
https://arxiv.org/abs/2311.12022
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
We present GPQA, a challenging dataset of 448 multiple-choice questions written by domain experts in biology, physics, and chemistry. We ensure that the questions are high-quality and extremely difficult: experts who have or are pursuing PhDs in the corres
arxiv.org
1. 데이터셋 구성 의의
AI 모델의 성능이 증가함에 따라, 인간이 진실을 쉽게 검증할 수 없는 문제에 대한 인공지능의 대답을 평가하기 위한 벤치마크가 필요해짐. 이 문제를 scalable oversight라고 부름. 이런 문제는 고도로 학습된 비전문가들도 스스로 풀기 어려운 문제여야 제대로 된 평가가 가능함.
RLHF(Reinforcment learning from human feedback)과 같은 현존하는 oversight 방법들은 human annotators의 능력에 따라 LLM의 출력의 정답 여부가 다르게 평가될 수 있음.
저자들은 human annotators가 출력의 정답 여부를 제대로 판단할 수 없는 상황에서의 scalable oversight 방법론에 대해서 연구하기 위해서는, 특정 전문가들은 답을 알지만, 고도로 학습되고, 접근할 수 있는 자료가 충분한 비전문가들은 풀지 못하는 문제로 AI를 평가해야 한다고 생각했음.
→ GPQA 데이터셋 제작
- 448문제
- 대학원 수준의 다지선다 문제
- 도메인: 물리학, 화학, 생물학
- GPQA Extended 기준(문제수)
- 생물학: 분자생물학(85), 유전학(20)
- 물리학: 양자역학(64), 고에너지 입자 물리학(46), 물리학 일반(43), 천체물리학(42), 전자기학 및 포토닉스(12), 상대론적 역학(11), 통계역학(4), 응집물질 물리학(4), 광학 및 음향학(1)
- 화학: 유기화학(144), 화학 일반(64), 무기화학(3), 분석화학(2), 물리화학(1)
- GPQA Extended 기준(문제수)
- 다른 도메인에서 PhD를 갖고 있거나 그 과정에 있는 non-expert(비전문가)에게도 어려운 문제임을 보장.
- 해당 분야의 Experts는 65%의 정답률
- 비전문가들은 34% 정답률
- GPT-4의 Few-shot prompting 39%의 정답률
- Random Chance는 25%(4지선다 문제이기 때문에)
→ 그 중에서 198개의 고품질 문제를 추출한 것이 GPQA Diamond
- 전문가들은 옳게 대답하고, 비전문가들은 틀린 문제만을 모음.
2. 데이터셋 예시

천문학자들은 유효온도 가 약 6000K인 한 별을 연구하고 있다. 이들은 두 화학 원소 El1과 El2의 스펙트럼 선(EW < 100 mÅ)을 이용하여 분광학적으로 별의 표면중력을 결정하고자 한다. 해당 별의 대기 온도 조건에서 El1은 대부분 중성 상태로 존재하며, El2는 대부분 이온화된 상태로 존재한다. 이때, 천문학자들이 표면중력에 가장 민감한 스펙트럼 선으로 고려해야 할 것은 무엇인가?
A) El2 I (중성 상태)
B) El1 II (단일 이온화 상태)
C) El2 II (단일 이온화 상태)
D) El1 I (중성 상태)

- 유기화학 문제 예시
- 번역 버전
메틸사이클로펜타디엔(여러 이성질체가 빠르게 상호 전환되는 fluxional 혼합물로 존재함)을 메틸 아이소아밀 케톤과 촉매량의 피롤리딘과 반응시켰다. 그 결과, 밝은 노란색의 교차 공액(polyalkenyl) 탄화수소 생성물이 형성되었으며(이성질체 혼합물), 이 과정에서 물이 부생성물로 생성되었다. 이 생성물들은 풀벤(fulvene) 유도체이다. 이렇게 생성된 생성물을 이후 에틸 아크릴레이트와 1:1 몰비로 반응시켰다. 반응이 완료되었을 때, 생성물의 밝은 노란색은 사라졌다. 이 최종 생성물을 구성하는 화학적으로 구별되는 이성질체의 개수는 몇 개인가? (※ 입체이성질체는 제외하고 센다.)
A) 2
B) 16
C) 8
D) 4
3. 데이터셋 관련 통계
- GPQA - 448문제
- 전문가 정답률: 71.9%
- 비전문가 정답률: 30.4%
- 전문가가 충분한 도메인 지식을 가지고 답했는지: 93.5%
- GPQA Diamond - 198문제
- 전문가 정답률: 81.3%
- 비전문가 정답률: 22.1%
- 전문가가 충분한 도메인 지식을 가지고 답했는지: 97%

4. 데이터셋 벤치마크 성적
GPQA Diamond Benchmark Leaderboard | Artificial Analysis
Compare AI model performance on GPQA Diamond Benchmark Leaderboard. The most challenging 198 questions from GPQA, where PhD experts achieve 65% accuracy but skilled non-experts only reach 34% despite web access.
artificialanalysis.ai
- Llama 모델의 Parameter 수에 따른 성적 비교

- Llama 4: Maverick (67.1%), Scout (58.7%)
- 초거대 모델: Llama 3.1 405B (51.5%)
- 중대형 모델 (70B/90B): Llama 3.3 70B (49.8%), Llama 3.2 90B Vision (43.2%), Llama 3.1 70B (40.9%), Llama 3 70B (37.9%)
- 소형 모델 (3B/8B/11B): Llama 3.1 8B (25.9%), Llama 3.2 3B (25.5%), Llama 3.2 11B Vision (22.1%)
- 파라미터 수에 비례함: 동일 세대 내에서 파라미터가 커질수록 점수가 우상향하는 뚜렷한 경향을 보임 (예: Llama 3.1 8B(25.9%) → 70B(40.9%) → 405B(51.5%)). 박사 수준의 고난도 문제 해결에는 거대한 체급(지식 용량)이 필수적임.
- 세대에 따른 성능 향상: 동일 파라미터(70B)라도 세대가 진화할수록 성적이 상승함 (Llama 3(37.9%) → 3.1(40.9%) → 3.3(49.8%)). 후속 세대일수록 학습 데이터 질과 추론 능력이 고도화됨.
- 최신 모델이 강: 최신 Llama 4 라인업(Maverick, Scout)은 기존 초거대 모델(405B)을 뛰어넘어 60% 후반대의 최고 성적을 기록함.
- 소형 모델의 한계: 8B 이하 소형 모델의 정답률은 25% 내외로, 4지선다 무작위 찍기 확률(Random Chance, 25%)과 유사함. 작은 모델은 GPQA 문제의 논리를 전혀 파악하지 못하고 있음을 의미함.
2. Qwen 모델의 Parameter 수에 따른 성적 비교

- 최상위 모델: 60.4%, 58.9%, 53.5%
- 중상위 모델: 47.0%, 45.2%, 35.6%
- 소형 모델 (1.7B, 0.6B 등): 28.3%, 23.9%, 23.1%
파라미터 수에 따른 성능 격차가 매우 뚜렷함. 초소형 모델은 정답률 23%대로 무작위 찍기(25%)를 밑돌지만, 상위 모델은 60.4%까지 급상승함.
- Qwen 최상위 모델(60.4%, 58.9%)은 Llama 3.1 405B(51.5%)를 뛰어넘는 강력한 퍼포먼스를 보임. 체급 대비 과학 도메인 지식과 복잡한 논리 추론 학습이 고도로 효율적임을 시사함.
소형 모델은 인간 비전문가(22.1%)와 유사한 수준이나, 중상위권 모델부터는 비전문가의 수준을 초월함. 진정한 'Scalable Oversight(인간의 평가 범위를 벗어난 AI)' 영역에 진입했음을 보여줌.
3. 한국 파운데이션 모델

- K-EXAONE (78.3%), EXAONE 4.0 32B (73.9%)가 높은 정답률
- 한국 파운데이션 모델 중에서도 대규모 모델 + 강한 추론 튜닝이 고난도 과학 문제 해결에 효과적임을 시사
- EXAONE 내에서 32B > 7.8B > 1.2B 순으로 성능 하락, 파라미터 수의 증가와 Accuracy 개선의 강한 상관관계
해당 데이터 GPQA Diamond처럼 전문가 집단 수준의 벤치마크에서는 소형 모델의 성능 한계가 명확히 드러난 것으로 판단
모델 계열 간의 비교로는 EXAONE / K-EXAONE / Midm 계열이 HyperCLOVA X 대비하면 전반적으로 높은 Accuracy를 보임.
HyperCLOVA X SEED Think (32B)는 61.5%로, 사이즈가 큰 모델임에도 불구하고 과학 전문가 분야에서는 상대적으로 낮은 성능을 보임.
4. Gemma 파라미터별 비교

파라미터 증가에 따른 일관된 성능 개선
- 파라미터 수가 증가할수록 Accuracy가 일관되게 상승
- 1B → 4B → 12B → 27B로 갈수록 성능 하락 없이 꾸준한 개선이 관측됨.
- 최고 성능 보여준 Gemma 3 27B (42.8%)도 전문가 수준과 큰 격차가 존재. 같은 파라미터 규모의 일부 다른 오픈소스 모델 대비 떨어지는 추론 성능을 보임.
- GPQA Diamond는 데이터 특성 상 단순 지식 추론 및 암기가 아닌 깊은 도메인 이해가 필요하지만 Gemma는 안정성에 좀 더 포커스를 둔 모델이기 때문으로 추정
5. 주요 Frontier 모델 비교
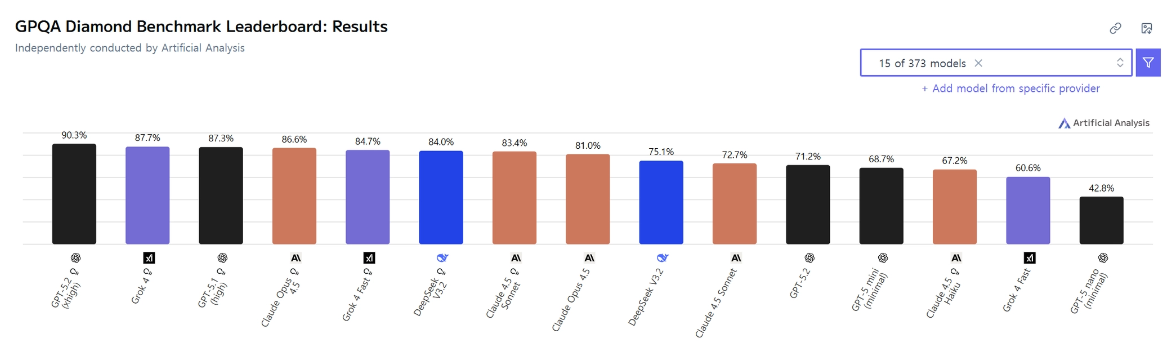
- Frontier 상위 모델들은 전문가 수준 추론 레벨
- GPT-5.2 (high), Grok 4, Gemini 3 (high)는
- 87~90%대 Accuracy로, 전문가 정답률(81%)을 상회하거나 근접함.
- 이는 일부 Frontier 모델이 전문가만 풀 수 있는 문제영역에서도 경쟁 가능한 수준을 입증
모델별 비교
- GPT-5.2 (high) → GPT-5.2 → GPT-5.1 (minimal) → GPT-5 nano
- 90.3% → 71.2% → 68.7% → 42.8%
- 일반(high) → 경량(minimal/nano)로 갈수록
추론 성능 하락
- Opus > Sonnet > Haiku
- 86.6% → 83.4% → 67.2%
- 모델 크기·추론 능력 감소
- Grok 4 > Grok 4 Fast
- 87.7% → 84.7% / 60.6%
- Fast(경량/저지연) 버전은 Accuracy 측면에서 떨어지는 경향
추가질의
1 .내가 맡은 벤치마크가, Parameter수가 늘수록 점수에 어떤 경향이 있는가? Llama/Qwen/Gemma 모델 패밀리에 따라서는 그 경향이 어떻게 바뀌는가?
세 패밀리 모두 파라미터가 증가할수록 성능이 개선되는 경향이 관측되며, Gemma는 단조 증가가 가장 뚜렷하고, Llama/Qwen은 모델 세대·변종·학습 레시피 요인이 함께 성능을 좌우한다.
2 .주요 Frontier 모델의 성적은 어떠한가? Open Source 최강자에 비해서는 어떠한가? GPT의 경우, 일반>Mini>nano로 갈때 성적 경향이 어떠한가? Claude의 경우 Opus>Sonnet>Haiku로 갈때 성적 경향이 어떠한가? Grok의 경우 Grok 4>Grok 4 Fast로 갈 때 성적 경향이 어떠한가? Google의 경우 Pro>Flash로 갈때 성적 경향이 어떠한가?
주요 Frontier 모델들은 80~90%대의 높은 정확도를 기록
일부 모델은 전문가 정답률에 근접하거나 이를 상회하는 성능 Open Source 계열의 최고 성능 모델(Llama, Qwen, Gemma 상위 모델)들은 대체로 60~70%로 Frontier 상위와는 격차가 뚜렷
즉, 고난이도의 GPQA Diamond에서는 Frontier 모델과 Open Source 모델 간의 성능 차이가 명확
3. 주요 Frontier 모델의 Reasoning 모드 킨것과 끈것의 차이는 어떠한가?
Reasoning 모드를 끈 경우에는 긴 추론 과정의 축소되면서, 오답률 증가
다단계 추론을 요구하는 GPQA Diamond 이기에 Reasoning을 적극적으로 활용하는 것이 성능에 영향을 미치는 양상
4. 한국 파운데이션 모델의 성적은 어떠한가?
대형 모델(K-EXAONE, EXAONE 32B, Midm 계열)은 오픈소스 대형 모델과 비교해 경쟁력 있는 성능을 보이지만, Frontier 최상위 모델이 기록하는 80~90%대 정확도와는 여전히 일정한 격차가 존재
한국 파운데이션 모델 역시 파라미터 수 증가에 따른 성능 개선이 뚜렷하게 나타남으로써 고난도 벤치마크 데이터셋에서의 대형 모델과 추론 최적화의 중요성을 입증
5. 데이터셋 구축 방법론
- 문제 출제자, 검증을 위한 전문가, 검증을 위한 비전문가는 Upwork를 통해 총 61명을 모집.
- 해당 인원들은 전부 PhD를 수행했거나 수행하고 있는 인원이었으며, 영어에 능숙했음.
- Question Writing(문제 출제)
- 전문가는 풀 수 있는데, 비전문가는 못푸는 문제를 출제하도록 함.
- 정답에 대한 설명과 오답에 대한 설명을 작성하도록 함. 질문의 subdomain 작성.
- 각 질문마다 기본 10달러 + expert validators(2명)가 정답을 맞히면 각각 20달러 + 3명의 non-expert validators가 틀릴 때마다 15달러 + (Extra) 2명의 expert validators가 모두 정답이고, 2/3 non-expert validators가 오답이면 30달러
- First Expert Validation(첫번째 전문가 검증)
- 문제에 답하고, 해당 문제가 객관적인지, 정확한지, 어려운지 검증
- 10달러 기본급 + 정답을 맞히면 10달러 + 두번째 expert validator가 정답을 맞히면 10달러(피드백이 실제 문제의 질 향상에 도움이 되게 하기 위해) + 2/3 이상의 non-expert validators가 오답이면 5달러(문제의 난이도를 상승시키기 위해)
- Question Revision(문제 수정)
- First expert validator의 피드백을 보고 문제를 수정하거나 수정하지 않을 수 있는 단계.
- Second Expert Validation(두번째 전문가 검증)
- 수정된 문제를 풀고, 피드백. 그러나 피드백으로 문제가 수정되지는 않으며, 해당 expert validator가 문제를 틀린 이유가 실수인지 문제 오류인지 검증하기 위함임.
- 피드백 정량화

5. Non-Expert Revision(비전문가 검증)
- 다른 도메인에서 PhD를 하고 있거나 했던 사람들.
- 시간제한 없음 + 인터넷에서 정보 검색 가능.
- 순수 일반적인 인간의 능력을 평가하기 위해서 LLM 사용은 제한.
- 10달러 기본급 + 문제를 맞히면 30달러
- 한 문제 당 최소 15분 이상 문제를 풀기를 희망 → 평균적으로 한 문제 당 37분 소요
- 자신의 전문 분야와 관련된 분야에서는 문제 풀이에 참여 불가.

6. 관련 연구
1) MMLU / BIG-Bench 계열
https://arxiv.org/abs/2009.03300
https://arxiv.org/pdf/2206.04615
- MMLU: 다수 학문 분야의 객관식 문제를 통해 LLM의 범용 지식을 평가
- BIG-Bench / BIG-Bench Hard: 다양한 추론·창의 과제를 포함
- 고성능 LLM에서는 정답률이 상향 평준화
- 비전문가도 정답 검증이 가능 →모델 간 상대 비교에는 유용하지만, human oversight이 한계에 도달하는 지점을 측정하기엔 부족https://arxiv.org/abs/2406.01574
- MMLU-Pro: MMLU를 정제하여 난도 상승
- MedQA / LawBench 등 전문 영역 벤치마크
- MMLU-Pro, 전문 도메인 벤치마크
- 모델이 정말 아는지 그럴듯하게 맞춘 것인지, 즉 환각 구분 어려움
- 특정 도메인(의학·법률)에 편중
- Open-book 환경에서 검색 능력에 크게 의존
- 비전문가가 검증 불가능한 문제라는 조건이 명확히 설계되지 않음
Human-in-the-loop / RLHF 평가의 한계
RLHF 기반 평가 문제
- LLM 출력의 품질을 human annotator가 판단
- 모델 성능이 높아질수록:
- 인간이 정답 여부를 판단하기 어려운 문제 증가
- 평가 신뢰도가 떨어짐
이 문제를 Scalable Oversight 문제라고 부름
Scalable Oversight 관련 연구
- Debate, Recursive Reward Modeling, Weak-to-Strong Generalization 등
- 공통 질문:GPQA는 Scalable oversight 문제가 실제로 발생하는 영역을
- 정량적으로 측정할 수 있도록 설계된 최초의 실증적 벤치마크 중 하나
- 약한 감독자(인간 또는 약한 모델)가 강한 모델의 출력을 어떻게 평가할 수 있는가?
7. 평가방법론
- 4지선다 문제
- Model에 대해서 closed-book(외부 자료 접근 불가능) / open-book(외부 자료 접근 가능) 방식으로 각각 성능 측정
- Closed-book 평가
- Baseline models: Llama-2-70B-chat, GPT-3.5-turbo-16k, GPT-4
- Prompting: zero-shot, few-shot, zero-shot chain-of-thought, few-shot chain-of-thought
- Few-shot prompting example로 문제 출제자가 적은 설명을 사용. 이를 reasoning chain으로 사용.
- Open-book 평가
- Self-ask GPT-4 + 인터넷 액세스 허용
8. 실험

- GPQA Diamond Set을 기준으로 했을 때 성능은 Non-expert human validators(21.9%) < Closed-book AI(≤38.8%) ≤ Open-book AI(38.8%) < Expert human validators(81.2%)
9. 한계점
데이터 규모
- GPQA Diamond는 198문제로 구성됨
- 대규모 벤치마크(MMLU 등)에 비해 문항 수가 적음
disadvantage
- 통계적 분산이 클 수 있음
- 세밀한 모델 간 차이를 일반화하기에는 한계
- 전문가 출제 + 다단계 검증이라는 고비용 제작 파이프라인의 결과
- 저자들은 quantity보다 quality을 의도적으로 선택했다고 명시
도메인 범위에 따른 일반화의 어려움
- 물리학 / 화학 / 생물학 중심
- 수학, 공학, 사회과학, 인문학은 포함되지 않음
결과
- “GPQA 성능 = 모든 지식 추론에서의 능력으로 일반화 불가
- 다른 전문 도메인에서는 별도의 GPQA-style 벤치마크 필요
MCQ(Multiple Choice Question) - 객관식
- 4지선다 MCQ
- 제거법(test-taking strategy) 가능
- 부분적 추론이나 운적인 요소가개입될 여지가 존재
이를 개선하려면
- 자유서술형/단답형이 이상적일 수 있으나,
- 자동 채점
- 전문가 합의
- 비용 문제 때문에 MCQ 선택하였다고 함

