
https://arxiv.org/pdf/2003.08934 Ben Mildenhall et al, UC Berkeley, Google Research, UC San Diego
https://www.matthewtancik.com/nerf - 홈페이지

Abstract
- 연구 개요
- 소개: 복잡한 장면의 새로운 시점을 합성하기 위해 연속적인 볼륨 장면 함수를 최적화하는 방법 제시
- 목적: 희소한 입력 뷰를 사용하여 복잡한 장면의 신규 뷰를 합성
- 알고리즘 설명
- 입력: 5D 좌표(공간 위치 $ x,y,z $ 및 viewing direction $ \theta, \phi $)
- 출력: 해당 공간 위치에서의 부피 밀도와 시청 방향에 따른 방사선
- 합성 방법: 카메라 광선을 따라 5D 좌표를 쿼리하고 클래식 볼륨 렌더링 기술을 이용해 이미지로 출력
- 기술적 특징 및 장점
- 볼륨 렌더링의 특성: 자연스러운 미분 가능성을 활용해 네트워크 최적화
- 데이터 요구사항: 알려진 카메라 포즈를 가진 이미지 세트 필요
- 성과
- 기존 뉴럴 렌더링 및 뷰 합성 기법보다 우수한 결과 제공
1. Introduction
- Static scene을 5D continuous function $ F_\theta(x,y,z, \theta, \phi) = \sigma, c(r,g,b) $ 으로 표현
- $\sigma$ : single volume density, c: view dependent RGB color
- CNN을 사용하지 않고 MLP를 사용
# Pipeline

- Camera ray를 scene에 발사해 3d point를 sample
- 포인트(x,y,z)와 viewing direction을 neural network의 input으로 사용
- Classical volume rendering 기법을 사용하여 한 ray에 위치하는 sample 포인트들의 색과 밀도를 2d 이미지로 합쳐줌
- High resolution representaion을 위해 positional encoding, hierarchical sampling 사용
2. Related Work
- Neural 3D shape representations
- xyz 좌표를 signed distance function이나 occupancy field로 나타냄
- Ground truth 3D geometry가 필요하다는 한계가 있음
- 후속 연구에서 미분가능한 rendering function을 제안해 2D 이미지만 사용하도록 개선
- geometric complexity가 낮은 간단한 모양만 나타내는 한계가 존재
- View synthesis and image-based rendering
- 메쉬 기반 방법
- 입력 이미지로부터 기하학과 외관을 예측해 뷰 합성 수행.
- 경사 하강법 최적화 필요, 초기화가 어려움.
- 볼륨 기반 방법
- 복잡한 형태·재질 표현 가능, 메쉬 기반 방법보다 aritfact가 적음.
- 초기 방식은 voxel grid를 직접 색칠.
- 최신 접근법
- 대규모 데이터셋 활용, 신경망으로 볼륨 예측.
- 알파 합성·레이어드 합성으로 뷰 렌더링.
- CNN으로 저해상도 보크셀 문제 보완.
- 한계 및 해결책
- 기존 볼륨 기술은 3d 공간에서의 샘플링 한계로 인해 해상도 확장 어려움.
- Nerf는 연속 볼륨을 인코딩하는 딥러닝으로 품질 향상·메모리 절약
- 메쉬 기반 방법
3. Neural Radiance Field Scene Representation

- x = (x,y,z), d = ($\theta, \phi$), c = (r,g,b)
- multi view consistent한 representation으로 나타내기 위해 $\sigma$ 는 $x$의 함수로, c 는 x, d 의 함수로 설정

4. Volume Rendering with Radiance Fields
- 새롭게 생성하고 싶은 view의 가상의 카메라 중심으로부터 객체를 향해 ray를 쏨
- ray위에 여러 포인트들을 샘플링
- MLP를 통해 각 포인트의 RGB와 density 예측
- 샘플링 된 모든 포인트들의 RGB와 density 값을 특정 연산을 통해 바라보는 방향으로 projection 시킴
- https://tv.kakao.com/v/440203289
동영상 서비스가 종료되어 해당 콘텐츠를 재생할 수 없습니다.

- r(t) = o + td : camera ray , C(r) : expected color of camera ray
- $t_n, t_f$ : near and far bounds
- $T(t)$ : Accumulated transmittance -> ray가 해당 포인트에 도달할 확률, ray가 첫 번째로 만나는 객체에 더 많은 가중치를 부여해줌


- Quadrature rule을 사용해 C(r)값을 위 식으로 추정
- 실제로 사용할 때는 [$t_n, t_f$]를 N개의 동일한 bin으로 나누고 각 bin에서 random하게 포인트를 sample
5. Optimizing a Neural Radience Field
high-resolution complex scenes를 나타내기 위해 2가지 방법을 제안.
5.1 Positional encoding
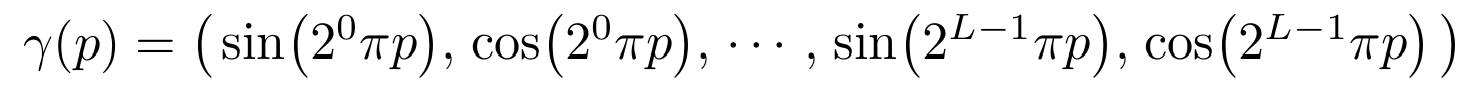
- 모델에 input으로 사용하는 3차원의 위치 정보 x와 2차원 방향 정보가 너무 저차원이라 positional encoding으로 고차원으로 임베딩 시켜줌
- 논문에서는 x에 대해서는 L=10을 d에 대해서는 L=4를 사용.

5.2 Hierarchical volume sampling
camera ray의 query point를 sampling 할 때 물체가 존재하지 않거나 뒤쪽에 있어 랜더링에 영향을 미치지 않는 포인트들은 샘플링 하는 의미가 없음. -> 더 효과적인 샘플링 전략 필요

- 두 가지 네트워크, "coarse" and "fine" 를 동시에 학습
- 먼저 stratified sampling으로 $N_c$ 개의 포인트 sample

- 위 식에서 $w_i$를 normalize($\hat{w}_i = \frac{w_i}{\sum_{j=1}^{N_c} w_j}$) 해주어서 ray를 따라 piecewise-constant PDF 를 만들어줌
- 위 분포에서 Inverse transform sampling을 진행하여 fine network에 사용할 포인트 $N_f$를 sample
- $N_c + N_f$ 샘플을 모두 사용하여 fine network 학습
5.3 Implementation details
- 데이터 셋: RGB 이미지, 카메라 포즈, 카메라 intrinsic parameters, scene bound
- 모든 픽셀에 대하여 camera ray를 한 배치 크기 만큼 샘플
- 각 ray에 대하여 coarse network 학습 시 사용할 $N_c$개의 포인트 샘플
- 각 ray에 대하여 fine network 학습 시 사용할 $N_c + N_f$개의 포인트 샘플

- 실제 랜더링시 사용하는 네트워크는 fine network이지만 coarse network도 fine network의 포인트 샘플링에 영향을 주므로 같이 훈련.
- 논문에서는 $N_c = 64, N_f = 128$로 설정
6. Results
6.1 Datasets

- Synthetic Renderings of Objects:
- Diffuse Synthetic 360°, Realistic Synthetic 360° 데이터셋 사용
- DeepVoxels 데이터셋 포함 (단순한 형상, 램버시안 재질)
- 복잡한 형상과 비-램버시안 재질을 가진 자체 생성 데이터셋 추가
- 100개 학습 뷰, 200개 테스트 뷰 (800×800 해상도)
- Real Images of Complex Scenes:
- 실세계 복잡한 장면을 포함한 데이터셋
- LLFF 논문의 5개 장면 + 추가 촬영한 3개 장면
- 20~62장의 이미지 사용, 1/8을 테스트셋으로 분리
- 해상도 1008×756
6.2 Comparisons


- 비교 대상 방법:
- Neural Volumes (NV): 3D 컨볼루션 기반으로 RGBα 복셀 그리드를 생성하는 방식
- Scene Representation Networks (SRN): MLP를 이용한 연속적인 장면 표현, 깊이-색 정보를 한 지점에서만 예측
- Local Light Field Fusion (LLFF): 다중 평면 이미지(MPI)를 사용하여 보기 합성을 수행
- 결과:
- NeRF가 대부분의 평가 지표에서 기존 방법보다 우수한 성능을 보임
- LLFF 대비 높은 일관성과 적은 아티팩트 제공
6.3 Discussion
- NeRF의 장점
- NV보다 세밀한 디테일 표현 가능 (NV는 128³ 복셀 그리드 한계)
- SRN보다 더 정확한 기하학적 표현 가능 (SRN은 과도한 스무딩 발생)
- LLFF 대비 더 적은 아티팩트와 높은 일관성 제공
- 기존 방법 단점 및 한계
- 학습 시간이 길어 1개 장면당 최소 12시간 필요 (LLFF는 10분 이내)
- Nerf는 LLFF 대비 저장 공간 효율적 (NeRF 모델 크기 5MB, LLFF는 15GB 이상)
6.4 Ablation study

- 모델 구성 요소 제거 실험:
- 위치 인코딩(PE), 시점 의존성(VD), 계층적 샘플링(H)을 제거하며 성능 비교
- 위치 인코딩 및 시점 의존성이 가장 큰 성능 향상을 제공
- 입력 이미지 수 감소 실험:
- 100장 → 25장으로 감소 시에도 NV, SRN, LLFF보다 높은 성능 유지
- 주파수 조정 실험:
- 너무 적은 주파수 (L=5) → 성능 저하
- 너무 많은 주파수 (L=15) → 성능 개선 없음 (L=10이 최적)
7. Conclusion
- 연구 기여
- 기존 방법(voxel 기반 CNN)보다 연속적인 뉴럴 방사장(NeRF)이 더 우수한 렌더링 품질을 제공함.
- MLP를 사용하여 3D 위치와 2D view 방향을 기반으로 색상과 밀도를 예측하는 방식이 효과적임.
- 계층적 샘플링 전략
- 샘플링 효율성을 높이기 위해 계층적 샘플링 기법을 제안했으며, 학습 및 추론 속도를 개선함.
- 하지만 여전히 뉴럴 방사장의 최적화 및 렌더링 효율성을 높이는 추가 연구가 필요함.
- 미래 연구 방향
- 해석 가능성(Interpretability) 문제 해결 필요.
- 기존 voxel 그리드나 메시 기반 방식은 예상 품질 및 오류 분석이 가능하지만, NeRF는 딥러닝 가중치 내에서 장면을 인코딩하므로 해석이 어려움.
- 향후 연구는 실제 세계 이미지 기반 그래픽 파이프라인을 구축하는 방향으로 발전 가능.
'CV' 카테고리의 다른 글
| [2025-1] 임수연 - PIFuHD (0) | 2025.03.19 |
|---|---|
| [2025-1] 정성윤 - Inception-Net 논문 리뷰 (0) | 2025.03.15 |
| [2025-1] 전연주 - Multi‑modal transformer architecture for medical image analysis and automated report generation (0) | 2025.03.15 |
| [2025-1] 임수연 - MobileUNETR (0) | 2025.03.14 |
| [2025-1] 유경석 - XprospeCT: CT Volume Generation from Paired X-Rays (0) | 2025.03.14 |



