
- NeurIPS 2017
- 3556회 인용
⇒ OpenAI/Google에서 발표
본 논문에서는 명확한 보상 함수 없이도 효과적인 학습이 가능하도록 인간의 선호(preference)를 활용하는 방법을 연구한다.
기존의 RL 방식은 잘 정의된 보상 함수가 필요하지만 현실 세계에서 많은 문제들은 명시적인 보상 함수를 설계하기 어렵다. 저자들은 비전문가(non-expert) 인간이 두 개의 행동(trajectory segment) 중 선호하는 것을 선택하도록 하는 방법을 제안하고 이를 통해 학습 가능한 보상 함수를 추론하여 RL 시스템을 학습하였다.
⇒ InstructGPT를 포함한 챗봇과 언어 모델에 RLHF(Reinforcement Learning from Human Feedback)를 적용할 수 있는 계기를 마련하였다.
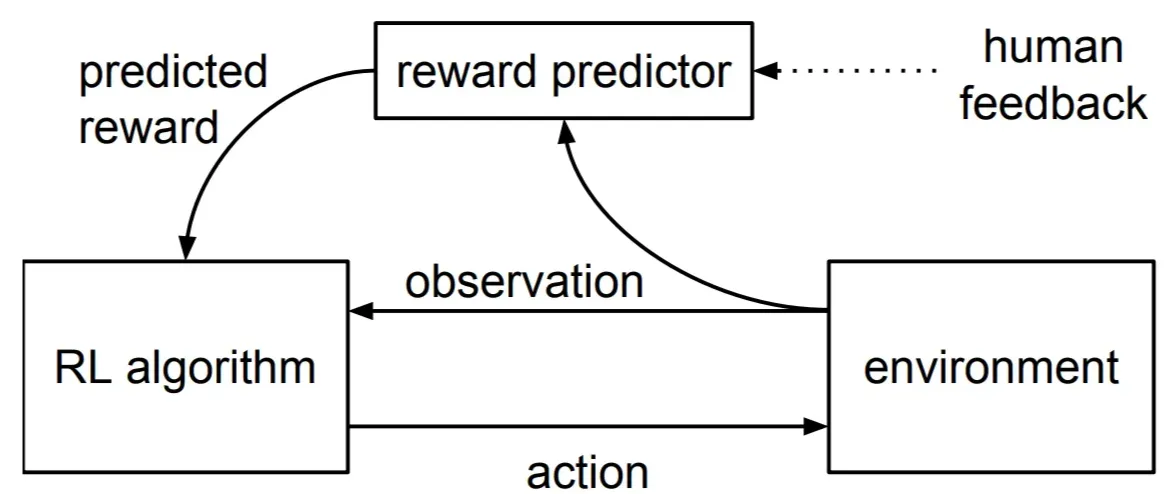
- Environmnet
- RL 알고리즘이 행동(action)을 수행하면 환경이 관찰값(observation)을 반환
- RL Algorithm
- 기존 RL은 관찰한 정보(observation)를 바탕으로 어떤 행동(action)을 할 지 결정
- 본 논문은 환경에서 직접 보상을 받지 않고 Reward Predictor에서 보상을 예측받음
- Reward Predictor
- 인간 피드백을 학습하여 보상을 예측하는 모델 $\hat{r}$
- Human Feedback
- 어떤 행동이 더 바람직한지 선택하는 방식으로 피드백을 제공
- Predicted Reward
- 학습된 Reward Predictor가 환경에서 주어진 observation을 기반으로 보상을 예측
- 이를 기반으로 최적의 정책(policy)을 학습
1. Preliminaries
Observation
- $o_t\in{}O$ : Agent가 각 $t$마다 시각, 센서 등 환경에서 받아들인 정보 (output)
- 시점 $t$마다 새로운 $o_t$를 얻음
Action
- $a_t\in{}A$ : Agent가 $o_t$에 따라 실시한 행동
- 시점 $t$마다 $a_t$를 수행
Reward
- $r_t\in{}R$ (기존 RL) : Agent가 행동을 실시했을 때의 보상
- 본 논문에서는 보상 함수가 아닌 인간의 피드백을 사용
Trajectory Segment($\sigma$)
$\sigma=((o_0,a_0),(o_1,a_1),…,(o_{k−1},a_{k−1}))\in(O\times{}A)k$
- Agent가 시간에 걸쳐 수행한 Observation-Action 쌍을 묶은 것이고 Trajectory Segment 라 함
- 본 논문에서 $\sigma_1>\sigma_2$라 하면 인간이 $\sigma_1$이라는 궤적을 $\sigma_2$보다 더 선호한다는 의미
Agent의 Action에 대한 평가 방법
Quantitative 평가
- 사람의 선호가 어떤 보상 함수 $r:O\times{}A\rightarrow{}R$ 로 표현된다고 가정
- ex) $\sigma_1>\sigma_2$라 하면, $\sum{}r(o^1_{t},a^1_{t}) > \sum{}r(o^2_{t},a^2_{t})$ 식으로 $\sigma_1$의 누적 보상이 $\sigma_2$보다 더 큰 것을 의미한다.
- 이 경우 보상 함수 $r$만 학습했다면 Agent가 얻은 누적 보상을 기반으로 정량적인 평가(Quantitative 평가)가 가능
Qualitative 평가
- 때로 사람의 선호를 평가할 적절한 보상 함수를 정의하지 못할 수 있음
- Agent의 행동이 얼마나 사람이 원하는 목표를 제대로 달성하는가? 하는 정성적인 평가(Qulitative 평가)만 가능
2. Method
(1) Setting and Goal
- 기존 강화 학습에서는 reward fundtion($r_t$)을 명확하게 정의하여 Agent가 보상을 최대화하도록 학습
- 본 논문은 보상 신호(reward signal) 없이 인간이 제공하는 "좋다" vs "나쁘다" 비교 데이터만을 사용하여 보상 모델을 학습
- Agent는 적은 피드백만으로 사람이 선호하는 trajectory를 학습하여 생성하도록 학습하는 것이 목표
(2) Optimizing the Policy
정책 학습(Policy Learning) - 보상 함수 학습(Reward Function Learning) - 인간 피드백 수집 (Human Feedback Collection)
⇒ 3가지 학습 과정
Policy $\pi$
- 에이전트는 정책인 $\pi{} : O\rightarrow{}A$을 통해서 현재 환경을 관측한 결과($o$)에 맞춰 행동($a$)을 결정
- 정책 $\pi$는 학습되면서 업데이트됨
Trajectory 생성
- Agent가 현재 정책 $\pi$을 사용해서 환경에서 움직이며 여러 개의 trajectory $(\tau_1,\tau_2,\tau_3,\tau_4,\tau_5,\cdots{},\tau_i)$ 를 생성
- 각각의 trajectory는 Observation-Action 쌍 $(o_t,a_t)$
Reward function estimate $\hat{r}$ 학습
$$
r_t=\hat{r}(o_t,a_t)
$$
- 보상 함수를 모른다고 가정하고 Deep Neural Network를 이용해서 $\hat{r}:O\times{}A\rightarrow{}R$ 를 학습
- $\hat{r}$의 파라미터(가중치)는 인간 피드백을 기반으로 갱신
⇒ 보상 함수를 최적화하면서 정책을 업데이트하는 과정은 서로 비동기적(asynchronously)으로 수행
(3) Preference Elicitation
💡인간 피드백 방식
인간에게 두 개의 1~2초 분량의 동영상 클립(trajectory segments)을 보여주고 어떤 행동이 더 바람직한지 선택하도록 함
➡️가능한 선택지
1. 첫 번째 행동이 더 바람직함 (segment 1)
2. 두 번째 행동이 더 바람직함 (segment 2)
3. 두 행동이 동일하게 좋음 (Tie)
4. 비교 불가능 (Can’t tell)
- 인간의 피드백은 데이터베이스 $\mathcal{D}$에 $(\sigma_1, \sigma_2, \mu)$ 형태로 저장
- $\sigma_1, \sigma_2$ : 비교할 두 개의 trajectory segment
- $\mu$ : 인간이 선택한 선호 확률 분포
- ex) $\mu = (0.8, 0.2)$ → 첫 번째 행동이 80% 확률로 더 좋음
(4) Fitting the Reward Function
- 인간의 피드백을 활용하여 reward predictor model $\hat{r}$을 학습
학습 목표
$$
\hat{P} \left[ \sigma^1 \succ \sigma^2 \right] =
\frac{\exp \sum \hat{r} (o_t^1, a_t^1)}
{\exp \sum \hat{r} (o_t^1, a_t^1) + \exp \sum \hat{r} (o_t^2, a_t^2)}
$$
- 예를 들어 사람이 $\sigma_1$을 $\sigma_2$보다 선호한다고 했다면 $\sum{}\hat{r}(\sigma_1)>\sum{}\hat{r}(\sigma_2)$가 되도록 $\hat{r}$을 학습함
- (Bradley & Terry, 1952)
손실 함수
$$
\text{loss}(\hat{r}) = - \sum_{(\sigma^1, \sigma^2, \mu) \in \mathcal{D}}
\mu(1) \log \hat{P} \left[ \sigma^1 \succ \sigma^2 \right]
+ \mu(2) \log \hat{P} \left[ \sigma^2 \succ \sigma^1 \right]
$$
- 손실 함수로 크로스 엔트로피(cross-entropy loss)를 사용하여 보상 함수 업데이트
- 사람이 $\sigma_1$을 선택하면 → $\mu(1)=1,\mu(2)=0$ → $\hat{P}(\sigma^1\succ\sigma^2)$ 가 커지도록 학습
- 사람이 $\sigma_2$을 선택하면 → $\mu(1)=0,\mu(2)=1$ → $\hat{P}(\sigma^2\succ\sigma^1)$ 가 커지도록 학습
⇒ 사람의 선택이 곧 정답이고 reward predictor($\hat{r}$)는 사람이 선택한 trajectory가 더 높은 확률을 갖도록 학습
추가 적용
- 기존 강화학습에서는 같은 상황에서 같은 행동을 하면 동일한 보상이지만 본 논문에서는 사람의 피드백을 줄 때마다 보상 함수 $\hat{r}$ 자체가 갱신
- 보상을 기준으로 정책을 학습하는데 보상이 고정되지 않고 계속 바뀔 수 있음
⇒ non-stationary reward (비정상적인 보상)
① 앙상블
- 보상 함수 $\hat{r}$를 하나의 모델로 학습하면 overfitting 또는 극단적인 값이 나올 가능성이 높음
- 이를 막기 위해 여러 개의 보상 예측 모델( $\hat{r}_1,\hat{r}_2,\hat{r}_3,\cdots$)을 독립적으로 학습한 후 결과를 평균화하여 사용
② L2 Regularization
- 과적합을 방지
③ Validation Set 활용 ($\frac{1}{e}$ 데이터 비율 할당)
- 일반화 성능 유지
④ Softmax 대신 인간의 랜덤 응답
- 현실적으로 인간이 일관되지 않은 피드백을 제공할 가능성이 있음
- 보상의 차이가 클수록 0으로 수렴하는 Softmax를 직접 쓰지 않고 10% 확률로 무작위 응답이 존재한다고 가정하여 모델을 더 안정적으로 학습
(5) Selecting Queries
- 보상 예측 모델이 아직 확신하지 못하는 부분에서 인간 피드백을 우선적으로 요청하여 학습을 개선
⇒ 보상 함수의 불확실성을 근사적으로 측정하여 질문할 데이터를 선택하는 방식(Active Preference Querying)을 사용
- $k$개의 trajectory segment 쌍 $(\sigma_1, \sigma_2)$을 무작위로 샘플링
- 각 보상 예측 모델(앙상블의 개별 모델)이 두 trajectory 중 어느 것이 더 선호될지 예측
- 예측 결과들의 분산(variance)을 계산
- 만약 여러 개의 보상 모델이 서로 다른 예측을 한다면, 그 데이터는 보상 함수가 아직 잘 학습되지 않은 영역이라고 볼 수 있음
- 예측 결과의 분산이 가장 높은 trajectory 쌍을 선택하여 인간에게 피드백 요청
⇒ 때때로 성능 저하를 일으켜 구체적인 방법론은 future work로 남김
3. Experiments
Atari 게임과 로봇 시뮬레이터인 MuJoCo(Multi-Joint Dynamic-with-Contact)에서 강화학습 에이전트를 학습시키는 실험을 수행하였으며 인간 피드백을 활용하는 것이 실제로 복잡한 행동을 학습하는 데 효과적임을 보였다.
실험 환경
- MuJoCo: Hopper, Walker, Cheetah 등 8가지 로봇 제어 환경에서 테스트
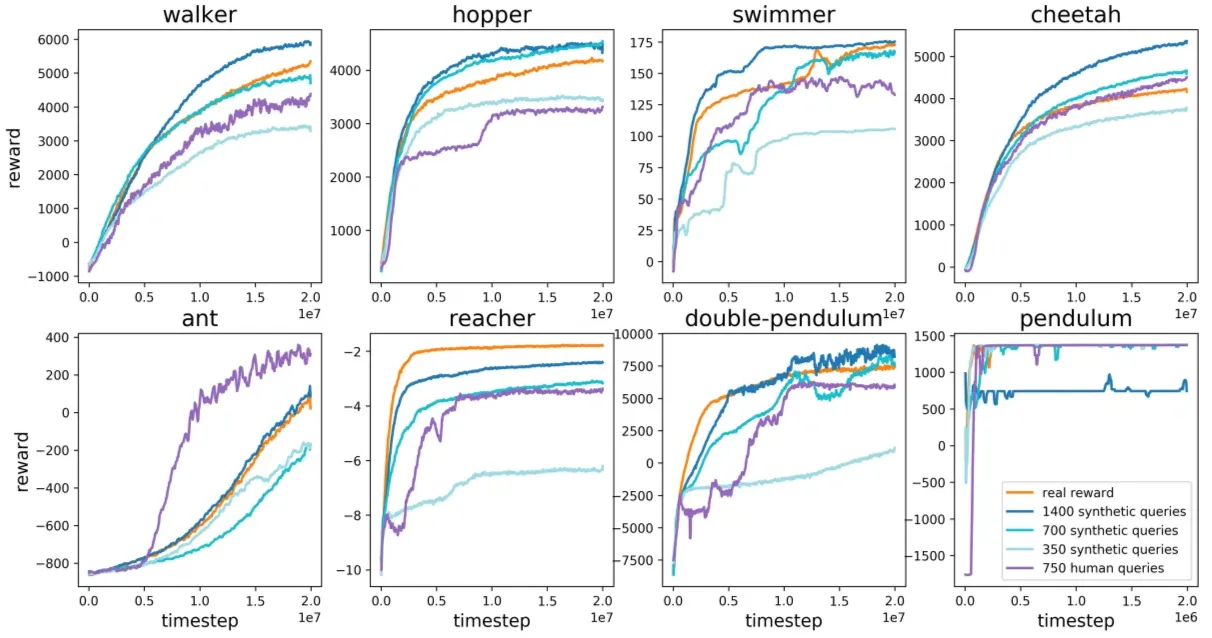
- True Reward로 학습할 때보다 Qery를 통해 학습한 보상 모델이 더 좋은 결과를 보이기도 함
⇒ 보상 함수가 잘 정의되지 않은 상황에서는 Human Query가 더 유리할 수 있으며 Synthetic Query도 충분한 정보를 제공
- Atari 게임: Pong, Breakout, SpaceInvaders, Qbert 등 총 7개의 게임에서 실험을 수행

- Human Query는 사람이 직접 레이블링한 데이터를 기반으로 학습한 것이며 Synthetic Query는 보상 함수를 통해 자동 생성된 피드백을 기반으로 학습
- RL은 True Reward를 사용한 강화학습이고 RL과 비슷한 경향을 보이는 것을 볼 수 있음
⇒ 명확한 보상 함수 없이도 인간의 피드백을 적용하여 학습이 가능한 것을 볼 수 있음
4. Contribution & Novelty
- 기존 강화 학습과 비교하여 인간의 피드백을 적용하여 어렵고 복잡한 환경에서도 강화 학습이 가능함
- 기존에는 전문가가 직접 보상 함수를 설계해야 했지만 비전문가도 “어떤 행동이 더 낫다”는 비교만으로 에이전트 학습을 도울 수 있음
- 과도한 피드백 요구없이 실험 결과에서와 같이 적은 피드백만으로도 성능이 좋은 것을 알 수 있음
'Miscellaneous' 카테고리의 다른 글
| [2025-1] 박경태 - 밑바닥부터 시작하는 딥러닝(CH 4.5): 학습 알고리즘 구현하기 (0) | 2025.03.12 |
|---|---|
| [2025-1] 노하림 - Beyond Scalar Reward Model: Learning Generative Judge from Preference Data (6) | 2025.03.10 |
| [2025-1] 장인영 - 밑바닥부터 시작하는 딥러닝 리뷰, (CH 3.4) 3층 신경망 구현하기 (1) | 2025.03.05 |
| [2025-1] 임준수 - 밑바닥부터 시작하는 딥러닝 리뷰, (CH 3.2) 활성화 함수 (0) | 2025.03.05 |
| [2025-1] 박경태 - 밑바닥부터 시작하는 딥러닝 리뷰, (CH 3.3) 다차원 배열의 계산 (0) | 2025.03.05 |


