
https://papers.nips.cc/paper_files/paper/2012/hash/c399862d3b9d6b76c8436e924a68c45b-Abstract.html
1. Introduction
- AlexNet 이전의 객체 인식 모델은 대부분 고전적인 ML 모델
- 수만개 정도의 작은 데이터셋(NORB, Caltech-101/256, CIFAR-10/100)을 사용
- 수십만 개의 완전 분할 된 이미지로 구성된 LabelMe 등장
- 1500만 개 이상의 고해상도 이미지로 구성된 ImageNet 등장
- 등장한 데이터셋을 처리하기 위해, 높은 학습 역량을 가진 모델 필요
- 사용되지 않은 데이터에 대해서 추론을 할 수 있는 사전 지식을 담아내야 함
→ 이에 논문은 컨볼루션 신경망(CNN) 모델을 기반으로 하는 AlexNet을 제시
2. Overall Architecture
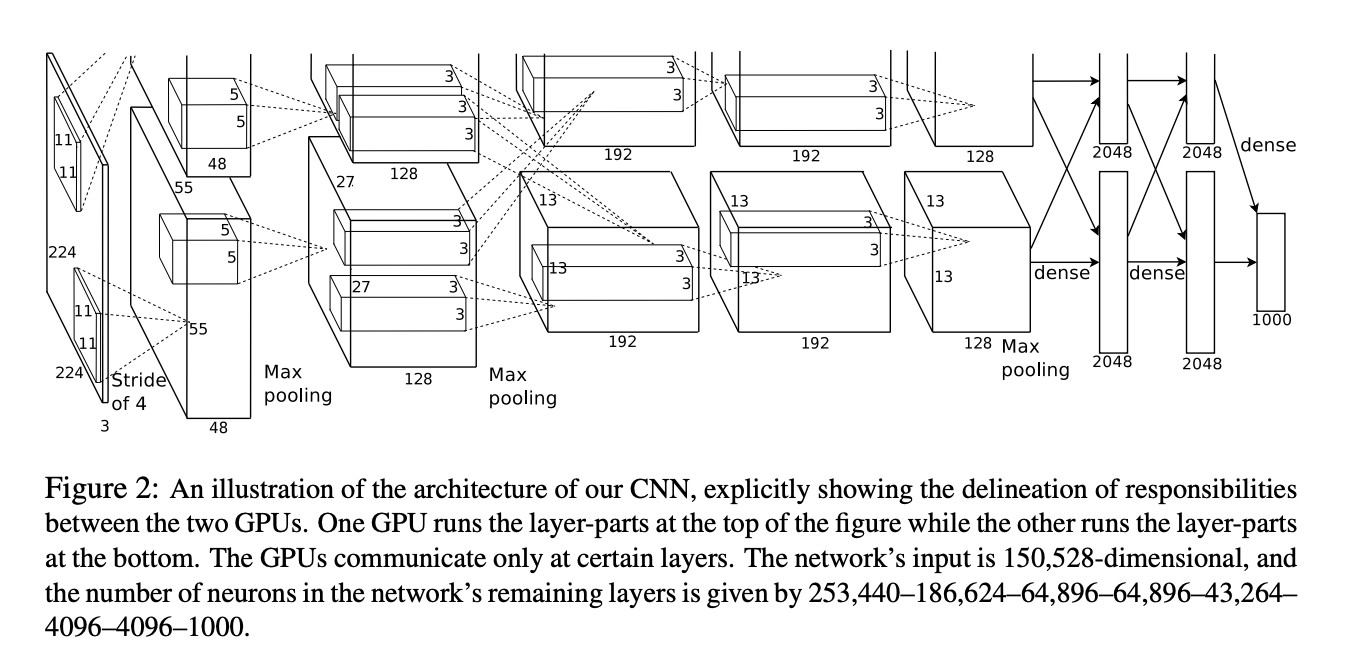
- 6000만 개의 Parameters, 650,000개의 Neuron을 가지며, 8개의 layer로 이루어짐
- 5개의 convolution layer(+max pooling)과 3개의 fully-connected layer, 1000 way softmax로 이루어짐
사용기법
- ReLUs
- GPU 2대 병렬로 사용
- local response norm
- overlapping pooling
- data augmentation
- dropout
3. The Dataset

- 1000개의 이미지 카테고리 각각에 약 1000개의 이미지
- test dataset이 라벨링된 ILSVRC-2010 데이터를 주로 사용
- 120만개의 Train Set, 50,000개의 Validation Set, 150,000개의 Test Set 사용
- 256 × 256의 고정 해상도로 down sampling을 수행
- 직사각형 이미지는 scaling 후 중앙 256x256 패치로 잘라냄
4. The Architecture
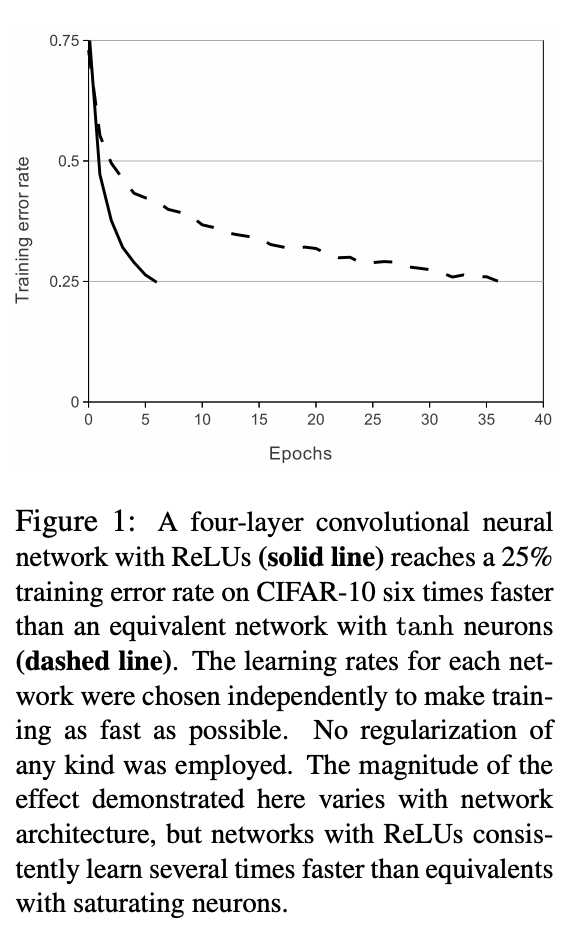
(1) ReLU Nonlinearity

Traditional Activation Fuction
- Tanh
- Sigmoid
ReLUs VS Tanh
- 둘다 정규화X
- Learing Rate는 각자 최적으로 맞춤
- ReLUs가 Tanh에 비해, 약 6배 빨리 수렴
(2) Training on Multiple GPUs

- GPU 메모리 제한과 느린 학습 속도 개선을 위한 병렬학습 방법 제안
- 네트워크를 분할하여 서로 다른 GPU에서 병렬적으로 연산을 수행(특정 레이어에서만)
- Top-1, Top-5 error rate를 1.7, 1.2% 절감
(3) Local Response Normalization

- CNN에서 인접한 필터를 사용하여 normalization을 진행
(논문에서는, k=2, n=5, α=10^(-4), β=0.75 사용)
- Top-1/Top-5 error rate를 1.4%/1.2% 개선
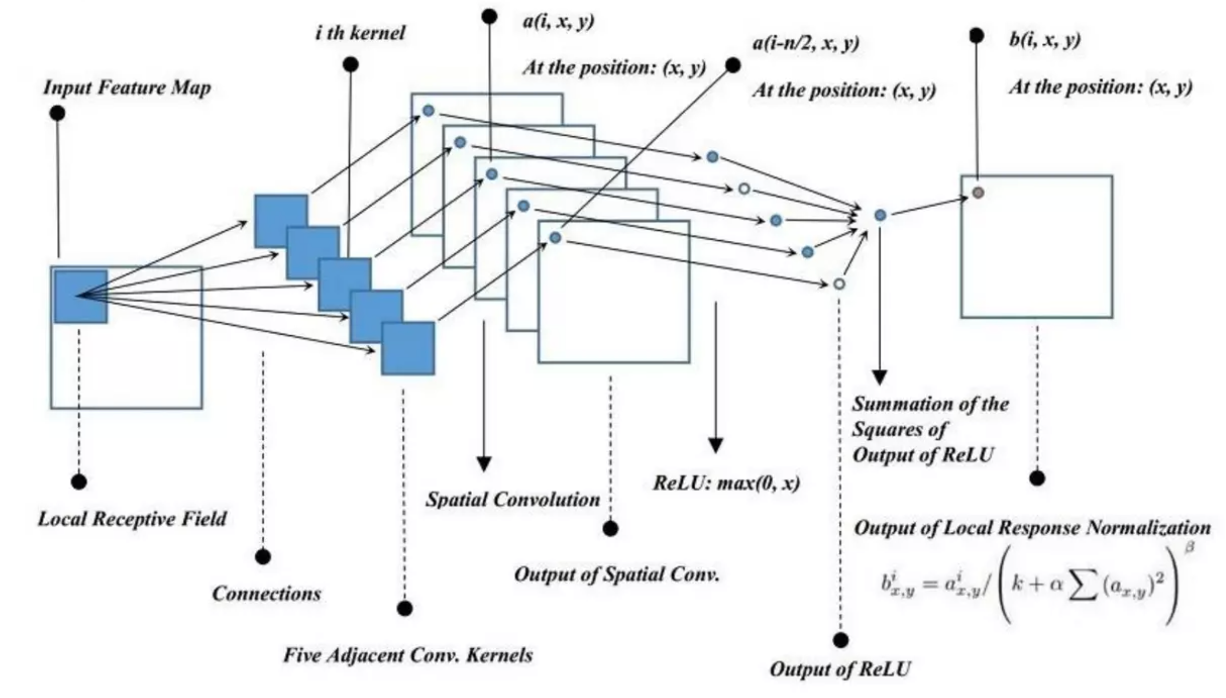
- 현재 10번째 커널이라면, 8번째 커널부터 12번째 커널까지의 제곱합으로 나누며 정규화를 진행
(4) Overlapping Pooling
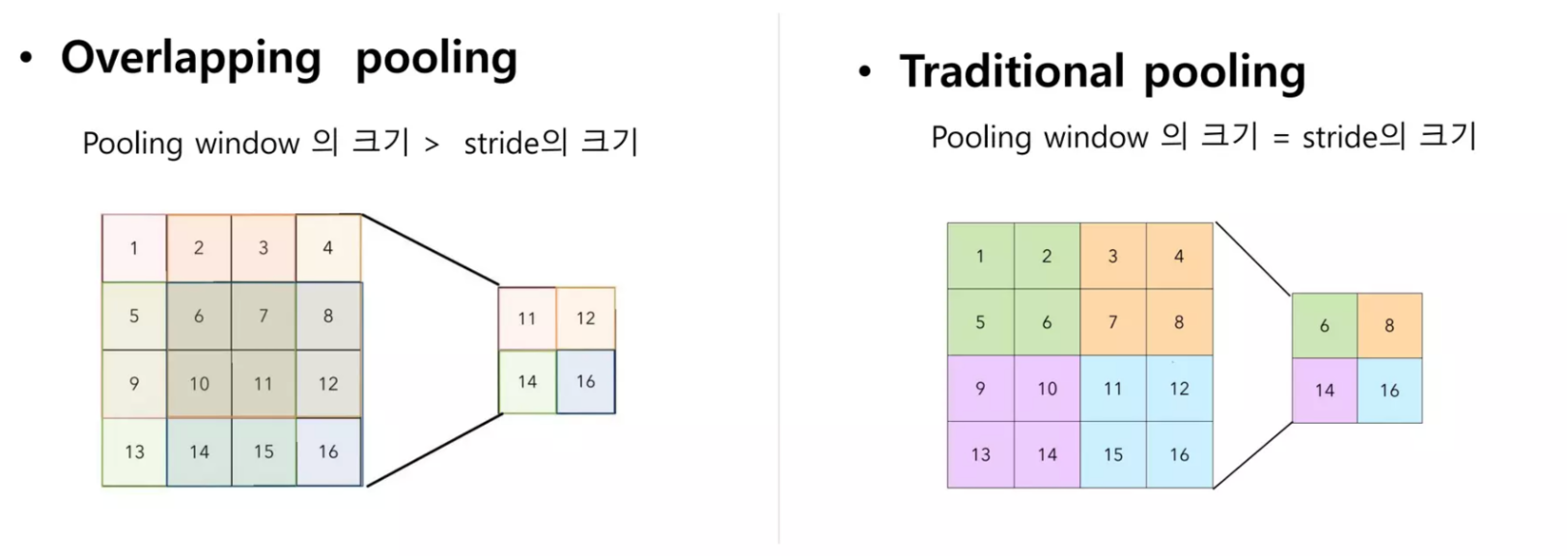
- Top-1, Top-5 error rate를 0.4, 0.3% 개선
(5) Overall Architecture

5. Reducing Overfitting
(1) 256 × 256 이미지에서 224 × 224 패치를 추출하고, 좌우반전

- 좌우반전하여 이미지 양을 2배로 증가
- 256 x 256 이미지를 랜덤으로 잘라 224 x 224로 만들어 1024배 증가
- 기존 데이터 셋의 2048배((256 – 224) * (256 - 224) * 2) 확장
- 실제: 5개의 224 × 224 패치 (4 개의 코너 패치 및 중앙 패치)와 수평 반사를 수행한 10개의 패치 사용
(2) RGB 채널 강도 조정
- 학습 데이터셋의 픽셀값으로 PCA를 수행
- PCA eigenvector 에 N(0,0.1) 인 정규분포에 추출한 랜덤값을 곱해 색상을 조정
- Top-1 error rate가 1% 감소
(3) Dropout

- 0.5의 확률로 Hidden Neuron의 값을 0으로 바꿔줌
- (a)와 같이, 망에 있는 모든 Layer에 대해 학습을 수행하는 것이 아님
- (b)와 같이, 망에 있는 일부 뉴런을 생략(Drop Out)하고 줄어든 신경망을 통해 학습 수행
- 3개의 Fully-Connected Layer 중 앞의 2개에만 적용
- 실제: DropOut 적용X, 대신 0.5를 곱해줌
6. Details of Learning

- Batch Size = 128
- Momentum = 0.9
- Weight Decay = 0.0005 (Training Error를 감소시킴, N(0, 0.01)에서 랜덤 추출해 가중치를 초기화)
- Learning Rate = 0.01 (Validation Error가 계속 변하지 않으면 0.1을 곱함, 실험 중 3번 바뀜)
- Epochs = 90
7. Results


Qualitative Evaluations


Figure 3은 네트워크의 두 데이터 연결 레이어가 학습한 컨볼루션 커널로, 224×224×3 입력 이미지에 대해 첫 번째 컨볼루션 레이어가 학습한 11×11×3 크기의 96개의 컨볼루션 커널이다. 위쪽 48개의 커널은 GPU 1에서 학습되었고, 아래쪽 48개의 커널은 GPU 2에서 학습되었다. 네트워크는 다양한 주파수 및 방향 선택 커널과 다양한 색상의 블롭을 학습했다. GPU 1의 커널은 대부분 color-agnostic하고, GPU 2의 커널은 대부분 color-specific하다. 이러한 종류의 전문화는 모든 실행 중에 발생하며 특정 무작위 가중치 초기화(GPU의 모듈러 번호 변경)와는 무관합니다.
Figure 4에서, 왼쪽은 8개의 ILSVRC-2010 테스트 이미지와 모델에서 가장 가능성이 높은 것으로 간주되는 5개의 라벨로, 각 이미지 아래에 올바른 레이블이 표시되어 있으며, 정답 확률도 빨간색 막대로 표시했다(top-5 속하는 경우). 오른쪽은 첫 번째 열에 있는 5개의 ILSVRC-2010 테스트 이미지로, 나머지 열은 테스트 이미지의 특징 벡터와 유클리드 거리가 가장 작은 마지막 숨겨진 레이어에서 특징 벡터를 생성하는 6개의 훈련 이미지를 보여준다. 진드기처럼 중심에서 벗어난 물체도 네트워크에서 인식할 수 있음을 알 수 있다. 상위 5개 레이블의 대부분 그럴듯 하지만, 그릴과 체리는 사진의 의도된 초점이 모호한 경우도 있다.
네트워크의 시각적 지식을 조사하는 또 다른 방법은 마지막 4096차원 hidden layer에서 이미지에 의해 유도된 특징 활성화를 고려하는 것입니다. 두 이미지가 euclidean distance가 작은 특징 활성화 벡터를 생성하면, 신경망의 상위 레벨에서는 두 이미지가 유사하다고 간주한다. Figure 4는 이 측정에 따라 tast dataset의 이미지 5개와 train dataset의 이미지 6개 중 가장 유사한 이미지를 보여준다. 픽셀 수준에서 검색된 훈련 이미지가 일반적으로 첫 번째 열의 쿼리 이미지와 L2가 가깝지 않다.
두 개의 4096차원 실수값 벡터 사이의 euclidean distance를 사용하여 유사도를 계산하는 것은 비효율적이지만, 이러한 벡터를 짧은 이진 코드로 압축하도록 자동 인코더를 학습시키면 image label을 사용하지 않기 때문에 효율적으로 만들 수 있다.
'CV' 카테고리의 다른 글
| [2024-1] 김경훈 - MUNIT(Multi-Modal Unsupervised Image-to-Image translation) (0) | 2024.03.26 |
|---|---|
| [2024-1] 백승우 - Denoising Diffusion Probabilistic Models (0) | 2024.03.20 |
| [2023-2] 김경훈 - Mask R-CNN (2) | 2024.02.20 |
| [2023-2] 김경훈 - Finding Tiny Faces (0) | 2024.02.06 |
| [2023-2] 백승우 - AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE (1) | 2024.01.30 |



