
1. DCGAN
GAN 시리즈의 2번째 논문, DCGAN다.
기존의 GAN은 학습이 불안정하다는 문제가 있었다. 터무니 없는 데이터를 생성하기도 하고, Mode collapse 문제가 발생하기도 했다.
DCGAN은 이러한 문제를 해결하기 위해 CNN을 GAN에 적용시킨 모델이다.
Model Architecture
CNN 아키텍처를 GAN에 도입하려고 한 시도는 이 논문이 처음이 아니지만, 성공적이지 못했다. 그리고 DCGAN 연구진분들 역시 주로 Supervised Task에 사용되는 CNN을 사용하여 GAN을 조정하는 것에서 어려움을 겪었다고 밝히고 있다.
하지만 DCGAN이 발표된 2016년 당시 최신의 CNN 학습 테크닉을 도입함으로써 이를 극복할 수 있었다고 한다. 이 테크닉 다음과 같다.

1. Replace any pooling layers with strided convolutions (discriminator) and fractional-strided convolutions (generator).
먼저 첫번째로는 모든 네트워크에 있는 pooling function을 Strided convolution으로 교체했다고 말하고 있다.
일부 픽셀의 gradient 손실 문제를 해결하기 위해, 기존의 max pooling이 아닌 strided convolution을 적용한 pooling 기법으로 각 레이어마다 이미지를 축소했다는 것이다.
2. Use batch norm in both the generator and the discriminator.
Batch Normalization을 적용하여 학습 과정에서 변화하는 불안정성 해결, 이를 통해 Generator가 여러 sample을 하나의 point에 collapse해버리는 문제를 해결했다고 한다. 다만, 모든 레이어에 적용하는 것은 오히려 부작용을 낳아 Generator output과 Discriminator input에서는 적용하지 않았다.
3. Remove fully connected hidden layers for deeper architectures.
모든 네트워크에 있는 Fully connected layer 제거하고 Convolution layer로 대체했다.
4. Use ReLU activation in generator for all layers except for the output, which uses Tanh.
5. Use LeakyReLU activation in the discriminator for all layers.
Generator에서 Tanh를 쓰는 output layer를 제외한 모든 layer에서 ReLU를, Discriminator에서는 모든 layer에서 LeakyReLU를 사용했다. 그냥 여러 함수 사용해보고 결정한, empirical한 결과이다.
Results
GAN 모델의 학습 결과를 평가하기 위해서 Discriminator의 Feature Map을 이용한 Classification task를 수행했고, 기존의 classification 모델들과 엇비슷한 성과를 보였다.

Investigating
Walking in the latent space

만약 이미지를 외우는 방식으로 학습이 진행되었다면 latent space에서 움직이는 사진 중에서 갑작스런 변화가 있을 수 있다. 그러나 smooth하게 변화하는 사진의 양상으로 볼 때, 학습이 잘 진행되었음을 확인할 수 있다.
Visualizing discriminator features

guided backpropagation을 사용하여 Discriminator가 학습한 feature들을 시각화할 수 있다. 학습이 충분히 이루어진 모델은 semantically relevant한 feature들을 학습한 것을 확인할 수 있지만, 왼쪽의 baseline 모델은 의미있는 학습을 못한 것을 볼 수 있다.
Forgetting to draw certain objects

Generator가 어떤 representation을 학습했는지를 확인하기 위해 generator의 feature activation에서 window를 나타내는 것을 아예 지워보고 실험을 진행한 결과 침실에서 등장할 법한 다른 object(문, 거울)들로 대체된 것을 통해 이미지 scene의 semantic과 object semantic이 분리되어 학습된다는 것을 알 수 있다.
Vector arithmetic on face samples

generator의 input noise vector z로 덧셈과 뺄셈을 시도하며 실험한 결과물입니다. 어색한 면이 있지만, 의도한 대로 semantic relevance를 학습했다는 것을 알 수 있습니다.
2. Cycle GAN

기존의 GAN의 경우, 완벽히 한 쌍을 이루는 데이터만 사용해 학습할 수 있었다. 하지만, 완벽히 같은 조건을 지니는 데이터를 구하기는 매우 어렵다.
이러한 점을 해결한 논문이 바로 CycleGAN이다.
기존의 GAN으로 말 이미지를 얼룩말 이미지로 바꾸기 위해서는 똑같은 배경의 얼룩말 사진을 학습시켜야 한다면,
CycleGAN의 경우 어떤 이미지든 얼룩말이 있는 이미지를 통해 학습시킬 수 있다.
Introduction
그렇다면, CycleGAN은 어떻게 특징이 다른 두 도메인 데이터를 온전하게 변환하는 법을 배우는 걸까?
우선, 이러한 방식으로 변환하기 위해서는 도메인 간에 관계가 존재한다는 가정이 필요하다. X와 y_hat = G(X)가 대응되어야 한다는 것이다.
이는 쉽게 해결할 수 있다.
특정 이미지 X와 Generator G가 주어졌을 때 Discriminator는 y_hat = G(x)와 Y를 구분하게끔 학습한다면,
적어도 input X에 해당하는 output y_hat이 도메인 Y에 속하는 이미지인 것처럼 학습할 수 있기 때문이다.
다만, 해당 방식의 translation은 각각의 input x와 y_hat이 의미있는 방식으로 짝지어지는 것을 보장하지 않으며,
종종 mode-collapse (어떤 input 이미지든 모두 같은 output 이미지로 도출되는 것)로 이끌곤 한다.
이러한 이슈를 해결하기 위해 cycle consistent (주기적 일관성)이라는 속성을 도입했다.
이때, cycle consistent는 영어로 된 문장을 불어로 번역했다면 해당 불어 문장을 다시 영어로 번역 시 본래의 문장이 도출되어야 함을 의미한다.
따라서 G와 F를 동시에 학습하고 F(G(X)) ≈ x, F(G(X)) ≈ x이게 만드는 cycle consistency loss를 추가함으로써,
cycle consistency loss와 adversarial loss를 X와 Y에 적용한 전체 목적함수가 완성되었다.
Method

기본적으로 CycleGAN은 2개의 GAN을 필요로 한다.
X에서 Y의 이미지를 만들어주는 Generator와 이 이미지가 진짜인지 판단하는 Discriminator, 그리고 역방향 학습까지 고려하기 때문이다.
해당 논문에서 제안하는 파이프라인을 구축하기 위한 Component는 다음과 같다.
- Generator G : X → Y mapping
- Generator F : Y → X mapping
- Discriminator Dy : 실제 도메인 Y의 이미지 y와 G가 생성한 y_hat=G(x)을 구분
- Discriminator Dx : 실제 도메인 X의 이미지 x와 F가 생성한 x_hat=F(y)을 구분
Adversarial loss
함수 G : X → Y와 Dy에 대해서는 아래와 같은 목적함수를 적용한다.

여기서, G는 위의 함수를 최소화 D는 위의 함수를 최대화시키고자 하며 이는 다음과 같이 나타낼 수 있습니다.

마찬가지로, 함수 F : Y → X와 Dx에 대해서도 다음과 같이 나타낼 수 있습니다.

Cycle consistency loss
Unpaired data는 이미지 간의 대응 관계가 너무 많기 때문에 만들어진 이미지가 실제 이미지와 한 쌍이라고 확정지을 수 없다.
오히려 mapping의 제약이 적기 때문에 mode-collapse를 초래할 수 있다. 이러한 문제를 해결하기 위해 cycle consistency loss를 도입하였다.

cycle consistency loss는 각각 생성한 이미지를 다시 원본으로 복구할때 원본과 복구 값 간의 거리를 구하는 것으로,
생성된 이미지가 다시 원본으로 대응될 수 있게끔 학습하면서 다양성을 최대한 제공하도록 한다.

cycle consistency loss가 유도한 결과는 다음과 같으며, 재건된 이미지 F(G(X))가 input 이미지 x와 유사함을 확인할 수 있다.

Full objective
앞서 설명한 loss를 합치면 전체 목적 함수는 다음과 같다.

λ는 두 함수(= 위 식에서의 첫 번째 항과 두 번째 항)의 상대적인 중요도에 따라 결정되며, 본 논문의 풀고자 하는 목표는 다음과 같습니다.

즉, X → Y GAN의 Adversarial Loss와 Y → X GAN의 Adversarial Loss를 더하고
각각 다시 원본으로 복구하는 cycle consistency loss 값을 더해준 값이 최종 Loss값이며,
이를 최소화하는 방향으로 G와 F를 학습하는 것입니다.
Limitations and Discussion
CycleGAN은 획기적인 방식으로 부족한 데이터 문제를 해결했지만, 당연히 한계도 존재한다.
CycleGAN은 주로 분위기나 색상을 바꾸는 것으로 스타일을 학습하여 다른 이미지를 생성한다. 따라서, 기하학적인 모양을 변경하는 데는 어려움이 있다.
또한, 데이터셋의 분포가 불안정하면 이미지를 제대로 생성할 수 없다.

다음 그림을 보면, 사과를 오렌지로 바꿀 때 단순히 색상만 변경된 것을 확인할 수 있다.
그 뿐만 아니라, 사람을 태운 말을 얼룩말로 바꿀 때 사람까지 얼룩말 무늬로 바뀌었다.
이는 학습한 데이터에서 사람이 얼룩말을 탄 이미지가 단 1장이었기 때문이다.
3. LSGAN (Least Squares GAN)
GAN의 학습은 굉장히 불안정하다. GAN의 학습 불안정 중, 특정 샘플에 대하여 gradient vanishing 문제가 발생하는 경우가 있다.
Discriminator의 decision boundary (real과 fake를 구분하는)에서 멀리 떨어져 있는 fake sample에 대하여, gradient가 너무 작아 훈련이 제대로 일어나지 않는다. 즉, fake sample을 decision boundary에 가깝게 만들어 real sample가 구분하기 어렵기 하고 싶은데 그것이 잘 일어나지 않게 된다.

각 그래프에 파란색 선은 sigmoid의 decision boundary를 의미한다. 주황색 선은 논문에서 사용된 기법인 least square이 적용된 decision boundary이다. (b)에서 추가된 별표의 fake sample들은 decision boundary에서 멀리 떨어져 있는, correct class에 속해있는 sample들이다. 이들을 Discriminator에 집어넣어 얻은 결과의 gradient는 너무 작기 때문에 Generator를 충분히 학습시키는 데 어렵다.
그런데, 만약 Least square 방식을 사용하면 어떨까? 즉, decision boundary와의 거리를 반영하여 gradient를 계산한다면, 특정 기준을 세우고 그 지점까지의 least square한 loss를 구하게 discriminator를 만든다면, 멀리 있는 sample들을 boundary 주변으로 끌어당기는 데 효과적일 것이다.
LSGAN의 목표는 새로운 loss function을 통해 GAN의 훈련을 안정화시키고, 좋은 품질의 이미지를 생성하는 것이다.
Method
기존 GAN의 Discriminator는 sigmoid cross entropy loss를 이용하여 fake(0)와 real(1)을 구분하였다. 즉, classifier의 역할을 하고 있는 셈이다. 아래는 그러한 loss function과 least square loss function에 대한 비교입니다.
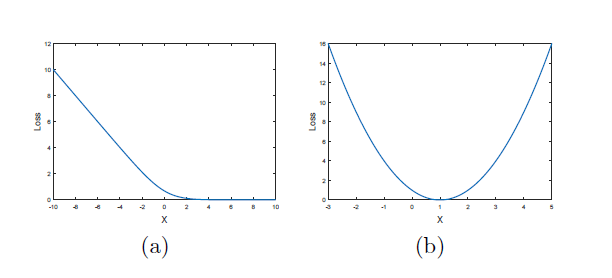
sigmoid가 x의 값이 커질 수록 loss값이 0에 가깝게 saturation이 일어나 gradient에 문제가 일어나는 것과 달리,
least square의 경우 특정 지점에서만 0이 되고, 그 외에는 거리에 quadratic하게 반응하는 것을 알 수 있다.
만약 a를 fake data의 라벨, b를 real data의 라벨, c를 G가 D를 속이는 라벨이라 한다면, 아래와 같은 식을 세울 수 있다.

Least square 형태의 loss fucntion이 두 개가 만들어지게 된다. 즉, decision boundary와의 거리 값을 기준으로(square하게 만들어준 이유), 그 거리 값에 비례하여 loss를 구성하여 멀리 떨어져있을 수록 더 많이 gradient를 계산하게 하는 것이 목적이다.
LSGAN의 식을 자세히 보면, 잘 분류된 sample들 역시도 decision boundary에 멀리 있을 경우 큰 gradient를 갖게 penalize 시켜준다. 이 때, G를 잘 업데이트 하기 위해 거리를 계산하므로, D를 freeze하여 decision boundary는 가만히 둔다. 좋은 decision boundary는 실제 데이터의 manifold를 가로 질러야 하는데, 생성되는 모든 샘플들을 decision boundary로 보냄으로 인해 생성된 샘플의 분포가 실제 데이터의 분포와 가까워지게 만든다.
LSGAN의 loss function에 optimal한 Discriminator를 가정하여 식을 푸면 아래와 같이 된다.



맨 아래식은 Pearson divergence의 형태로, 데이터의 분포와 생성된 데이터의 분포 사이의 divergence를 나타내게 된다. 정확히는 데이터의 분포 + 생성 데이터의 분포 와 2 * 생성 데이터의 분포 사이의 divergence를 나타내는 데, objective function을 최소화하는 것은 결국 이 pearson divergence를 최소화하는 것이 된다.
또한 LSGAN은 GAN의 문제점 중 하나인 mode collapse도 해결한다.
아래 그림은 gaussian dataset에 대한 실험으로, Gaussian kernel density estimation을 한 결과이다.

기존 GAN이 15k의 step부터 한 mode만 생성하는 것과 달리, LSGAN은 다양한 mode를 잘 만들어내는 것을 확인할 수 있다. 아마도 decision boundary에 근접한 data 숫자가 많아져서, mode를 다양하게 만들어낼 가능성이 높아진 거 같다.



