
https://arxiv.org/abs/1411.1792
How transferable are features in deep neural networks?
Many deep neural networks trained on natural images exhibit a curious phenomenon in common: on the first layer they learn features similar to Gabor filters and color blobs. Such first-layer features appear not to be specific to a particular dataset or task
arxiv.org
general/specific의 관념적 정의
- 첫 번째 레이어에서 standard features을 찾는 것은 정확한 cost function과 natural image dataset과 관계없이 발생한다 ⇒ 첫 번째 레이어의 features는 general (일반적이다)
- 마지막 레이어에서 계산된 features는 선택된 dataset과 task에 크게 의존해야 한다 ⇒ 마지막 레이어의 features는 specific (특수하다)
즉, 네트워크의 어딘가에서 general → specific 인 것으로 전환(transition)되어야 한다.
- 특정 레이어가 general/specific한 정도를 정량화할 수 있는가?
- Transition이 단일 레이어에서 갑자기 발생하는가, 아니면 여러 레이어에 걸쳐 일어나는가?
- 이 transition는 네트워크의 first, middle, last 레이어 근처 어디에서 발생하는가?
transfer learning
- ① 먼저 base dataset과 task에 대해 base network를 훈련한 다음 ② 학습된 features의 용도를 바꾸거나 두 번째 target network로 전송(transfer)하여 ③ target dataset과 task에 대해 학습한다
- base network를 훈련시킨 다음 첫 번째 n개의 레이어를 target network의 첫 번째 n개 레이어로 복사한다
- Target network의 남은 레이어들은 random 초기화되고 target task을 위해 학습한다
- New task의 error를 base (copied) features으로 역전파하여(backpropagate) new task에 맞게 fine-tune하도록 선택할 수 있고 또는 transfer된 feature layer는 frozen 상태로 둘 수 있다.
- target network의 첫 번째 n개의 레이어를 fine-tune할지 여부는 target dataset의 크기와 첫 번째 n개 레이어의 파라미터 수에 따라 달라진다.
- Target dataset ↓ & 파라미터의 수 ↑: fine-tuning의 결과 overfitting인 경우가 많음
- target dataset ↑ & 파라미터의 수 ↓: overfitting이 문제되지 않음 → base features을 new task에 fine-tune하여 성능을 향상시킬 수 있음
- target dataset ↑↑↑: target dataset에서 하위 레벨의 filters을 처음부터 학습할 수 있기 때문에 transfer할 필요가 거의 없음
논문의 주제
- 특정 레이어가 general/specific 정도(= 해당 레이어의 features가 한 task에서 다른 task로 얼마나 잘 전달되는지)를 정량화하는 방법을 정의함 ⇒ Section 2 ⇒ 실험 1 & 실험 2
- the degree of generality 정의: task A에 대해 학습한 features의 generality = 다른 task B에 대해 사용할 수 있는 범위
- A와 B의 similarity에 따라 달라짐
- dataset들의 similarity가 높을 수록 더 잘 transfer하며 높은 성능을 발휘함을 예상
- fine-tuning 없이 transfer한 features을 사용할 때 성능 저하를 유발하는 두 가지 개별 문제/이슈를 실험적으로 제시함
⇒ Section 4.1- features 자체의 특이성(specificity)
- 이웃 레이어의 co-adapted 뉴런 사이에서 base network를 분할하는 것으로 인한 최적화 어려움
- base task와 target task의 dissimilar에 따른 transferring feature의 성능 감소를 정량화함
- 작은 규모의 dataset에서의 연구와 비교하여, 상대적으로 큰 규모의 ImageNet dataset에서는 random lower-layer weights로 계산된 features를 사용할 때 낮은 성능이 나타남. random weights와 (frozen/fine-tuned) transferred weights를 비교하여 transferred weight가 더 나은 성능을 보임 ⇒ 실험 3
- 거의 모든 레이어에서 transferred features를 가진 network를 초기화하면 새로운 dataset으로 fine-tuning한 후 일반화(generalization) 성능이 향상될 수 있음
실험 1 — A and B are similar (Section 4.1)
- Setting
- ImageNet dataset → 중복되지 않는 subset
- 1000개의 ImageNet classes를 무작위로 500개의 클래스씩(= 각 645,000 examples) 두 그룹으로 나눔 ⇒ similar
- Process
- baseA & baseB
- baseA: dataset A에서 학습한 하나의 8-layer convolutional network
- baseB: dataset B에서 학습한 하나의 8-layer convolutional network
- 레이어 n을 선택하고 여러 개의 새로운 네트워크를 훈련함
- Figure1: n=3
- baseA & baseB

- Network — transferred layers are frozen
- selffer network B3B
① 처음 3개의 레이어(1-3): (dataset B에서 학습한) baseB에서 복사되어 frozen됨
② 그 다음 상위 5개의 레이어(4-8): random 초기화 후 dataset B에서 features를 학습함 - transfer network A3B
① (dataset A에서 학습한) baseA에서 첫 3개의 레이어를 복사하여 frozen → 처음 3개의 레이어(1-3)
② 그 다음 상위 5개의 레이어(4-8)를 random 초기화 후 dataset B에서 features를 학습함
③ 새로운 target dataset B에 대해 classification됨 - 결과 분석
- A3B가 baseB만큼 성능이 우수한 경우 ⇒ 적어도 B에 대해 third-layer의 feature가 “general”
- A3B가 baseB보다 성능이 낮은 경우 ⇒ third-layer의 feature가 A에만 “specific”
- selffer network B3B
- Network — transferred layers are fine-tuned
- selffer network B3B+: B3B와 비슷하지만 모든 레이어가 학습함
- transfer network A3B+: A3B와 비슷하지만 모든 레이어가 학습함

Figure 2: base case(흰색 원⚪, 점선)와 성능을 비교하여 나타냄
⚪ baseB
- 500개 클래스의 random subset을 분류하도록 훈련된 네트워크
- top-1: accuracy of 0.625, or 37.5% error
🔵 selffer BnB (Dark blue)
- layer 1, 2: baseB와 동일한 성능
- layer 3, 4, 5, 6: 특히 layer 4와 layer 5에서 더 나쁜 성능이 나타남 ⇒ 연속적인 레이어에서 취약한 co-adapted features를 포함하고 있기 때문
- co-adapted features: 재학습할 수 없도록 복잡하거나 취약한 방식으로 상호 작용하는 features
- layer 6, 7: base level으로 거의 돌아감
- 재학습할 것이 적어지고
- 한두 개의 레이어를 재학습하는 것은 gradient descent으로 해결할 수 있음
- layer 6-7, layer 7-8: 이전 레이어에 비해 feature의 co-adaption이 적음
⇒ 최적화 어려움은 네트워크 middle에서 bottom이나 top 근처보다 더 심각할 수 있음을 발견함!
🔹 transfer BnB+ (light blue)
- lower-layer features가 target datset에서 학습할 때 base case와 비슷함 (동일하게 base dataset 사용)
⇒ fine-tuning은 BnB network의 성능 저하를 방지함!
🟥 transfer AnB (dark red)
- layer 1, 2: A에서 B로 거의 완벽하게 transfer됨 → first-layer의 Gabor and color blob features general & second layer의 features가 “general”
- layer 3: 약간의 성능 하락을 보임
- layer 4-7: 더 큰 폭의 성능 저하를 보임
⇒ 🔵 BnB를 참고하면, ① co-adaptation 손실 (layer 3, 4, 5) ② 점점 더 일반적이지 않은 feature로 인한 성능 저하를 원인으로 분석할 수 있음 (layer 6, 7)
⇒ transferability of features from one network to another at each layer
🔸 transfer AnB+ (light red)
- feature를 transfer한 후에 fine-tuning하면 target dataset에서 직접 학습한 것보다 더 잘 일반화되는 네트워크가 형성됨
- 이전에 transfer한 이유: 작은 크기의 target dataset에 overfitting 없이 학습을 가능하게 하기 위함
- 새로운 결과 → target dataset이 크더라도 transfer하여 일반화 성능을 향상시킬 수 있음

- BnB+의 학습 시간 > AnB+의 학습시간 → AnB+의 성능이 더 높음 ⇒ 성능 향상이 총 학습 시간에 기인하지 않음
- 450k번의 fine-tuning을 반복하는 동안, 즉 수많은 재학습 중에도 base dataset을 학습이 영향을 미침 ⇒ 더 많은 레이어에서 유지할수록 성능이 향상됨
실험2 — A and B are dissimilar (Section 4.2)
- Setting
- ImageNet dataset: 부모 클래스의 계층 구조 제공
- dataset A: man-made entities만 포함 (551 classes) dataset B: natural entities를 포함 (449 classes) ⇒ dissimilar
- base task와 target task의 유사도가 낮을 수록 feature transfer의 효과가 떨어질 것으로 예상함

- 흰색 원: baseA & base B, 주황색 육각형: BnA & AnB
- 동일한 target task
- Natural이 Man-made보다 높은 accuracy: ① 551개가 아닌 449개의 클래스만 있거나 ② 단순히 더 쉬운 작업이기 때문
실험3 — random weights (Section 4.3)
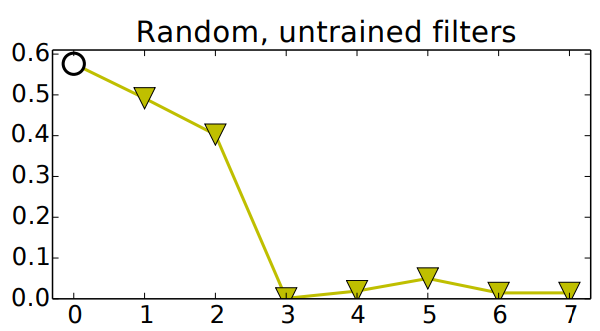
- 다양한 n개의 선택 → 처음 n개의 레이어에 대해 random filters를 사용할 때 얻은 accuracy
- layer 1, 2: 성능이 빠르게 떨어짐
- layer 3+: 거의 가능성이 없는 수준(near-chance level)으로 떨어짐
- 레이어 크기와 초기화 디테일을 조정하여 더 나은 random weights 결과를 얻을 수 있음

- x축: base dataset에서 학습한 레이어 n의 수, y축: (각 실험의 결과 - 각각의 base case)를 정규화한 성능
- frozen한 경우 transferability 격차: ‘random split’보다 ‘m/n split’에 대해 n이 증가함에 따라 더 빠르게 증가함
- distant task에서도 transfer하는 것이 random filter를 사용하는 것보다 나음
Conclusion
- neural network의 각 레이어에서 feature의 transferability를 정량화하는 방법을 제시함 ⇒ generality or specificity를 드러냄
- ① 취약한 co-adapted layer의 중간에서 네트워크를 분할하는 것과 관련된 최적화 어려움과 ② target task에 대한 성능을 희생시키며 original task에 대한 상위 레이어 feature의 specialization이라는 두 개의 개별 문제에 의해 transferability가 어떻게 부정적인 영향을 받는지 보여줌
- 네트워크의 bottom, middle 또는 top에서 feature가 transfer되는지 여부에 따라 두 가지 문제 (①, ②) 중 하나가 지배적일 수 있음을 확인함
- task의 거리가 멀수록, 특히 상위 레이어를 transfer할 때 transferability가 어떻게 증가하는지 정량화했지만, distant task에서 transfer된 feature도 random weight보다 낫다는 것을 발견함
- transferred feature로 초기화하면 새로운 task를 크게 fine-tuning한 후에도 일반화 성능을 향상시킬 수 있으며, 이는 deep neural network 성능을 향상시키는 데 일반적으로 유용한 기술이 될 수 있음을 발견함