(Document Curation), 질문 제작(Question Creation), 사람의 검증(Human Validation) 과정을 거쳐 만들어진다.
먼저, 문서들은 앞서 살펴봤던 것처럼 다양한 출처를 바탕으로 수집되었으며, 실제로 사람들이 일을 할 때 분석의 대상으로 삼는 자료들을 대표할 수 있도록 구성되었다.
다음으로 질문은 다양한 전공의 학부생들이 제작하였으며 non-frontier 모델들을 사용해서 질문의 난이도를 검증하며 문제를 제작했다. 문제의 난이도 검증에는 GPT-4o-mini, Llama-3.1-70B, Gemini 1.5 Flash 등의 non-frontier 모델이 사용되었다. 이를 통해 frontier 모델에 접근하지 않으면서도 AI의 전반적인 성능 수준을 고려하며 문제를 만들 수 있도록 했다. 또한 frontier 모델에 불리하게 작용하는 adversarial selection을 방지하기 위한 목적도 있다. 각 문제는 앞서 설명했듯 여러 문서에 걸친 추론이 필요하도록 구성되었으며, 이와 동시에 non-frontier 모델들이 정답을 맞히지 못할 만큼의 어려운 문제로 구성되도록 했다.
마지막으로 사람의 검증 단계는 다음과 같이 이루어졌는데, 요약하자면 사람이 풀어봤을 때 충분히 어려우면서도 타당하고 명확한 정답을 가진 문제인지 확인하는 과정을 거친 것이다.
- 평가자들은 AI 모델에 제공된 것과 동일한 문서 세트를 사용하여 질문에 답한다.
- 평가자들의 첫 시도 정답률은 보통 40~60% 수준으로 그다지 높지 않았는데, 이는 이 벤치마크가 충분히 challengeable함을 보여준다.
- 평가자들에게 정답이 보여줬을 때 평가자들은 대개의 경우 정답의 타당함을 인정했다. 이는 각 질문이 어렵기는 하지만 명확하고 설명 가능한 정답을 가짐을 의미한다.
- 검증에 실패한 질문은 수정 또는 삭제되었다.
- AA-LCR의 모든 질문은 최소 한 명 이상의 평가자가 정답을 맞힌 문제로, 모든 질문에 대해 검증된 해답이 존재한다.
이러한 검증 과정은 AA-LCR이 모델의 특수한 지식 보유 여부를 확인하는 것이 아닌 실질적인 추론 능력을 평가하고 있음을 뒷받침한다. 또한 Long Context Reasoning이 인간에게도 본질적으로 어려움을 보여준다.
4. 데이터셋 평가 방법
AA-LCR에서는 모델의 성능을 평가할 때, 프롬프트에 문서 세트 + 질문을 한번에 넣어준다. 아래의 코드에서 확인할 수 있듯이 여러 문서의 본문을 하나의 긴 문자열(docuents_text)로 합친 후 프롬프트에 질문과 함께 넣어주고 있다.
documents_text = "\n\n".join(f"BEGIN DOCUMENT {i + 1}:\n{doc}\nEND DOCUMENT {i + 1}" for i, doc in enumerate(docs))
prompt = """BEGIN INPUT DOCUMENTS
{documents_text}
END INPUT DOCUMENTS
Answer the following question using the input documents provided above.
START QUESTION
{question}
END QUESTION
"""
추가로 AA-LCR에서는 모델에 넣어주는 문서를 불러오는 순서도 중요하다고 언급했다. 문서들은 data_source_filenames에 나열된 파일명 순서대로 프롬프트 템플릿에 추가되어야 한다고 한다. 그 이유는 따로 명시되어 있지 않으나, 모델의 성능을 재현하기 위함으로 추측해볼 수 있다.
AA-LCR 벤치마크에서는 숫자, 단답형, 약술형 등이 답안으로 등장하는데 이때 모델의 답을 사람이 채점하지 않고, LLM 기반 equality checker를 사용하여 채점한다. LLM 기반 equality checker는 단순히 문자열을 비교하는 것이 아니라 그 안에 담긴 의미를 바탕으로 답안을 비교하여 채점한다. 채점에는 Qwen3 235B A22B 2507 Non-reasoning 모델이 사용되었다. 채점 모델에 사용된 프롬프트는 다음과 같다. 질문, 공식 정답, 모델이 예측한 정답을 주고 정오답을 판별하도록 하고 있다.
Assess whether the following CANDIDATE ANSWER is CORRECT or INCORRECT.
For the CANDIDATE ANSWER to be correct, it must be consistent with the OFFICIAL ANSWER.
The question, for reference only: {question}
The OFFICIAL ANSWER: {official_answer}
CANDIDATE ANSWER TO ASSESS: {candidate_answer}
Reply only with CORRECT or INCORRECT.
5. AI 모델들의 벤치마크 성적
GPT-5.2 Codex(xhigh)가 75.7%로 가장 높은 성적을 기록했으며, 그 뒤로 GPT-5(high)가 75.6%, GPT-5. (high)가 75.0%를 기록했다.
1) Frontier 모델 간 비교
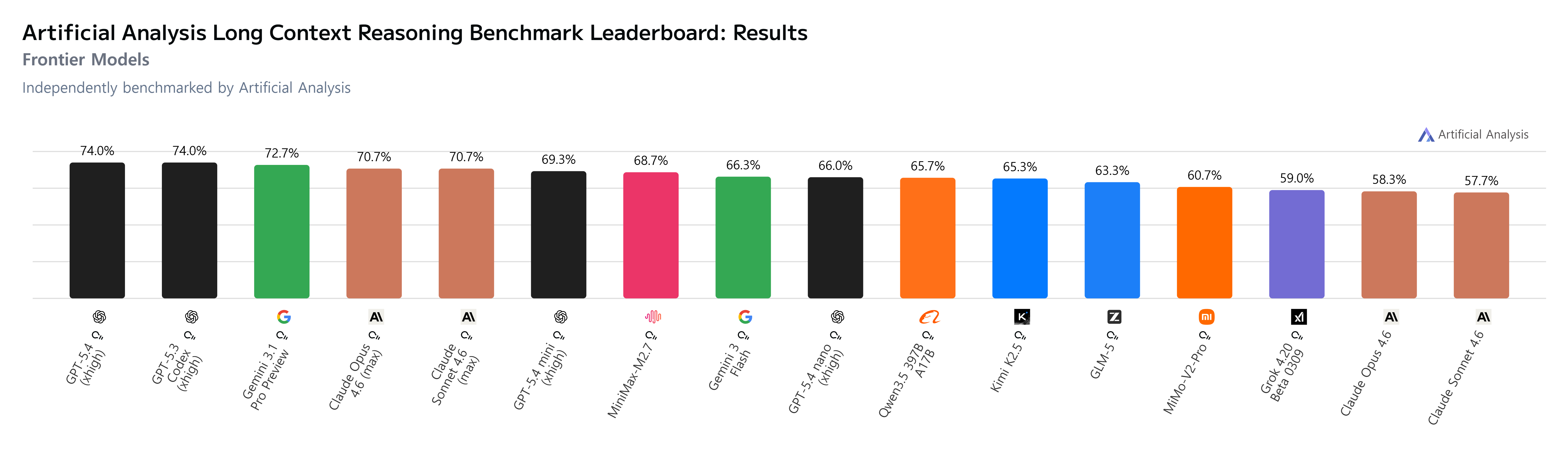
GPT 계열의 프론티어 모델들이 74.0%로 Frontier 모델들에서 우수한 성능을 보이고 잇다. 다른 모델들도 70% 부근의 성능을 보이며 전반적으로 나쁘지 않은 수준의 Long Context 추론 능력을 가지고 있다고 볼 수 있다.
2) 한국 모델 간 비교

한국 모델의 경우 LG AI 연구원의 K-EXAONE(Reasoning) 모델이 55.7% 가장 우수한 성능을 보였다. EXAONE 4.0 32B에서도 Reasoning 모델이 Non-Reasoning보다 성능이 우수했다. Solar Open 100B 모델은 36.0%의 성능을 보였으며, 네이버와 KT의 모델들은 10% 수준의 성능에 머물렀다.
3) Qwen 모델 성능 비교

Qwen3.5 모델을 중심으로 비교했다. 27B, 9B, 4B 모델에 대해 각각 Reasoning과 Non-Reasoning 모델을 비교했다. 전반적으로 모델의 크기가 클수록 성능이 좋으나, 9B-Reasoning이 27B-Non-Reasoning보다 성능이 좋고, 4B-Reasoning이 9B-Non-Reasoning보다 성능이 좋은 등 모델 크기보다 Reasoning 모드 활성화 여부가 AA-LCR 성능에 더 큰 영향을 미칠 수 있음을 확인할 수 있었다.
4) Gemma 모델 성능 비교

Gemma 모델의 경우 최고 성능이 6.7%로 비교적 성능이 좋지 않았다. 12B 모델이 27B 모델보다 성능이 좋았으나, 두 모델의 성능이 모두 10%에 미치지 못하고 있는 수준으로 모델의 크기와 성능을 논하기는 어렵다고 생각한다.
5) Llama 모델 성능 비교

| 모델 | 총 파라미터 | 활성 파라미터 | AA-LCR |
| Llama 4 Scout | 109B | 5B | 25.8% |
| Llama 4 Maverick | 400B | 17B | 46.0% |
| Llama 3.1 405B | 405B | 405B (dense) | 24.3% |
Llama 모델의 경우 Llama 4 Maverick 모델이 46.0%로 가장 높은 성능을 기록했다. Llama 4 Scout의 경우 3.1의 405B 모델보다 규모는 훨씬 작지만 성능이 비슷함을 확인할 수 있다. 활성 파라미터의 수와 성능 지표를 고려했을 때, Llama 4에서 도입한 MoE 구조가 효율성 측면에서 일정한 효과를 보임을 분석해볼 수 있다. 3.2 11B 모델의 경우 모델이 멀티모달 기능이 추가된 대신 규모가 더 작은 3.1 8B보다 성능이 좋지 않은 것을 확인할 수 있다. 또한 3.1의 405B를 축약한 3.3 70B의 경우 그 성능이 많이 저하되었음을 확인할 수 있다.
[ MoE(Mixture of Experts)란? ]
: "전문가들의 혼합"이라는 뜻으로, 모델 내부를 여러 개의 전문가(Expert) 서브네트워크로 나누고, 입력이 들어올 때 그 중 일부만 선택적으로 활성화하는 구조이다.
6. Long Context Reasoning을 측정하기 위한 기술 기반
AA-LCR 벤치마크는 질문 하나당 입력 토큰이 약 10만 토큰이기 때문에, 이 벤치마크를 활용하기 위해서는 모델이 최소 128K의 context window를 지원해야 한다. 모델이 이처럼 긴 컨텍스트를 처리할 수 있으려면 위치 인코딩 기술이 뒷받침되어야 하며, 대표적인 기술 계보는 다음과 같다.
- RoPE: 위치 정보를 "회전"으로 표현한 기본적인 위치 인코딩 방식. 단, 학습 범위 밖 길이에서 성능 급락
- NTK-aware RoPE: 베이스 값을 조정하여 각 차원의 주파수를 비선형적으로 변환함으로써 RoPE 확장 시 고주파 정보 손실 문제를 해결. 단, 너무 긴 컨텍스트에서는 여전히 성능 저하
- YaRN: 주파수 구간 분리하고 Temperature를 보정하여 NTK-aware RoPE 대비 컨텍스트 창을 더 안정적으로 확장.
7. 논문에서 AA-LCR이 평가 지표로 활용된 사례
AI Agentic Programming: A Survey of Techniques, Challenges, and Opportunities
AI Agentic Programming: A Survey of Techniques, Challenges, and Opportunities
AI agentic programming is an emerging paradigm where large language model (LLM)-based coding agents autonomously plan, execute, and interact with tools such as compilers, debuggers, and version control systems. Unlike conventional code generation, these ag
arxiv.org
위 연구는 AI Agentic Programming 분야의 서베이 논문이다. 본 논문에서는 AI Agentic Programming 분야의 주요 도전 과제 중 하나로 Long Context 처리의 한계를 언급하고 있다. 이 때, Long Context 처리를 평가하기 위한 지표로 연구진이 AA-LCR을 언급하였다. AI 코딩 에이전트가 대규모의 코드베이스, multi-turn 대화 기록, 여러 도구의 출력 등을 동시에 처리했어야 한다는 점에서 AA-LCR의 평가 구조가 이러한 측면의 성능을 평가하고 현재 모델들의 한계를 보여줄 수 있다고 언급했다. SWE-bench나 HumanEval 같은 기존 코딩 벤치마크는 단일 파일 수준의 짧은 컨텍스트를 다루는 데 그치기 때문에, Long Context 추론 능력 측정을 위한 보완적 벤치마크로 AA-LCR이 언급되었다.
이는 AA-LCR이 단순한 문서 이해 능력 측정을 넘어, AI 에이전트가 실제 프로그래밍 작업을 수행하는 데 필요한 Long Context 추론 역량을 평가하는 벤치마크로 활용될 수 있음을 시사한다.

