
https://arxiv.org/abs/2211.12194
SadTalker: Learning Realistic 3D Motion Coefficients for Stylized Audio-Driven Single Image Talking Face Animation
Generating talking head videos through a face image and a piece of speech audio still contains many challenges. ie, unnatural head movement, distorted expression, and identity modification. We argue that these issues are mainly because of learning from the
arxiv.org
0. Abstract
얼굴 이미지와 음성 오디오를 이용해 말하는 얼굴 영상을 생성하는 것은 여전히 많은 어려움이 존재한다. 이는 주로 2D 모션 필드에서 학습하기 때문에 발생하는데 3D 정보를 활용하더라도 여전히 딱딱한 표정이나 일관성 없는 영상을 만들어 낸다는 문제가 존재한다. 저자는 오디오로부터 표정과 머리 움직임을 각각 ExpNet과 PoseVAE로 예측해 3D 모션 계수를 생성하고 이를 3D-aware face render의 비지도 키포인트 공간에 매핑해 사실적인 말하는 얼굴 영상을 합성하는 sadTalker를 제안한다.
1. Introduction
기존 2D 모션 필드를 사용하는 방법은 영상이 부자연스럽다는 문제가 존재하는데 3DMM 모델은 각각의 움직임 종류별로 개별적인 학습을 통해 분리된 표현을 제공할 수 있어 복잡한 상호작용 문제를 완화할 수 있다는 장점이 있다. 그러나 이 방법도 여전히 최종 영상이 부자연스럽다는 문제가 존재한다. 이를 해결하기 위해 SadTalker는 3DMM의 모션 계수를 intermediate representation으로 사용하여 음성에서 현실적인 모션(머리 자세, 입술 움직임, 눈 깜빡임) 등을 개별적으로 생성한 후 이를 3D face render 방식으로 최종 영상에 반영하는 시스템을 제시했다.
1) 모션 계수 생성
- 표정 : ExpNet이라는 네트워크를 이용하여 음성에서 표정 정보를 추출하고 3d render된 얼굴에 대한 perceptual loss를 통해 보완하여 모션 계수 생성
-머리 자세 : PoseVAE라는 네트워크를 이용하여 조건부 VAE(variational autoencoder)에 자세의 residual을 추가로 학습하게 해 자연스러움 머리 움직임을 위한 모션 계수 생성
2) 최종 영상 생성
: 생성된 모션 계수를 기반으로 소스 이미지를 3D-aware face render로 구동한다. 이는 3DMM 계수와 비지도 3D 키포인트 도메인 간의 매핑을 학습하고 이 키포인트를 통해 소스와 구동 이미지 간의 워핑 필드를 생성해 최종 영상을 만드는 식으로 진행된다.
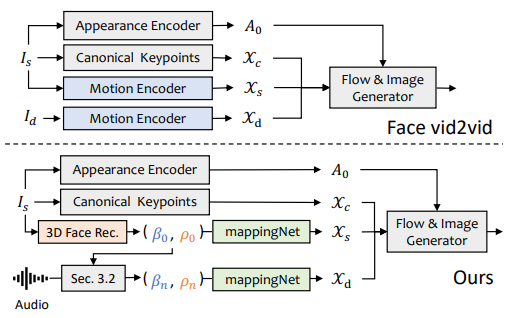
2. Method
->입력이미지에서 3DMM 계수 추출
-> 오디오를 기반으로 EepNet과 PoseVAE를 이용하여 사실적인 3DMM 모션 계수를 각각 생성
-> 3D-aware face render를 이용하여 최종적인 talking head video 생성
1) Preliminary of 3D face model
3DMM( 3D Morphable Model )은 얼굴 형상 S를 다음과 같이 표현한다.

각각의 항은 평균 얼굴 형태, 정체성과 표정에 대한 orthonormal basis를 뜻하고 뒤의 두개의 값은 LSFM 모델을 통해 얻을 수 있다. 그리고 α, β 계수는 각각 정체성과 표정을 나타내는 계수이다.
이때 머리의 회전( r∈SO(3) )과 평행이동 ( t∈R^3) 을 이용하여 최종적인 모션 계수는 {β,r,t}로 표현된다. 다만 정체성에 의존하지 않는 모션을 생성하기 위해 정체성 계수는 사용되지 않는다.
=> SadTalker의 처리 방식
: 오디오로부터 표정 계수 β와 머리 자세 ρ=[r,t]를 개별적으로 학습한 후 이를 이용해 모션 계수를 생성한다. 생성된 모션 계수는 3D-aware face render에 적용되어 최종적으로 말하는 얼굴 영상을 합성하게 된다.
2) Motion coefficient generation through audio
머리 자세는 global 모션, 표정은 local한 모션이라서 모든 모션을 한번에 학습하면 오디오와 표정은 높은 상관관계를 가지지만 머리자세와는 약한 상관관계를 가져 불확실성이 커지게 된다. 따라서 본 논문은 모션을 두 가지 모듈로 분리하여 학습한다.
ExpNet : 오디오로부터 표정계수 β 생성
PoseVAE : 오디오로부터 머리 자세 계수 ρ=[r,t] 생성
< ExpNet >
- 오디오 입력은 프레임 단위로 처리되며, 각 프레임은 0.2초 길이의 mel-spectrogram으로 표현
- ResNet 기반 오디오 인코더 ΦA -> 오디오 특징 추출
- linear mapping network ΦM -> 추출된 오디오 특징과 β0, 눈 깜빡임 제어 신호

- loss function : Ldistill ( 실제 β와 예측 간 차이 ), Llks ( landmark loss - 눈 깜빡임 및 전반적인 표정 정확도 측정 ), Lread ( lip reading loss - 입술 움직임의 시간적 일관성 유지 )
- 첫 프레임에서 추출한 표정 계수 β0를 함께 넣어줌으로써 예측되는 표정이 특정 사람에 맞게 보정되도록 유도하여 동일한 오디오에 대해 사람에 대해 표정이 다를 수 있다는 identity 문제를 해결
- landmark loss와 lip reading loss를 이용하여 표정 계수에 포함된 오디오와 무관한 요소를 제거

< PoseVAE >
: VAE ( Variational Autoencoder ) 구조를 기반으로 설계되어 실제 말하는 영상에서 사실적인 스타일의 머리 움직임 ρ을 학습한다.
- 고정된 n 프레임 수의 마리 자세 시퀀스 ( t-frame poses )를 입력으로 받음
- 2 layer MLP의 Encoder/Decoder 구조
- Encoder는 입력된 시퀀스를 가우시안 분포에 임베딩
- Decoder는 샘플링된 분포에서 다시 시퀀스를 복원
- PoseVAE는 머리 자체를 직접 생성하지 않고 첫 프레임의 조건 자세 ρ₀에 대한 residual을 예측하여 긴 시간 동안 안정적이고 연속적인 머리 움직임을 생성할 수 있다.
- 오디오 특징

3) 3D - aware face render
: 생성한 3D 모션 계수를 이용하여 3D - aware image animator로 최종 영상을 만든다.
- MappingNet : 여러 개의 1D convolution layer로 구성된 네트워크가 3DMM 모션계수와 unsupervised 3D keypoint 간의 매핑 관계를 학습한다. 다만 이때 일정 시간 window 계수를 이용하여 시간 정보를 반영하여 움직임을 부드럽게 처리한다.
- face-vid2vid를 self-supervised 방식으로 학습 ( 기존의 방식 )
- appearance encoder, keypoint estimator, image generator는 freeze
- MappingNet만 학습
- ground truth 비디오의 3DMM 계수를 input으로 reconstruction 방식으로 학습
- L1 loss를 사용하고 최종 영상은 face-vid-2vid 생성기를 통해 출력
3. Experiment

=> 다른 모델에 비해 입술 움직임의 정확도, 얼굴 정체성 유지와 자연스러움 측면에서 우수한 결과를 보임

=> 기존 방법과 수치적 성능에서 비슷하거나 더 높은 결과를 보였고 특히 WER을 통해 입술 동기화 품질이 우수함을 보임

=> PoseVAE를 통해 더 리듬감 있고 다채로운 머리 움직임을 생성해냄
4. Conclusion
기존의 방식과 다르게 3D 기법을 활용하여 더 사실적이고 자연스러운 얼굴 영상을 생성해냄.
다만, 일부 예제에서 입술 영역에 치아 artifact가 나타난다는 문제가 발생한다는 한계가 있고 사실적인 영상이 악용될 수 있다는 문제를 해결할 필요성이 있다.



