
GitHub - rajpurkarlab/CheXzero: This repository contains code to train a self-supervised learning model on chest X-ray images th
This repository contains code to train a self-supervised learning model on chest X-ray images that lack explicit annotations and evaluate this model's performance on pathology-classification ta...
github.com
- Nature Biomedical Enginerring 저널 2022년 발표 → 2021년 CLIP 모델
Abstract
- 의료 분야에서 의료 전문가의 성능을 능가하려면 전문가들이 주석을 단 관련 데이터셋으로 모델을 학습시켜야 해서 시간과 노력이 필요하여 고비용이 발생
- 레이블이 없는 데이터를 사용해 학습하기 위해 자기 지도 학습(self-supervised learning)을 적용
- 본 논문은 명시적인 주석이 없는 흉부 엑스레이 이미지로 훈련된 자기 지도 학습 모델이 방사선 전문의와 비슷한 정확도로 병리 분류 작업을 수행하였음
- 외부 데이터셋에서 자가 지도 학습 모델은 세 가지 병리(8가지 중)를 감지하는 데 있어 지도 학습 모델보다 우수한 성능을 보였고 모델 훈련에 명시적으로 주석이 달리지 않은 병리로 일반화된 성능을 보임

- [보고서 예시] Opacity in the right lower lung zone with sharp margin suggestive of lobar pneumonia ⇒ 우측 하부 폐 영역의 불투명도와 엽상 폐렴을 시사하는 날카로운 여백
Methods
Train Dataset
- MIMIC-CXR
- MIMIC-CXR은 377,110개의 흉부 X-ray 이미지와 해당 방사선 보고서(자유 형식의 임상 소견 요약)가 포함됨
- 한 검사에 여러 장의 흉부 X-ray 이미지가 포함된 경우, 전방이나 후방 시야의 이미지를 선택하여 훈련에 포함
- 각 방사선 전문의가 작성한 전체 보고서는 6개의 섹션(검사, 적응증, 인상, 소견, 기법, 비교)으로 구성되어 있음
- CheXpert
- CheXpert는 스탠포드 병원에서 수집된 65,240명의 환자, 224,316장의 흉부 X-선 이미지로 구성된 공개 데이터셋
- 14가지 다른 질환의 존재를 위해 라벨이 붙어 있음 (ex.무기폐, 심근비대, 부종 etc)
- 14가지 질환(ex. 무기폐, 심비대, 부종 등)에 대해 5명의 방사선 전문의가 소견에 대해 작성한 보고서를 활용
- 본 논문에서는 검증 데이터셋을 사용하여 모델의 각 질환별 예측 확률 임계값을 튜닝하는 데 활용하였으며 최종 평가는 CheXpert 테스트 데이터셋에서만 이루어짐 → batch size, learning rate와 같은 하이퍼파라미터 설정
Test Dataset
- CheXpert 테스트 데이터셋
- 500개의 흉부 X-ray 이미지와 14가지 질환 포함
- AUROC와 MCC로 평가
- CheXpert competition에서 주로 5가지 병변을 평가 (ex. Atelectasis, Cardiomegaly, Consolidation, Oedema, Pleural efusion)
- PadChest 데이터셋
- PadChest는 160,868개의 흉부 X-ray 이미지와 174가지 소견, 19가지 질환 진단에 대한 라벨이 포함된 공개 데이터셋
- 전체 라벨 중 27%는 전문 방사선 전문의가 직접하고 나머지는 방사선 보고서를 기반으로 한 신경망 모델로 자동 생성되어있음
- 본 논문에서는 전문의가 직접 라벨링한 39,053개의 샘플만을 평가에 사용하고 각 조건별로 AUROC를 산출해 평가 진행
Pre-processing
- 이미지 전처리
- MIMIC-CXR의 377,110개 흉부 X-ray 이미지는 훈련 전에 224×224 픽셀로 크기 조정(resize)만 하고 패딩(padding)은 적용하지 않음
- 각 이미지는 훈련 데이터셋의 평균과 표준 편차를 사용하여 정규화 처리함 ⇒ 학습 수렴 속도 빨라지고 모델 안정적으로 학습할 수 있음
- 텍스트 전처리
- 방사선 보고서 텍스트는 49,408개 어휘 크기의 Byte Pair Encoding으로 토큰화함
- 모델의 최대 토큰 시퀀스 길이를 초과하는 텍스트는 “첫 번째 컨텍스트 길이 토큰 – 2”로 잘라냄
- 시작([SOS])과 끝([EOS]) 토큰을 각각 텍스트 임베딩의 앞뒤에 추가
⇒ 모델 최대 입력 길이에서 [SOS]와 [EOS]를 위해 2개를 빼고 남은 길이만큼만 텍스트 토큰을 앞에서부터 잘라서 사용
예를 들어 모델이 한 번에 처리할 수 있는 최대 토큰 수가 128개라고 가정하면 시작([SOS])과 끝([EOS]) 토큰을 나타내야하는 특수 토큰이 2개 필요함
그래서 실제로는 나머지 126개만 텍스트 내용에 할당할 수 있음
Architecutre
- 이미지 인코더
- Vision Transformer(ViT-B/32) 아키텍처를 사용
- OpenAI CLIP에서 사용된 것과 동일한 사전학습된 가중치를 활용
- 입력 이미지는 224×224
- ViT-B/32는 이미지를 32×32 크기의 패치로 분할하여 각 패치를 임베딩한 뒤, 포지션 인코딩을 더해 여러 층의 트랜스포머 인코더를 통과시켜 이미지의 전체 표현을 만듦
- 텍스트 인코더
- 트랜스포머기반의 텍스트 인코더를 사용
- 텍스트 인코더 역시 CLIP에서 사용된 가중치 활용
- 모델 크기는 약 63M 파라미터, 12개의 레이어, 임베딩 차원 512, attention head 8개로 구성
- 텍스트는 Byte Pair Encoding으로 토큰화되어 입력되며 최대 77개의 토큰 길이까지 처리함
⇒ CLIP에서의 가중치 그대로 적용하고 각각 임베딩 벡터로 변환하여 이미지와 텍스트 간의 semantic alignment를 학습함
이 임베딩들이 동일한 벡터 공간에 매핑되어 이미지-텍스트 간 의미적 유사성을 비교할 수 있음
Training
- 1,000 배치마다 CheXpert 5개 주요 병변에 대한 평균 AUC를 계산하고 이전 최고 성능 모델보다 우수하면 체크포인트를 저장함
- 저장된 체크포인트들의 평균 AUC를 기준으로 앙상블에 사용할 Top-10 모델을 선정
- 최적 모델은 SGD를 사용하고, 학습률 0.0001, 모멘텀 0.9, 배치 크기 64, 총 4 epoch 동안 학습
- 이미지-보고서 쌍의 임베딩 간 코사인 유사도를 최대화하고 잘못된 유사도는 최소화하는 대조 학습(contrastive learning)을 수행
Softmax 평가 기법
- Multi Label Classification → 한 이미지에 여러 질병이 동시에 있을 수 있음
- 각 질병마다 양성 또는 음성 프롬프트에 대해 각각 logit을 계산함 (ex. atelectasis ↔ no atelectasis)
- 두 logit에 대해 소프트맥스 함수를 적용
- CLIP처럼 모든 클래스를 한 번에 소프트맥스에 넣는게 아닌 각 질병 별로 독립적으로 확률을 산출함
Knowledge-distillation procedure
- CLIP의 텍스트 인코더는 최대 77 토큰만 처리할 수 있어 전체 방사선 보고서(대부분 77 토큰을 초과)에 바로 적용하기 어려움
- 컨텍스트 길이가 512인 새로운 텍스트 인코더(student model)를 훈련 → 98%의 방사선 보고서를 모두 포함할 수 있었음
- 구체적으로 보고서의 섹션 중 인상 섹션만으로 훈련된 성능이 가장 좋은 모델의 텍스트 인코더(teacher 모델)를 사용해, student model의 텍스트 인코더가 비슷해지도록 MSE를 최소화하며 훈련함
- student 텍스트 인코더가 훈련된 후에는 student model의 이미지 인코더를 teacher model의 이미지 인코더로 교체함 ⇒ student 모델은 텍스트 인코더만 새로 훈련하고 이미지 인코더는 기존 것 사용한다는 의미
- 최종적으로 MIMIC-CXR의 흉부 X-ray와 전체 보고서에 대해 대조 학습을 진행
student model의 텍스트 인코더가 충분히 잘 훈련된 후, student model 이 가지고 있던(초기화된) 이미지 인코더는 버리고, teacher model(즉, 기존 CLIP 기반 모델)의 이미지 인코더를 student model 에 붙임
- 텍스트 인코더는 전체 보고서를 처리할 수 있는 긴 컨텍스트를 갖게 되고
- 이미지 인코더는 이미 CLIP에서 잘 학습된 강력한 이미지 표현력을 그대로 사용할 수 있음
→ 즉, " student model"은 텍스트 인코더만 새로 훈련되고, 이미지 인코더는 검증된 teacher model의 것을 그대로 가져다 쓰는 구조가 됨

- 매튜스 상관 계수(MCC) 지표에서는 Model과 방사선 전문의의 통계적으로 유의미한 차이가 없음
- 모델의 평균 F1과 방사선 전문의의 평균 F1 성능 사이에는 통계적으로 유의미한 차이가 없음
→ 모델-방사선 전문의 성능=-0.009; 95% CI -0.038, 0.018- 개별 병리학에서 특히 심근 비대에 대해 방사선 전문의보다 현저히 높았음
(모델-방사선 전문의 성능=0.065; 95% CI 0.013, 0.115)
- 개별 병리학에서 특히 심근 비대에 대해 방사선 전문의보다 현저히 높았음
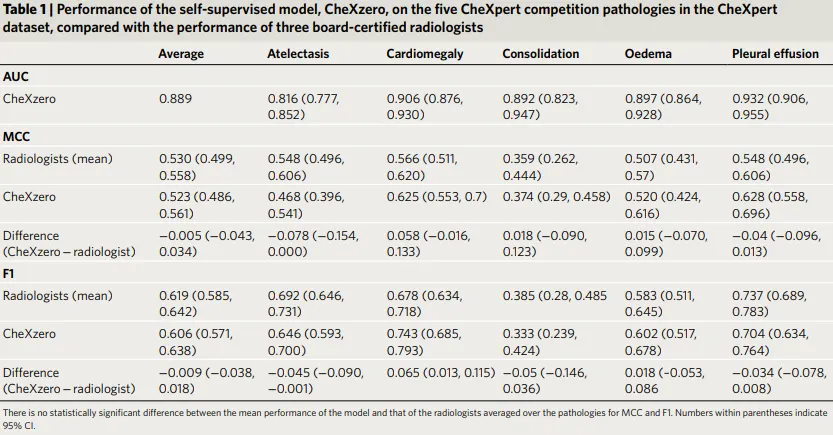
- CheXpert 테스트 데이터셋에서 5가지 CheXpert competition 병리를 분류하는 성능이 3명의 방사선 전문의와 비슷

- PadChest 테스트 데이터셋에서 PadChest 데이터셋에서 0%의 라벨을 사용했음에도 불구하고, 자기 지도 학습 모델이 3개 병리(Atelectasis, Consolidation, Oedema)에서 성능 능가하는 것을 관찰
추가 실험
- PadChest 데이터셋 사용
- 성별 예측에 대해 0.936의 AUC를 달성하고 흉부 X- 레이가 전방인지 후방인지 예측하는 것은 0.799 (95% CI 0.7595, 0.835)의 AUC를 달성했음
⇒ 보조 작업에 대한 예측을 하기 위해서는 작업에 사용할 프롬프트 개발만 필요
⇒ ‘환자의 성별이 남성’, ‘환자의 성별이 여성’ 이라는 프롬프트 사용
Limitation
- 여전히 하이퍼파라미터 선택을 위해 라벨링된 검증 세트에 대한 성능을 반복적으로 쿼리해야하고 MCC 및 F1 점수를 계산할 때 확률 임계값을 결정해야 함
- 전자 건강 기록이나 다른 출처의 데이터를 통합해서 병리학 보고서에 적용할 필요가 있음
- 본 논문에서의 224x224 크기의 이미지에서 더 큰 이미지 크기로 확장해서 작은 병리를 더 잘 분류할 수 있도록 해야함
'Audio' 카테고리의 다른 글
| [2023-2] 현시은 - Music Transformer: Generating Music with Long-Term Structure (ICLR19) (0) | 2023.11.26 |
|---|
