
본 글에서는 Transformer의 Multi Head Attention에서 헤드의 수 증가로 인해 각 헤드의 표현력이 감소하는 문제를 해결하기 위해, head dimension에서의 linear projection을 통해 헤드 간 정보를 섞는 Talking-Heads 구조를 살펴본다.
1. Introduction
Transformer (Vaswani et al., 2017)는 멀티 헤드 어텐션 구조를 통해 다양한 관계를 기반으로 동시에 여러 위치에 어텐션을 적용하여 성능을 향상시켰다. 하지만 헤드의 수를 늘리고 각 헤드의 차원을 줄이는 경우 (연산량 제약으로 인해 헤드 수와 각 헤드의 차원은 반비례 관계를 가짐) 각 헤드의 표현력이 감소하게 되고, 그 결과 query 벡터와 key 벡터의 dot product가 충분한 정보를 담지 못한다.
이 논문에서는 이러한 문제를 해결하기 위해 Talking-Heads Attention을 제안한다. 이는 기존 Transformer의 attention 구조에서 softmax 함수의 앞뒤에 각각 head dimension 방향의 학습 가능한 linear projection을 추가하는 방식이다.
이를 통해 각 attention은 특정 헤드의 정보에만 의존하지 않고, 여러 헤드의 정보를 함께 활용할 수 있게 된다. 즉, 기존 구조에서 헤드 수 증가로 인해 발생하는 표현력 감소 문제를, 헤드 간 정보 공유를 통해 해결하려는 접근이다.
결과적으로 Talking-Heads 구조는 masked language modeling task에서 더 낮은 perplexity를 보였으며, language comprehension 및 question answering task에서도 성능 향상을 달성하였다.
2. Review of Attention Algorithms
- Dot-Product Attention
: Dot-product attention은 query와 memory 간의 dot product를 통해 attention score를 계산하고, 이를 softmax로 정규화한 뒤 value의 가중합을 통해 출력을 생성하는 구조이다. - Dot-Product Attention with Projections
: Transformer에서는 연산 효율성을 위해 입력을 그대로 사용하지 않고, learned linear projection을 통해 query, key, value를 생성한 뒤 attention을 수행한다. 즉, 입력 $X$, $M → projection → Q$, $K$, $V → attention$ 계산 구조를 가진다. - Multi-Head Attention
: Multi-head attention은 여러 개의 attention을 병렬로 수행하는 구조로, 각 head는 서로 다른 projection을 통해 서로 다른 representation space에서 attention을 계산한다. 이를 통해 다양한 관계를 동시에 학습할 수 있다.
3. Talking-Heads Attention
기존 multi-head attention에서는 각 head가 독립적으로 attention을 계산한 뒤 마지막 단계에서만 결과를 합치는 구조를 가진다. Talking-Heads Attention은 이러한 head 간 독립성을 깨고, attention 계산 과정에서 head 간 정보를 공유하도록 만든 구조이다.


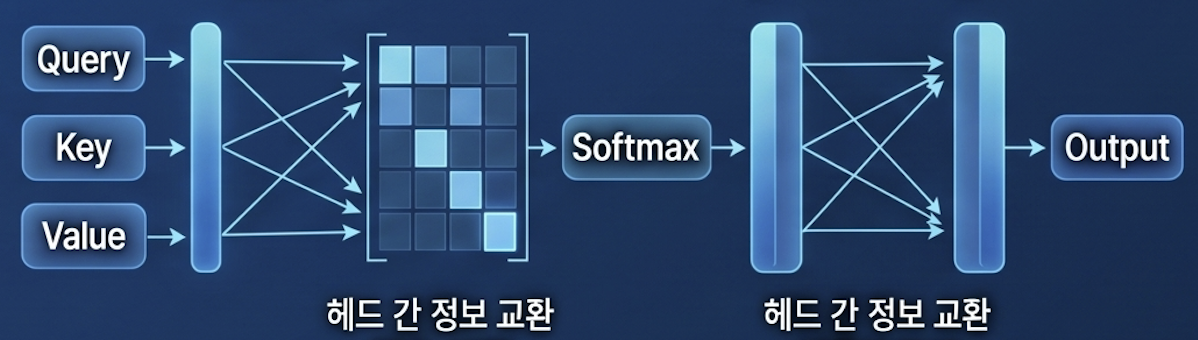
이를 위해 논문에서는 두 개의 학습 가능한 linear projection을 추가한다.
- $P_l$: attention logits ($QK^T$ 결과)에 적용 (softmax 이전)
- $P_w$: softmax 이후의 attention weights에 적용
➡️ Talking-Heads 구조는 logits 단계에서 head dimension 방향으로 projection을 적용하여 head 간 정보를 섞고 → softmax 이후에도 다시 한 번 projection을 적용하여 weight를 재조정한 뒤 → value를 가중합 한다.
또한 기존에는 하나의 head dimension만 존재했지만, Talking-Heads에서는 다음과 같이 세 가지 head dimension을 구분한다.
- $h_k$: query와 key를 위한 head 수
- $h$: logits 및 attention weights를 위한 head 수
- $h_v$: value를 위한 head 수
이들은 서로 다른 크기를 가질 수 있다. (기존 Transformer는 Q/K/V 각각에 대해 따로 head 수를 정의하는 개념 자체가 없음)
4. Complexity Analysis
Talking-Heads Attention은 기존 multi-head attention에 비해 추가적인 연산이 필요하지만 전체 연산량 관점에서는 큰 차이를 만들지 않는다. 기존 multi-head attention의 연산량은 head 수와 query/key/value 차원에 비례하며, Talking-Heads에서도 기본적인 연산 구조는 동일하다.
추가되는 연산은 head dimension에서의 projection($P_l$, $P_w$)으로, 이는 attention logits과 weights에 대해 수행된다.
하지만 일반적으로 $h < d_k, d_v$인 경우가 많기 때문에, 이 추가 연산의 비용은 기존 attention 계산에 비해 상대적으로 작다.
다만, 실제 구현에서는 이러한 projection이 작은 차원에서 수행되기 때문에 일부 하드웨어 환경에서는 비효율적으로 동작할 수 있다.
5. One More Way To Look At It
Multi-head attention과 Talking-Heads attention은 일반적인 형태의 attention 구조인 General Bilinear Multihead Attention (GBMA)의 특수한 경우로 볼 수 있다.
GBMA는 query와 memory 간의 관계를 하나의 bilinear 함수 형태로 직접 모델링하는 구조로,더 일반적이지만 계산 비용이 매우 크다.
기존 multi-head attention은 이 bilinear 구조를 두 개의 projection으로 분해한 형태로 볼 수 있으며, Talking-Heads attention은
여기에 추가적인 projection을 더해 보다 유연한 표현이 가능하도록 확장한 구조로 해석할 수 있다. 즉, Talking-Heads는 기존 multi-head attention보다 더 일반적인 형태의 attention을 근사하는 방식이다.
6. Experiments
1. Multi-Head vs Talking-Heads
실험 결과, 모든 설정에서 Talking-Heads가 기존 multi-head attention보다 더 나은 성능을 보였다. 특히 head 수를 증가시키고 각 head의 차원을 줄이는 경우, 기존 multi-head attention은 성능이 감소하는 반면 Talking-Heads는 오히려 성능이 지속적으로 향상되는 경향을 보였다
➡️ 이는 key/query 차원이 너무 작아질 때 발생하는 표현력 부족 문제를 Talking-Heads가 완화해주기 때문으로 해석된다.
2. Head Dimension 분석
Talking-Heads에서 분리된 세 가지 head dimension ($h_k$, $h$, $h_v$)을 독립적으로 조절한 결과, 세 dimension 모두 성능에 영향을 주지만 특히 softmax에 해당하는 head dimension $h$가 중요하게 작용함을 확인하였다.
3. Projection 효과 분석
logits projection $P_l$ 과 weights projection $P_w$을 각각 따로 적용한 경우에는 성능 향상이 제한적이었다. 두 projection을 모두 사용하는 경우에만 Talking-Heads의 성능 개선 효과가 크게 나타났다.
4. 적용 위치 분석
Transformer의 다양한 attention layer 중, encoder self-attention에 Talking-Heads를 적용했을 때 가장 큰 성능 향상이 나타났다.
5. 다양한 모델에서의 검증
T5, ALBERT, BERT 등 다양한 모델에서 실험한 결과, 기존 multi-head attention은 head 수 증가 시 성능이 감소하는 반면, Talking-Heads는 head 수 증가에도 성능이 유지되거나 향상되는 경향을 보였다.
6. Projection Matrix 분석
학습된 projection matrix를 시각화한 결과, 특정 head에만 의존하는 구조가 아니라 여러 head 간 정보가 고르게 섞이는 패턴이 확인되었다.

➡️ 이는 Talking-Heads가 실제로 head 간 정보 교환을 수행하고 있음을 보여준다.
7. Conclusion and Future Work
본 논문에서는 head 간 독립적으로 계산되던 기존 multi-head attention 구조를 개선하기 위해, attention 계산 과정에서 head 간 정보를 공유하는 Talking-Heads Attention을 제안하였다. 실험 결과, 다양한 모델과 설정에서 Talking-Heads가 기존 구조보다 더 나은 성능을 보임을 확인하였다.
다만, Talking-Heads에서 추가된 projection 연산은 차원이 작은 행렬 연산으로 이루어져 있어, 일부 하드웨어 환경에서는 비효율적으로 동작할 수 있다.
이에 따라 다음과 같은 연구 방향이 향후 과제로 남아있다.
- 소규모 행렬 연산에 최적화된 하드웨어 설계
- local attention, memory-compressed attention과 같은 방식으로 attention 연산 범위를 줄이는 방법