https://arxiv.org/pdf/1804.04732
1. Introduction
- 기존 모델의 한계
기존에 존재한 CycleGAN을 비롯한 모델들은 입력과 출력이 1:1로 대응되어야 하는 한계점을 가짐
- 현실의 Multimodality 반영 불가
현실을 모사하는 것에는 한가지 정답이 아닌 다양한 정답지가 있을 수 있으나 현재 모델은 결정론적인 함수의 형태가 많음.
위의 한계점을 극복한 MUNIT의 모델을 연구팀은 제안하고자 함.
2. Multimodal Unsupervised Image-to-image Translation
1. Assumtion
xi ∈ Xi 이고, x1 = G_1 (c, s1) x2 = G_2 (c, s2)라 하자.
여기서 c는 content code s는 style code를 의미하며 C는 도메인이 달라져도 변하지 않으나. s는 도메인이 달라짐에 따라 변한다고 가정함.
2. Model
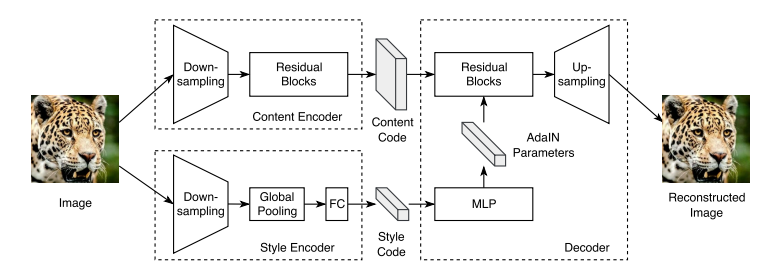

-Encoder
Content encoder과 sytle encoder로 나누어 이미지를 content code와 style code로 분리함.
-Decoder
Content code와 style code를 받아 이미지를 복원
3. Loss function

위에서 언급하였던 Cross-domain translation의 방법을 통해 생성한 이미지와 원본 이미지의 차이값을 손실함수로 사용함.

이때 LSGAN방식의 adversarial loss를 사용함.

최종적인 손실함수는 위와 같다.
3. Theoretical Analysis
1. 위의 가정이 완벽하다면 MUNIT의 로스 함수는 Cycle Consistency를 내포한다.
2. image reconstruction losses와 latent reconstruction losses, adversarial losses가 모두 0이면, 두 translation model이 유도하는 joint distributions는 서로 일치한다.
3. MUNIT가 최적화 되었을 때 ontent-style disentanglement 성립한다.
4.Bijective mapping이 성립한다.
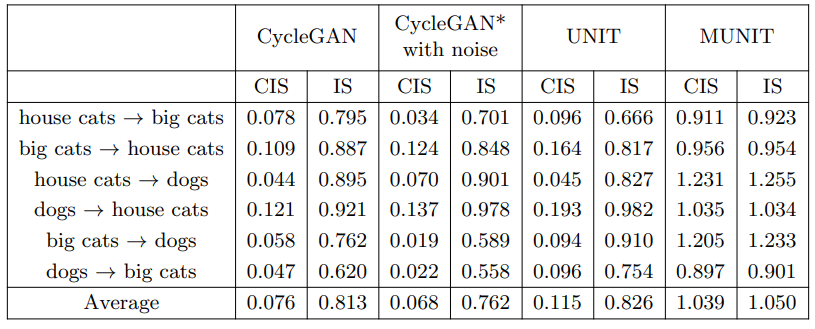
4. Experiments