
paper link : https://arxiv.org/pdf/1709.07871

CLEVR datset : 다단계 추론의 학습이 필요. 기존 방법의 성능이 좋지않았음.
reasoninng 능력 평가 : CLEVR datset : 다단계 추론의 학습이 필요. 기존 방법의 성능이 좋지않았음.
FiLM (Feature-wise Linear Modulation)
: 조건 입력(질문)에 따라, 신경망 중간 feature에 대해, feature별 변환 수행.
시각적 추론에서, FiLM layer를 추가해서, 질문을 처리하는 RNN이 이미지 처리를 담당하는 CNN의 계산에 영향을 미치게됨.
즉, 질문의 내용에 따라 이미지를 처리하는 방식 자체가 달라짐.
→ Conditional Normalization의 일반화로 볼수있음.

FiLM layer하나가 CNN feature map을 어떻게 바꾸는지.
Fi,c : CNN에서 나온 c번째 feature map.
여기에 감마 곱하고, 베타 더함
→ FiLM 적용 후 feature. 즉, 질문에 따라 값의 분포가 달라진 feature.
Figure 2
- FiLM = feature map에
- 곱하고
- 더하는 단순한 연산

- 왼쪽 : FiLM generator. 질문 처리 부분. 감마,베타를 만든다.
- 질문 하나씩 GRU로 들어가서 질문 요약 벡터가 linear layer을 거쳐서 ResBlock마다 다른 감마 베타가 나온다.
- 가운데 : FiLMed netowrk적용된 후 마지막 classifier가 답을 출력함.
- 이미지 처리 CNN이 FiLM으로 중간중간 조절된다.
- 오른쪽 : ResBlock 내부 구조 ( 아래 → 위 순서 )
- Conv
- ReLU
- Conv
- BatchNorm (BN)
- FiLM
- ReLU
- Skip connection (잔차 연결)
→ 즉, Conv로 feature를 만든 뒤 FiLM이 feature를 질문에 맞게 조절.
Figure 3
즉, 질문으로부터 얻은 정보로,
이미지 처리 네트워크의 중간 feature를 직접 조절해서
복잡한 시각적 추론을 수행.

CLEVR 데이터셋에서 성능이 정말 좋은지
CLEVR는 “문제 난이도가 높은 시각적 추론 데이터셋”
비교 대상 (Baselines)
논문은 다음 방법들과 비교한다:
- Q-type baseline: 질문의 유형(Count/Exist/Compare 등)만 보고, 그 유형에서 가장 흔한 답을 예측(이미지·질문 내용 거의 무시)
- LSTM: 질문 텍스트만 인코딩해서 답 예측(이미지 없음)
- CNN+LSTM: 이미지(CNN)와 질문(LSTM/GRU)를 각각 인코딩한 뒤 concat/MLP로 단순 결합해 답 예측
- Stacked Attention (CNN+LSTM+SA): 이미지 feature map 위에 attention을 여러 번(hops) 반복 적용해서 중요한 위치를 점점 좁힘
- Module Networks (N2NMN, PG+EE): 질문을 바탕으로 추론 모듈/프로그램 구조를 구성해 실행하는 모델
- PG+EE는 보통 program supervision(프로그램 라벨)을 쓰는 설정이 포함됨
- Relation Networks (RN): CNN feature를 object-like feature로 보고, 모든 pair 간 관계 함수를 계산해 합산하여 관계 추론 수행
CLEVR 결과
해석
FiLM은 CLEVR에서 새로운 최고 성능을 달성했으며, 사람과 기존 모든 방법을 능가한다.

FiLM이 내부적으로 뭘 배우는지
Figure 4는 최종 분류기가 사용하는 feature가 이미지의 어느 위치에서 나왔는지를 시각화한 것이다.
- FiLM 모델은:
- 답과 관련된 물체
- 혹은 질문에서 언급된 물체
- 주변의 feature를 사용한다.
- 정답을 틀릴 때는 이 localization이 부정확하다.
설명
- FiLM은 spatial attention을 명시적으로 쓰지 않지만
- feature modulation을 통해
- 결과적으로 공간 선택 효과를 만든다
- 이것이 Stacked Attention보다 훨씬 좋은 이유 중 하나
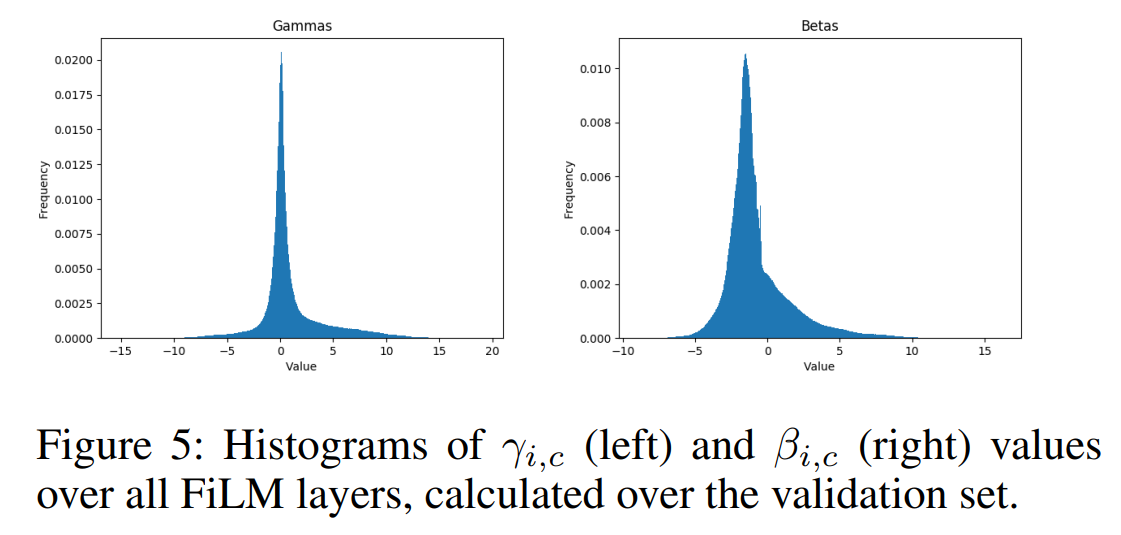
FiLM 파라미터 분포 (Figure 5)
γ, β 히스토그램
해석
γ는 -15~19, β는 -9~16까지 넓은 범위를 사용한다.
γ 값은 0 근처에 큰 피크가 있는데, 이는 많은 feature map이 완전히 꺼진다는 뜻이다.

FiLM 파라미터 t-SNE (Figure 6)
해석
3,000개 validation 질문에 대해
- 각 질문이 만든 (γ, β)를
- t-SNE로 시각화
6-ResBlock 모델을 사용해:
- 앞쪽 FiLM layer.
- 첫 FiLM layer를 비교
- 색, 모양, 크기 같은
- 저수준 추론 기능 기준으로 묶임
- 뒤쪽 FiLM layer
- 마지막 FiLM layer를 비교
- 비교, 동등성, 개수 같은
- 고수준 추론 기능 기준으로 묶임
즉,
FiLM은
명시적인 모듈 설계 없이도
기능별로 분화된 처리 구조를 스스로 학습했다

Figure 7 — Test-time ablation & noise sensitivity (γ vs β)
무엇을 하는 그림인가?
학습이 끝난 best FiLM model에 대해, 테스트할 때 FiLM 파라미터 γ(gamma) 또는 β(beta)를 망가뜨리거나(평균값으로 치환) 노이즈를 넣어서 성능이 얼마나 떨어지는지 보는 실험.
그림의 “수평선(horizontal lines)” 의미
- γ 또는 β를 training set 평균(mean) 값으로 고정해버린 경우를 의미
- 즉, 해당 파라미터가 질문(conditioning) 정보를 못 담게 만드는 ablation
핵심 관찰
- β를 평균으로 바꿔도 accuracy drop이 작음 (~1%)
→ 모델은 β에 덜 의존. - γ를 평균으로 바꾸면 accuracy가 급락 (~65.4% drop)
→ conditioning 정보가 사실상 γ에 주로 실려 있음. - Gaussian noise를 γ/β에 점점 더 넣으면
→ γ에 노이즈를 넣을 때 성능이 훨씬 더 크게 붕괴
→ γ가 더 “민감하고 중요한” conditioning channel이라는 증거.
결론: 실제로 FiLM은 scaling(γ) 을 통해 주로 conditioning을 하고, bias(β)는 상대적으로 덜 중요.

Table 2 — Architectural ablations (CLEVR val accuracy)
무엇을 하는 표인가?
“best architecture”를 기준으로, 특정 구성요소를 바꾸는 architectural ablation을 여러 개 만들어서 CLEVR validation accuracy를 비교.
표에 포함된 정보
- 각 ablation 설정의 val accuracy
- best model은 5 runs 표준편차(standard deviation)도 같이 보고 (즉, 재현성/변동성 포함)
이 표가 말하는 핵심
- hyperparameter tuning 없이도 대부분의 구조 변형이 기존 SOTA보다 높게 나옴
→ FiLM이 특정 설계에 과하게 의존하지 않고 robust하다는 주장 뒷받침. - FiLM placement를 ResBlock 내 여러 위치로 옮겨도 성능이 크게 떨어지지 않음

Table 3 — FiLM model depth (ResBlocks 개수) vs CLEVR val accuracy
무엇을 하는 표인가?
FiLM 모델의 depth (ResBlock 수)를 바꿔가며 validation accuracy가 어떻게 변하는지 비교.
핵심 관찰
- depth가 달라도 전반적으로 성능이 잘 유지됨 → depth에 robust
- 하지만 ResBlock이 1개뿐일 때는 덜 robust(성능 하락이 더 큼)
→ reasoning이 네트워크 파이프라인 전체에서 누적/반복되며 이뤄지는 쪽이 유리하다는 해석을 지지.
또 다른 포인트
- 본문에서 “validation set을 사용했을 때 결과가 statistically significant”라고 언급
→ depth 변화나 ablation의 차이가 우연일 가능성이 낮다는 주장

Figure 8 — CLEVR-Humans 예시 (fine-tuning 전/후의 질적 결과)
무엇을 하는 그림인가?
CLEVR-Humans의 질문은 더 자연스럽고 복잡하며 새로운 단어/개념이 들어오는데, FiLM이 이런 질문에 어떻게 답하는지 사례(example)로 보여줌.
그림이 전달하는 메시지
- 새로운 단어/개념(underlined) 등장: obstruction, superlatives, reflections 같은 요소
- fine-tuning 후: 이런 개념들에 대해 reasoning이 개선됨
- 여전히 어려운 것: hypothetical scenario(가정/상상 기반 질문)는 여전히 struggle
추가로 흥미로운 관찰
- 사람들은 object를 주로 shape 기반으로 지칭하는 경향이 있고, 모델도 그 preference를 학습한 모습이 나타남(왼쪽 예시 설명).
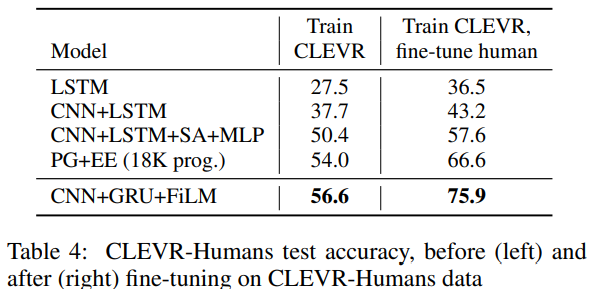
Table 4 — CLEVR-Humans test accuracy (fine-tuning 전/후)
무엇을 하는 표인가?
CLEVR-Humans에서 test accuracy를:
- (left) fine-tuning 전
- (right) fine-tuning 후
로 나눠서 기존 방법들과 비교.
핵심 관찰
- FiLM은 fine-tuning 전에도 strong generalization
- fine-tuning 후에는 더 크게 향상 (특히 다른 모델 대비 향상폭이 큼)
→ data-efficient adaptation을 보여줌 (적은 데이터로도 잘 적응)
비교 포인트 (PG+EE vs FiLM)
- PG+EE는 module inventory에 없는 유형 질문에서 한계가 생길 수 있음
- FiLM은 feature map을 연속적으로 modulate할 수 있어 더 유연
→ fine-tuning 후 FiLM이 PG+EE를 큰 폭으로 앞섰다고 설명.

Figure 9 — CLEVR-CoGenT 결과 (A/B, fine-tuning, sample efficiency, forgetting, zero-shot)
무엇을 하는 그림인가?
CoGenT는 train(A)에서 보지 못한 속성 조합이 test(B)에 나오도록 만들어서, 모델이 “조합을 외우는지” vs “disentangled/general representation을 배우는지” 평가.
표
(1) Train A: A로만 학습했을 때 (zero-shot 성격)
- A 열: A에서의 성능
- B 열: A로 학습한 모델을 B에 바로 테스트했을 때 성능(= 일반화 성능)
여기서 중요한 건 A는 높고 B는 낮다는 패턴이에요 → attribute combination bias가 있다는 뜻.
예) CNN+GRU+FiLM
- Train A에서 A=98.3, B=75.6
- A는 거의 완벽하지만, B(새 조합)에선 확 떨어짐
(2) Fine-tune B: B로 30K 샘플을 추가 학습했을 때
- B 열이 크게 상승: B 적응 성공
- A 열이 떨어짐: forgetting 발생
FiLM은 B에 적은 데이터로도 빠르게 적응하지만(sample-efficient), 그 과정에서 A 성능이 떨어지는 catastrophic forgetting이 발생하며, (γ,β) 선형결합 zero-shot 트릭은 fine-tuning 없이 B 성능을 일부 끌어올릴 수 있다.

Figure 10 — CoGenT zero-shot linear combination의 구체 예시
무엇을 하는 그림인가?
훈련에 없던 조합(예: “blue + cylinder”) 질문의 FiLM 파라미터를 직접 예측하는 대신,
(1) + (2) − (3) 형태로
세 질문의 FiLM 파라미터를 선형결합해서 원 질문의 (γ,β)를 구성하는 예시를 보여줌.
핵심 메시지
- 이런 조작이 의미 있게 작동해서 정답이 교정되는 사례를 보여줌
(예: 답이 “rubber” → “metal”로 수정)
결론적 함의
- FiLM 파라미터 공간은 의미 있게 조작 가능해서, 훈련에 없던 속성 조합도 (γ,β) 선형결합으로 zero-shot 개선이 가능하다

