
A-MEM: Agentic Memory for LLM Agents
While large language model (LLM) agents can effectively use external tools for complex real-world tasks, they require memory systems to leverage historical experiences. Current memory systems enable basic storage and retrieval but lack sophisticated memory
arxiv.org
1. Introduction
- LLM agent의 발전으로, 환경과 상호작용하고 작업을 실행하며 의사결정을 할 수 있게됨
- Reasoning과 planning 능력을 향상시키기 위해 LLM을 외부의 도구 및 워크플로우와 통합
- 외부 환경과 상호작용하기 위해 메모리가 필요함
- Basic Memory:
- Agent 개발자가 메모리 스토리지 구조를 미리 정의하고, 워크플로우 내에서 스토리지 지점을 지정하고, 검색 타이밍을 설정
- Graph Database:
- 데이터 간의 관계를 노드와 엣지(연결)를 사용해 그래프 구조로 저장하는 시스템으로, Mem0와 같이 메모리 시스템의 구조화를 위해 그래프 데이터베이스가 활용
- 그러나 미리 정의된 스키마(데이터 모델)와 관계에 의존한다(저장 시점에 어떤 노드와 관계가 존재할지를 미리 결정)
- 새로운 정보나 예측하지 못한 지식이 등장했을 때(예: 새로운 수학적 해결책 학습) 이를 기존의 틀 내에서만 분류하고 연결할 수밖에 없게 되어, 혁신적인 연결이나 새로운 조직 패턴을 형성하는 데 제약이 따름
- LLM agent가 지속적으로 발전하는 지식 체계에 맞춰 적응하고 일반화하는 데 한계가 있음
- A-MEM:
- 정해진 메모리 조작 방식 없이 새로운 메모리를 동적으로 생성하고 관리
- Zettelkasten의 원칙을 기반으로, atomic note(여러 정보들로 구성)과 연결 메커니즘을 통해 정보를 조직
- 각 메모리는 텍스트 속성과 임베딩 벡터 등 다양한 표현을 포함하여 구성되며, 이를 통해 유사성 매칭과 의미 있는 연결
- 새로운 경험이 추가되면 기존 메모리의 문맥 표현이 자동으로 업데이트되어, 전체 메모리 체계가 지속적으로 발전
- Long-term conversation 데이터셋을 활용한 실험에서, 여섯 개의 기본 모델과 다양한 평가 지표를 통해 A-MEM의 성능 개선이 입증됨
- T-SNE 시각화를 통해 agentic memory system의 structured organization이 확인됨

2. Related Work
Memory for LLM Agents
- 이전 연구들은 LLM agent가 interaction 기록을 저장하고 활용하는 다양한 메모리 관리 메커니즘
- 예를 들어, 전체 interaction을 dense retrieval models이나 read-write memory structures로 저장하거나, MemGPT(캐시 기반 아키텍처)와 SCM(Self-Controlled Memory)을 통해 최근 정보를 우선 처리하는 방식들이 존재
- 하지만 사전에 정해진 구조와 고정된 워크플로우에 의존하여 새로운 환경에 대한 일반화와 장기 상호작용에서는 유연성이 떨어짐
Retrieval-Augmented Generation
- RAG는 문서를 청크 단위로 나누고, 의미 기반 유사도 검색을 통해 관련 정보를 추출하여 LLM의 생성 과정에 통합함으로써 외부 지식 활용을 극대화
- 최신 연구에서는 자율적으로 검색 시점과 검색 대상을 결정하고, 반복적으로 검색 전략을 개선하는 agentic RAG 시스템이 등장했지만, 이들은 주로 검색 단계에서 자율성을 보임
- 반면, A-MEM은 저장 및 진화 단계에서 메모리 구조 자체가 자율적으로 업데이트되고 연결되도록 함으로써 메모리 단계의 자율성을 제공
3. Methodolodgy

Note Construction
- 에이전트의 상호작용 정보를 atomic note로 기록
- 각 atmoic note는 상호작용 내용, 타임스탬프, LLM이 생성한 키워드, 태그, 문맥 설명, 그리고 임베딩 벡터를 포함
- mᵢ: 각 메모리 노트를 나타내며, 하나의 상호작용 기록을 의미
- cᵢ: 원본 상호작용 내용 (예: 대화 내용이나 이벤트의 상세 기록)
- tᵢ: 해당 상호작용의 타임스탬프, 기록이 생성된 시각
- Kᵢ: LLM이 생성한 키워드 집합으로, 해당 상호작용의 핵심 개념들을 추출
- Gᵢ: LLM이 생성한 태그 집합으로, 메모를 분류하거나 카테고리화하는 데 사용됨
- Xᵢ: LLM이 생성한 문맥적 설명(컨텍스트 설명)으로, 메모의 의미를 풍부하게 해석하기 위한 추가 정보
- eᵢ: 위의 구성요소들(cᵢ, Kᵢ, Gᵢ, Xᵢ)을 결합한 후, 텍스트 인코더 $f_{enc}$를 통해 계산된 밀집 벡터(embedding)로, 이 벡터는 유사도 계산에 사용됨
- Lᵢ: 해당 메모리 노트와 연결된 다른 메모리 노트들의 집합, 즉, 노트 간의 관계(링크)를 저장
- $f_{enc}$: 텍스트 인코더 함수로, 입력된 텍스트(cᵢ, Kᵢ, Gᵢ, Xᵢ의 결합)를 받아서 밀집 벡터 eᵢ로 변환
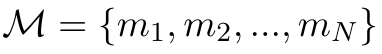


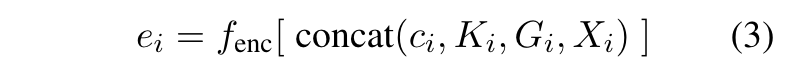
Link Generation
- 새로운 노트가 추가되면, 해당 노트의 임베딩을 이용해 기존 노트들과의 유사도를 계산하고, 가장 관련성 높은 노트 $M^{n}_{near}$를 선별
- 이를 바탕으로 LLM이 노트들 사이의 의미 있는 연결을 자율적으로 생성하여, 동적으로 네트워크를 형성
- 생성된 연결 $l_i$: $L_i = {m_i,...,m_k}$



Memory Evolution
- 새로운 경험이 반영될 때마다, 기존 노트의 문맥, 키워드, 태그 등이 업데이트되어, 지속적으로 지식 구조 $ m^{*}_{j}$를 심화하고 개선
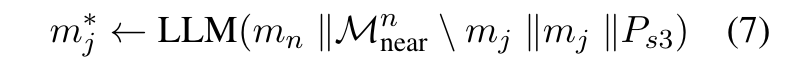
Retrieve Relative Memory
- 현재 상호작용과 관련된 정보를 효율적으로 제공하기 위해, 쿼리 임베딩 $e_q$과 모든 노트 $e_i$의 임베딩 간 유사도 $s_{q, i}$를 계산하여 상위 k개의 관련 기억 $M_{retrieved}$을 검색



4. Experiment
- LoCoMo Dataset: Long-term conversation으로, 장기적인 interaction 상황 평가 가능
- A-MEM은 특히 Multi-Hop(다단계 추론)과 같이 복잡한 task에서 기존 시스템보다 두 배 이상의 성능 향상을 보여줌
- A-MEM은 낮은 토큰 길이 요구사항과 효율적인 메모리 검색 메커니즘을 유지하면서도, 보다 정교한 문맥 연결 능력을 보임

- Link generation과 memory evolution의 기여도를 평가하기 위해, 각 모듈을 제거한 변형 모델과 전체 모델을 비교
- 두 모듈이 모두 제거되면 성능이 크게 저하되며, 특히 multi-hop과 open domain task에서 중요한 역할을 함

- 메모리 검색 시 선택하는 k 값(검색할 메모리 수)에 따른 성능 변화를 분석
- k 값이 증가하면 초기에 성능이 향상되지만, 일정 수준 이후에는 노이즈가 증가하여 성능 향상이 둔화되는 경향이 관찰됨

- t-SNE 시각화를 통해, A-MEM이 생성한 메모리 임베딩이 보다 일관된 클러스터를 형성함을 확인
- 이는 A-MEM의 dynamic evolution과 link generation 메커니즘이 메모리 구조를 효과적으로 조직하고 있음을 시각적으로 증명

5. Limitation
- LLM의 능력에 영향을 크게 받음
- 멀티모달성이 부족함


