
https://arxiv.org/abs/2406.01574
MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark
In the age of large-scale language models, benchmarks like the Massive Multitask Language Understanding (MMLU) have been pivotal in pushing the boundaries of what AI can achieve in language comprehension and reasoning across diverse domains. However, as mo
arxiv.org
https://huggingface.co/datasets/TIGER-Lab/MMLU-Pro
TIGER-Lab/MMLU-Pro · Datasets at Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
1. 데이터셋 구성 의의
기존 MMLU는 오랫동안 범용 지식/이해력 평가의 표준처럼 쓰였지만, 모델 성능이 상향 평준화되면서 점수가 상위권에 뭉치고(포화), 프롬프트에 따른 점수 변동도 커서 비교가 애매해지는 문제가 있었습니다. MMLU-Pro는 이 한계를 줄이기 위해 (1) 더 어려운 문제, (2) 더 낮은 ‘찍기’ 확률, (3) 더 안정적인 평가를 목표로 설계되었습니다.
핵심 아이디어는 간단합니다.
- 보기 개수 확장(4지선다 → 10지선다): 우연 정답 가능성을 낮추고 “시험 잘 치는 요령”을 어렵게 만듭니다.
- 난이도/추론 비중 강화 + 노이즈 문항 정제: MMLU의 trivial/noisy 문항을 덜어내고, reasoning 중심 문제를 더 넣습니다.
- 프롬프트 안정성 강화: 24개 프롬프트 스타일로 테스트했을 때 점수 민감도가 MMLU 대비 낮아졌다고 보고합니다.
2. MMLU-Pro 실제 문제 예시
예시 1) 할부 구매 이자율 (Business)
Q. A 5.00 down and $3.10 a month for a year. What is the annual interest rate for this installment purchase?
Options (10개):
14%, 17.5%, 10%, 15%, 19.8%, 20%, 5%, 8%, 12.2%, 25%
정답 라벨: I
예시 2) 만기일 계산 (Business)
Q. A loan is made on December 17 for a time period of 120 days. When is it due (not a leap year)?
Options (10개):
April 15, April 13, April 18, May 15, April 16, April 12, April 17, May 1, March 17, April 14
정답 라벨: E
예시 3) 광고 효과 모델 식별 (Business/Marketing)
Q. This is a hierarchy of effects or sequential model used to explain how advertising works:
Options (10개):
SWOT., SMART., PESTLE., AIDA., STP Model., 5C's Analysis., PORTER., 7P's of Marketing., ADD., BCG Matrix.
3. 데이터셋 관련 통계 (크기/도메인)
공식 설명 기준으로 MMLU-Pro는:
- 총 12,000+ 문항
- 14개 도메인(Biology, Business, Chemistry, CS, Economics, Engineering, Health, History, Law, Math, Philosophy, Physics, Psychology, Others)
로 구성됩니다.

4. 각 모델 간 벤치마크 성적
1) Frontier모델간 성능비교

최신 리더보드에서는 상위권이 88~90%대로 올라와 있고, 1~3위가 Gemini 3 Pro/Flash, Claude Opus로 잡힙니다.
- Google: Pro > Flash 경향(동일 계열에서 Pro가 더 높게 잡히는 패턴)
- 최근 오픈 소스 llm모델들도 많이 따라왔지만, 리더보드 최상위(88~90대)와는 보통 여전히 갭이 남는 편입니다
2) 파라미터 수에 따른 변화
대체로 규모가 커질수록 상승하되, 단조 증가가 깨지는 구간이 존재합니다.

- Llama 계열: 8B < 70B로 올라가며 성능이 크게 오르는 전형적 스케일링이 관찰됩니다.
- Gemma 계열: 작은 모델에서 커지면 오르긴 하지만, reasoning 강한 세팅/문항에서 절대값 한계가 상대적으로 빨리 보입니다.
- Qwen 계열: “파라미터”만으로 설명이 안 되는 사례가 나타납니다.
결론적으로는 “MMLU-Pro에서는 ‘크기’도 중요하지만, 어떤 모델인지에 따라서 성능을 좌우하는 비중이 더 커 보인다.”
3) Resoning model에 따른 성능변화
MMLU-Pro의 가장 큰 특징 중 하나가 CoT(Chain-of-Thought)가 유의미하게 성능을 올리는 경향입니다. 논문은 “기존 MMLU와 달리 MMLU-Pro에서는 CoT가 더 도움이 된다”는 점을 강조합니다
4) 한국모델들에 대한 성능비교

LG AI Research에서 공개한 K-EXAONE에 성능이 그림에서 보이는거와 같이 83.8%정도를 차지하는 것으로 보입니다. 이는 현재 1등 GEMINI PRO(90.5%)와는 성능차이가 많이 나지만 상위권 성적으로 랭크가 되었습니다. 그 다음으로는 SK텔레콤과 업스테이지가 각각 2위(약 80프로), 3위(76프로)를 차지했습니다.
5. 데이터셋 구축 방법론
a. 데이터 출처
: 4개 소스 통합
| Original MMLU | 56.6% | 기존 57 subject → 14개로 재구성, 쉬운/오류 문항 제거 |
| STEM Website | 33.9% | 문제+풀이 형태의 고난도 STEM 문제 |
| TheoremQA | 4.97% | 정리 적용이 필요한 문제 |
| SciBench | 4.5% | 대학 수준 과학 시험 문제 |
b. 구축 파이프라인
- Initial Filtereing
: 쉬운 문제 및 노이즈를 제거하기 위해 8개 LLM으로 MMLU를 평가하여 4개를 초과하는 모델이 정답을 맞춘 문항은 제거하였고 총 5,886개의 문항을 삭제해 기존 MMLU saturation 문제를 완화했다. - Question Integration
: 외부 고난도 문제를 MCQ 형식으로 정렬하기 위해 GPT-4-Turbo로 solution에서 short answer을 추출하고 3개의 distractor를 생성한 후 수동 검증으로 추출 오류를 제거했다. - Option Augmentation
: 문항의 난이도 및 분별력을 강화하기 위해 4지선다를 10지선다로 확장하고 GPT-4-Turbo로 6개의 plausible distractor를 추가해 결론적으로 추측 확률이 감소했다. - 2단계 Expert Review
: 첫번째로 인간이 정답 정확성을 확인하고, MCQ 부적합 문제를 제거하고, 이미지/정보 부족 문항을 제거하도록 했다. 다음 단계로는 False Negative 검증을 위해 Gemeni-1.5-Pro로 재평가를 실시하고 정답으로 오분류된 선택지를 제거, 마지막으로는 인간의 최종 확인을 거쳤다,
➡️ 즉, 논문은 LLM을 이용해 쉬운 문제를 자동으로 제거하고, answer/distractor를 생성하며, false negative를 탐지했다. 또한 최종 단계에서는 반드시 human expert를 거쳐 데이터 품질을 검증했다.
6. 데이터셋 관련 연구
MMLU (Massive Multitask Language Understanding)
- 대표적인 벤치마크로 57개 subject, 객관식 문제로 구성된 대규모 언어 이해 평가 데이터셋
- 기계의 다중작업 일반화 능력을 평가하는 목적
- 지식 기반 질문이 많고 일부 오류/노이즈 문제 존재
➡️ MMLU-Pro는 여기에 기반을 두고, trivial/noisy 문항 제거, reasoning 중심 문제 강화, 보기 수 확장과 같은 확장/개선을 진행함.
GLUE / SuperGLUE
- 일반 자연어 이해(NLU) 성능 평가용 표준 벤치마크
- 다양한 언어 과제를 묶어 multi-task 평가 체계 확립
- 이후 전문화 벤치마크 발전의 기반이 됨
HELM
- LLM을 다각도로 평가하는 holistic evaluation framework
- 단일 점수보다 다양한 평가 축 제시
BigBench
- 복잡한 reasoning 및 다양한 task 평가
- LLM의 광범위 능력 측정 목적
HellaSwag
- 상식적 추론 능력 평가
ARC (AI2 Reasoning Challenge)
- 과학 기반 reasoning 문제 평가
OpenLLM Leaderboard/OpenCompass
- 다양한 모델을 동일 벤치마크로 비교하는 공개 리더보드
- 하지만 상위 모델 점수가 수렴하는 문제 발생 → 모델 간 변별력 감소
7. 데이터셋 평가방법론
- Chain-of-Thought 활용
: 모델 평가 시 질문과 정답만 제시하는 것이 아니라, 단계별 추론 과정이 포함된 5-shot CoT 프롬프트를 기본적으로 사용합니다. 이는 모델이 논리적 단계를 거쳐 문제에 접근하도록 유도하며, 기존 MMLU보다 복잡한 추론이 필요한 문항들을 평가하는 데 적합합니다. - 답변 추출 및 처리 메커니즘
: 모델이 생성한 긴 텍스트에서 정답을 골라내기 위해 정규 표현식을 사용합니다.
1) 먼저 ‘answer is \\(\\?\\([A-J]\\)?\\)’ 패턴으로 답변을 찾고, 실패할 경우 ‘\\.*\\[aA\\]nswer:\\s*\\([A-J]\\)’ 패턴을 적용합니다.
2) 만약 두 방식 모두 실패하여 정답을 특정할 수 없는 경우에는 보기 중 하나를 무작위로 선택하는 대체 메커니즘을 두어 평가의 일관성을 유지합니다. - 프롬프트 Robustness 테스트
: 프롬프트의 미세한 어투나 형식 변화에 점수가 요동치는 문제를 방지하기 위해, 24가지의 다양한 프롬프트 스타일을 사용하여 모델의 성능 변화를 측정합니다. 실험 결과 MMLU-Pro는 기존 MMLU보다 프롬프트 변화에 훨씬 안정적인(변동폭 약 2%) 결과를 보여주었습니다. - 변별력 강화
: 정답을 맞힐 확률을 낮추기 위해 객관식 선택지를 기존 4개에서 10개로 늘렸으며, 이를 통해 무작위로 답을 맞춰 성능이 과대평가되는 것을 방지합니다. - 실험 및 분석 환경
: 50개 이상의 모델을 대상으로 NVIDIA A100 GPU 환경에서 평가를 진행했으며, 추론 속도를 최적화하기 위해 vLLM 기술을 적용했습니다. 또한, 모델의 오류를 9가지 유형(추론 오류, 지식 부족, 계산 실수 등)으로 분류하는 심층 오류 분석을 통해 모델의 약점을 파악하는 방법론을 취하고 있습니다.
8. 논문 실험 소개
- 50개 이상의 모델 성능 평가
: GPT-4o, Claude-3-Opus, Gemini-1.5-Pro와 같은 주요 폐쇄형 모델부터 Llama-3, Phi-3, Qwen 등 다양한 오픈소스 모델까지 50개 이상의 LLM을 대상으로 성능을 측정했습니다. 실험 결과, GPT-4o가 72.6%의 정확도로 전체 모델 중 1위를 차지했으며, 전반적으로 상위권 폐쇄형 모델들이 오픈소스 모델들보다 우수한 성능을 보였습니다.
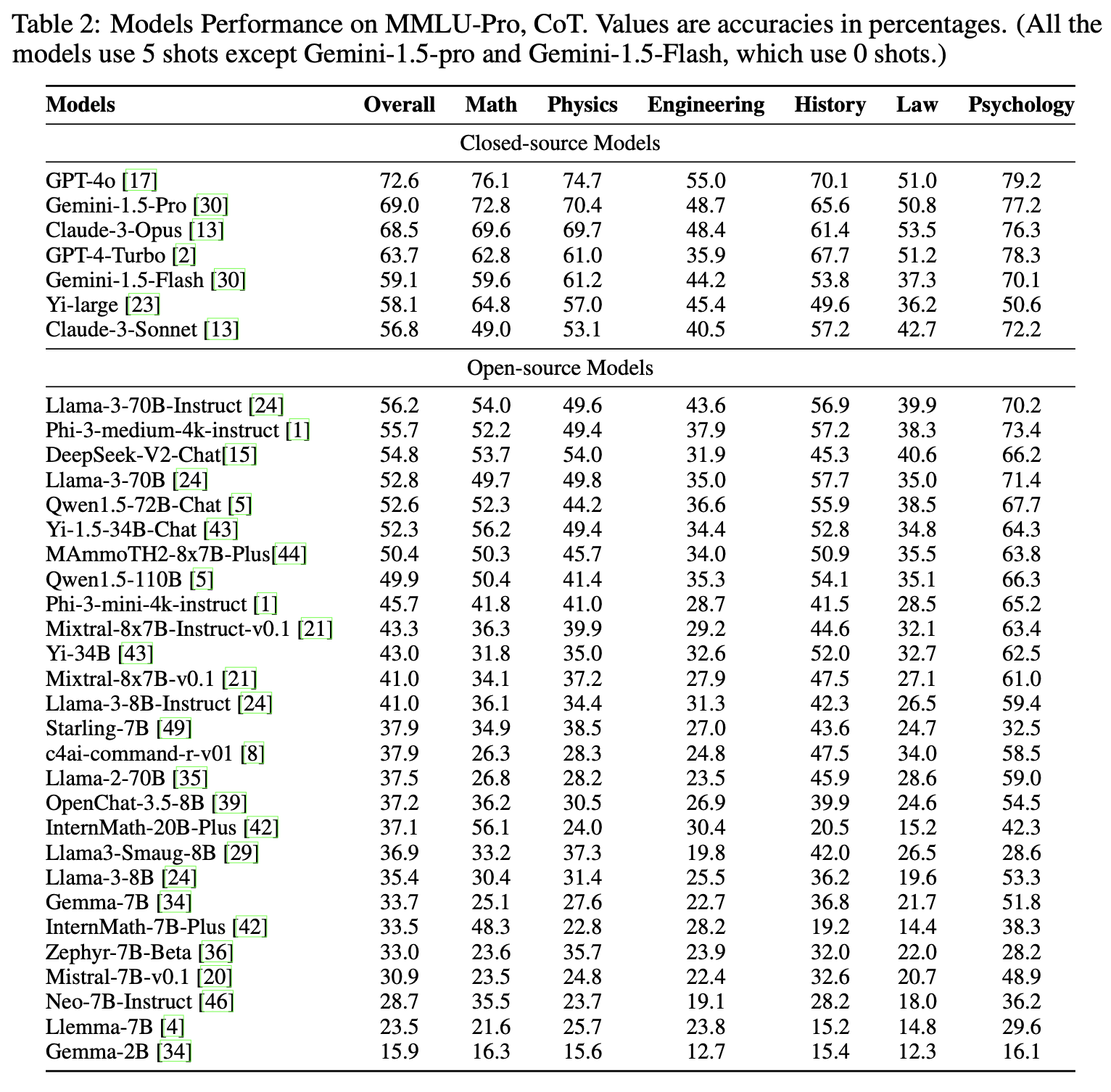
- 추론 방식에 따른 성능 비교 (CoT vs. Direct Answer)
: 모델이 즉각적으로 답을 내는 방식과 Chain-of-Thought 기법을 사용하여 단계별로 추론하게 하는 방식의 성능 차이를 분석했습니다. 실험 결과, 지식 중심이었던 기존 MMLU와 달리 추론 중심인 MMLU-Pro에서는 CoT를 사용할 때 모델들의 성능이 향상(GPT-4o의 경우 19.1% 상승)되는 것을 확인했습니다. - 프롬프트 변동에 대한 견고성 테스트
: 동일한 문제라도 프롬프트의 어조나 형식에 따라 점수가 달라지는 문제를 확인하기 위해 24가지의 서로 다른 프롬프트 스타일로 실험을 진행했습니다. 실험을 통해 MMLU-Pro는 기존 MMLU(4~5% 변동)에 비해 프롬프트 변화에 따른 점수 변동폭이 약 2%로 낮아져 훨씬 더 안정적인 평가가 가능함을 입증했습니다. - 심층 오류 분석
: 최고 성능 모델인 GPT-4o가 틀린 120개의 사례를 무작위로 추출하여 전문가들이 원인을 분석했습니다. 분석 결과, 전체 오류 중 39%가 논리적 추론 오류, 35%가 특정 분야의 지식 부족, 12%가 단순 계산 실수로 나타나 모델들이 여전히 복잡한 문제 해결에서 한계를 보임을 드러냈습니다.

- MMLU와의 변별력 비교
: 기존 MMLU와 MMLU-Pro에서 모델 간의 점수 차이를 비교했습니다. MMLU에서는 최상위 모델들의 점수가 1~2% 차이 내에 밀집되어 변별력이 떨어졌으나, MMLU-Pro에서는 모델 간 점수 격차가 약 9% 이상 벌어지며 성능 차이를 더 명확히 구분해냈습니다
9. 논문에서 언급한 한계점
- 객관식 형식의 제약
: MMLU-Pro는 질문의 난이도를 높이고 추론 중심의 문항을 강화했음에도 불구하고, 여전히 객관식 형식이라는 근본적인 틀 안에 갇혀 있습니다. 이러한 형식은 실제 세계의 시나리오를 더 잘 반영하는 주관식 혹은 Open-ended 답변만큼 모델의 이해 깊이나 창의적인 응답 생성 능력을 효과적으로 포착하지 못할 수 있다는 한계가 있습니다. - 언어 모델로의 한정
: 이 벤치마크는 언어 모델 평가에만 집중하고 있습니다. 따라서 시각, 청각, 텍스트 데이터의 통합적 합성이 필요한 멀티모달 모델을 평가하는 데에는 적용하기 어렵다는 한계가 있습니다. - 데이터셋 노이즈 및 주석 오류
: 전문가 검토 과정을 통해 노이즈를 줄였으나, 여전히 일부 문항에서 오류가 있는 주석이 발견되기도 합니다. GPT-4o의 오류 분석 결과에 따르면, 전체 오류 중 약 2%는 정답 자체가 잘못된 데이터셋 자체의 문제인 것으로 나타났습니다. - 추론 과정의 복잡성으로 인한 모델의 한계
: 벤치마크 자체의 한계라기보다 모델의 한계이지만, 논문은 모델들이 여전히 논리적 추론(39%)이나 특정 도메인 지식의 부족(35%)으로 인해 고전하고 있음을 보여주었습니다. 이는 현재의 최상위 모델들에게도 MMLU-Pro가 여전히 매우 도전적인 과제임을 시사합니다.