
An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling
For most deep learning practitioners, sequence modeling is synonymous with recurrent networks. Yet recent results indicate that convolutional architectures can outperform recurrent networks on tasks such as audio synthesis and machine translation. Given a
arxiv.org
0.BEFORE
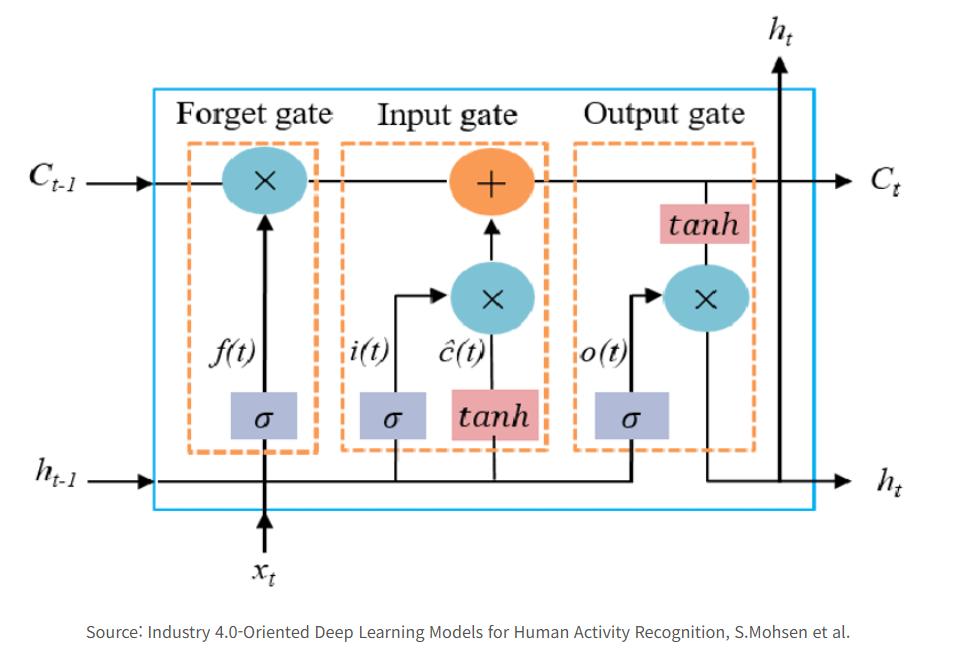
LSTM
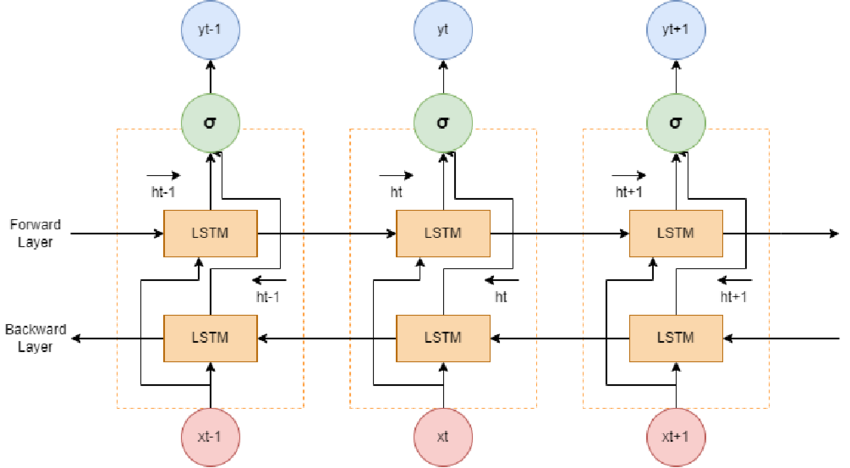
Bidirectional LSTM
1. Introduction
Sequence 데이터를 처리할 때 관행적으로 convolution 모델 대신에 recurrent model을 사용하는 경우가 많습니다.
하지만 오디오 합성이나 기계 번역 등의 분야에서 RNN을 능가하는 Convolution 모델들이 나오고 있습니다.
이 연구팀은 Convolution 모델이 특정 분야의 sequence data에서만 유효한 성능이 다른 영역에서도 적용될 수 있는지를 실험하고자 합니다.
2.Background
Sequence modeling 작업으로 RNN이 인기가 많지만 학습이 어렵기 때문에 이를 보완한 LSTM이나 GRU를 많이 사용합니다.
기존에도 RNN 아키텍처 간의 비교 연구는 많았지만 일반적인 convolution 아키텍처와 recurrent 아키텍처를 시퀀스 모델링 작업 에 대해 비교한 연구는 없었습니다.
이 연구는 sequence를 요소별로 합성하여 다음 sequence를 만들어 내는 작업에서의 비교에 집중하고자 합니다.
3. Temporal Convolutional Networks
3-1. Sequence Modeling
TCN은 sequence model이기 때문에 t시점에서의 결과 sequence는 t 시점까지 입력된 sequence만을 이용하여 산출합니다.
이를 위해 다음과 같은 2가지 제약 조건을 설정합니다.
1. 입력 sequence와 출력 sequence의 길이가 같습니다.
2. y_t를 산출할 때 x_t+1... x_n을 반영하지 않습니다.
3-2. Casual Convolutions
TCN은 FCN(1D-fully-convolutional network)을 사용합니다. 이때 입력 sequence의 길이와 출력 sequence의 길이가 동일해야 하고 hidden layer의 sequence의 길이도 동일해야 합니다. 이를 위해 zero padding이 이용됩니다.
또한 casual convolution을 이용하여 TCN = 1D-FCN+Casual convolution의 형태로 TCN을 구성합니다.
3-3. Dilated Convolutions
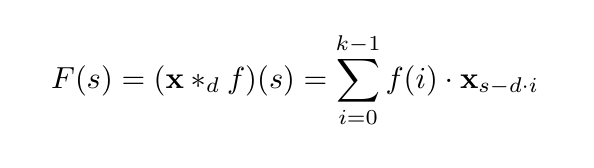
위 식에서 변수의 의미는 다음과 같습니다.
s: 시점입니다.
x: 입력 시퀀스 데이터입니다.
f: 학습되는 필터입니다.
k: 필터의 크기를 의미합니다.
d: 팽창 계수(Dilation factor)입니다.
s: 시점입니다.
특정 시점에 대해서 커널 크기 k에 맞추어 i가 증가하며 연산을 진행합니다.
이때 팽창 계수 d는 i가 1만큼 증가할 때 몇번의 시점만큼 이동하여 커널에 적용할까 결정합니다.
즉 d가 클 수록 더 과거의 정보를 반영한다고 해석할 수 있습니다.
이때 d를 지수적으로 증가시키면 적은 층으로 긴 역사(large effective history)를 반영할 수 있다는 장점이 있습니다.

위의 사진처럼 d가 증가할수록 더 오래된 과거의 정보를 반영할 수 있음을 알 수 있습니다.
3-4. Residual Connections
TCN은 긴 sequence data를 처리해야 하므로 매우 깊은 convolution network의 형태를 가져야 합니다. 이를 위해 TCN은 residual한 구조를 가집니다.
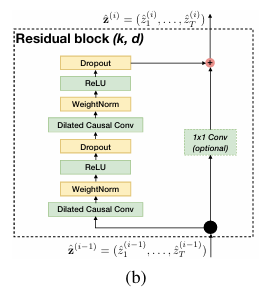
그림과 같이 TCN의 residual block은 확장된 Casual Convolution layer 후 가중치 정규화를 진행합니다. 그 이후 비선형성을 위해 ReLU를 진행하고 spatial dropout을 전체적으로 2번에 걸쳐 진행하는 방식으로 진행하고, 마지막에 입력 sequence에 convolution을 진행한 data를 더하는 것으로 전차과정을 수행합니다. 이때의 convolution은 채널의 수를 맞추기 위한 과정입니다.
3-5. Discussion
TCN은 다음과 같은 장단점을 가집니다.
Parallelism
RNN과 다르게 TCN은 모든 시퀀스를 동시에 병렬적으로 같은 필터를 통해 처리할 수 있습니다.
Flexible recptive field size
TCN은 다양한 크기의 convolution layer, dilation factors, filter 을 조절할 수 있습니다.
Stable gradient
Rasidual block의 특성 덕분에 gradient가 매우 커지거나 사라지는 것을 막을 수 있습니다.
Low memory requirement for trainning
수많은 gate들의 부분 결과값들을 저장해야 하는 LSTM이나 GRU와는 다르게 TCN은 층 내부에서 공유되기 때문에 메모리 사용량이 적습니다.
Variable length inputs
1D convolutional kernels를 통해 RNN처럼 다양한 임의의 길이 시퀀스를 받을 수 있습니다.
Data storage during evaluation
RNN과 다르게 TCN은 평가를 위해 입력 데이터 원본 길이의 시퀀스를 전부 받아야 하므로 많은 메모리가 요구됩니다.
Potential parameter change for transfer of domain
기존의 학습된 데이터들과 다른 영역의 입력 데이터들이 들어온다면 충분학 학습이 진행되지 않았을 때 좋지 못한 결과를 얻을 수 있습니다.
4. Sequence Modeling Tasks
TCN을 기존의 RNN에서 자주 이용되는 benchmark를 통해 나온 수치를 LSTM, GRU, RNN을 비교한 결과는 다음과 같습니다.

이때 이 benchmark는 Synthetic Stress Tests와 Real-world Data로 나눌 수 있습니다.
Synthetic Stress Tests
Adding problem, Seq. MNIST, Permuted MNIST, Copy memory
Real-world Data
Music JSB Chorales, Music Nottingham, Word-level PTB, Word-level Wiki-103, Word-level LAMBADA, Char-level PTB, Char-level text8
이때 Synthetic Stress Test는 모델의 장기 기억 능력(Long-term dependency)를 평가하기 위해 Real-world Data는 실제 현실 데이터 처리 능력을 평가하기 위한 benchmark라 볼 수 있습니다.
5. Experiments
이 연구팀은 모든 실험에서 동일한 TCN 아키텍처를 사용하였으며 충분한 receptive field을 위하여 네트워크의 깊이 n과 커널의 크기 k만 변경하여 실험을 진행하였습니다.
지수적 확장을 위하여 팽창 계수를 2^i의 형태로 진행하였고, Adam optimizer를 학습률 0.002로 설정하고 실험을 진행하였습니다.
또한 Gredient Clipping을 [0.3,1]로 설정하였습니다.
또한 RNN의 경우 TCN과 비슷한 파라미터 수를 맞춘 후 그리드 서치를 통해 하이퍼파라미터를 설정하였습니다.
5-1. Synthetic Stress Tests


위의 그래프들은 Synthetic Stress Tests들의 결과를 그래프로 나타낸 것입니다.
Adding problem에서는 모든 모델들의 파라미터를 70k로 설정하고 실험을 진행하였을 때 TCN이 가장 빨리 loss가 감소한 것을 알 수 있습니다.
MNIST에서도 역시 모든 모델들의 파라미터를 70k로 설정하고 실험을 진행하였을 때 TCN이 recurrent 모델들을 능가하는 성능을 보였음을 알 수 있습니다.
Copy memory에서 비슷한 파라미터를 가진 recurrent 모델들에 비해 TCN이 가장 빨리 loss가 감소한 것을 알 수 있습니다. 이 실험에서는 EURNN을 도입하여 진행한 결과 T=500에서는 TCN과 EURNN이 비슷한 결과를 도출하였으나 T=1000에서 TCN이 더 좋은 성과를 냈음을 알 수 있습니다.
5-2. Polyphonic Music and Language Modeling
위에서 진행한 real world data를 다루는 실험들에 대한 결과를 polyphonic Music과 Language Modeling 분야로 나누어 설명하겠습니다. 자세한 수치는 위의 표에서 확인할 수 있습니다.
Polyphonic Music Modeling에서는 TCN이 가장 낮은 NLL 값을 가지는 것을 가지며 일반적인 TCN 모델이 가장 우수한 성능을 보임을 알 수 있습니다.
Language modeling에서는 Word-level language modeling과 Character-level language modeling 에서 Word-level PTB를 제외한 모든 실험에서 LSTM 및 GRU보다 더 낮은 Perplexity 가지며 일반적인 TCN 모델이 가장 우수한 성능을 보임을 알 수 있습니다.
5-3. Memory Size of TCN and RNNs
우리는 무제한 길이의 sequence에서 정보 기억력을 평가하기 위하여 section 5.1과 다르게 sequence의 맨 마지막 단어 10개의 정확도에 집중하여 관측합니다.
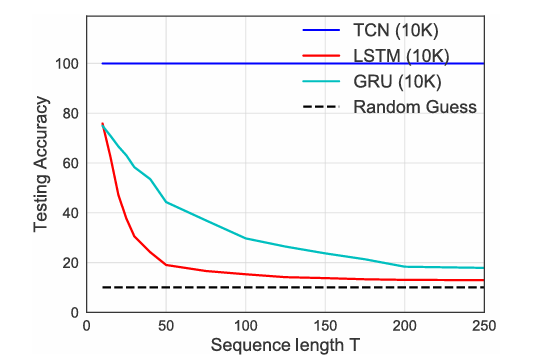
실험 결과는 위의 그래프와 같습니다.
Sequence의 길이가 증가함에 따라 TCN은 정확도가 100%로 유지되는 반면 recurrent 모델들은 random guess와 비슷한 수준으로 빠르게 감소하는 것을 알 수 있습니다.
이는 TCN이 장기 기억에 매우 강한 능력을 가지고 있음을 알 수 있습니다.
또한 이러한 결과는 광범위한 문맥을 처리해야하는 LAMBADA dataset에서 TCN이 가장 우수한 성능이 나온 결과와 일맥상통함을 알 수 있습니다.
6. Conclusion
사람들은 일반적으로 RNN이 sequential data를 다룰 때 더 우수할거라 생각합니다. 하지만 이 연구팀에서는 TCN에서 이용한 convolution 모델 만으로도 LSTM이나 GRU보다 우수한 성능의 장기 기억 전파를 할 수 있다는 것을 실험적으로 밝혀냈습니다.
최근에는 LSTM의 성능 향상을 위한 연구가 많이 진행되었으나 TCN을 비롯한 convolution 모델에 대한 연구는 이에 비해 부족하게 진행되었습니다. 이 연구팀은 TCN의 명확함과 단순성을 고려하였을 때 convolutional 모델이 recurrent 모델보다 더 강력한 아키텍처라 생각합니다.


